 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Intent-Based Filtering for Multi-Party Conversations Using Knowledge Distillation from LLMs
Mar 21, 2025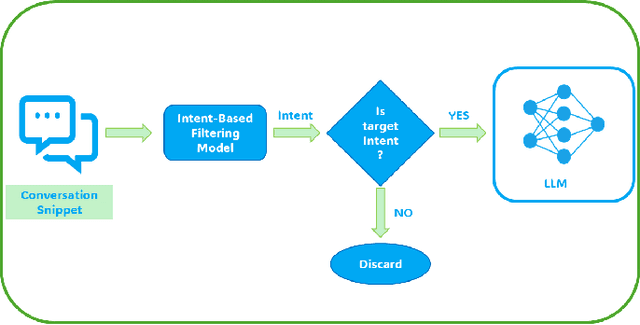
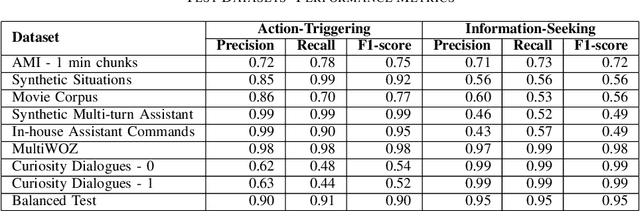
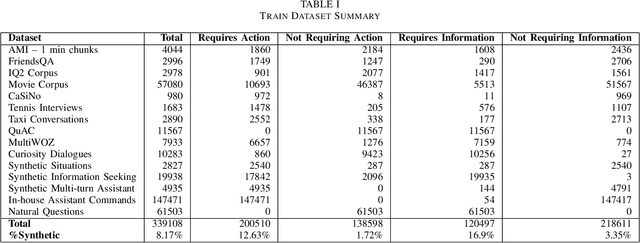

Large language models (LLMs) have showcased remarkable capabilities in conversational AI, enabling open-domain responses in chat-bots, as well as advanced processing of conversations like summarization, intent classification, and insights generation. However, these models are resource-intensive, demanding substantial memory and computational power. To address this, we propose a cost-effective solution that filters conversational snippets of interest for LLM processing, tailored to the target downstream application, rather than processing every snippet. In this work, we introduce an innovative approach that leverages knowledge distillation from LLMs to develop an intent-based filter for multi-party conversations, optimized for compute power constrained environments. Our method combines different strategies to create a diverse multi-party conversational dataset, that is annotated with the target intents and is then used to fine-tune the MobileBERT model for multi-label intent classification. This model achieves a balance between efficiency and performance, effectively filtering conversation snippets based on their intents. By passing only the relevant snippets to the LLM for further processing, our approach significantly reduces overall operational costs depending on the intents and the data distribution as demonstrated in our experiments.
CuisineNet: Food Attributes Classification using Multi-scale Convolution Network
Jun 08, 2018
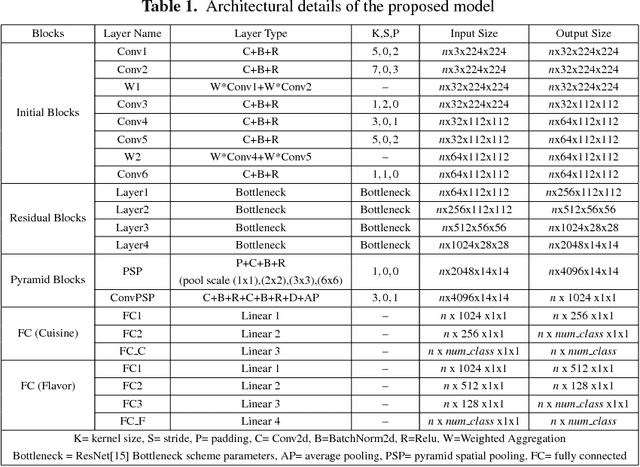
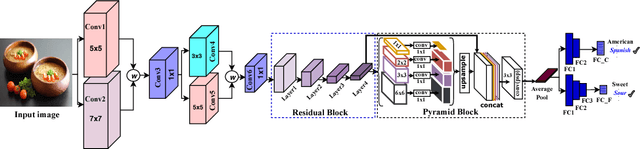
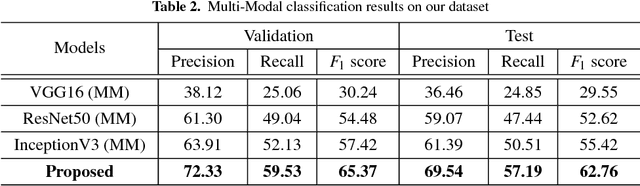
Diversity of food and its attributes represents the culinary habits of peoples from different countries. Thus, this paper addresses the problem of identifying food culture of people around the world and its flavor by classifying two main food attributes, cuisine and flavor. A deep learning model based on multi-scale convotuional networks is proposed for extracting more accurate features from input images. The aggregation of multi-scale convolution layers with different kernel size is also used for weighting the features results from different scales. In addition, a joint loss function based on Negative Log Likelihood (NLL) is used to fit the model probability to multi labeled classes for multi-modal classification task. Furthermore, this work provides a new dataset for food attributes, so-called Yummly48K, extracted from the popular food website, Yummly. Our model is assessed on the constructed Yummly48K dataset. The experimental results show that our proposed method yields 65% and 62% average F1 score on validation and test set which outperforming the state-of-the-art models.
EiTAKA at SemEval-2018 Task 1: An Ensemble of N-Channels ConvNet and XGboost Regressors for Emotion Analysis of Tweets
Feb 26, 2018



This paper describes our system that has been used in Task1 Affect in Tweets. We combine two different approaches. The first one called N-Stream ConvNets, which is a deep learning approach where the second one is XGboost regresseor based on a set of embedding and lexicons based features. Our system was evaluated on the testing sets of the tasks outperforming all other approaches for the Arabic version of valence intensity regression task and valence ordinal classification task.