 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM-TabNet: A Multi-Encoder Transformer Model for Predicting Neonatal Birth Weight from Multimodal Data
Apr 20, 2025

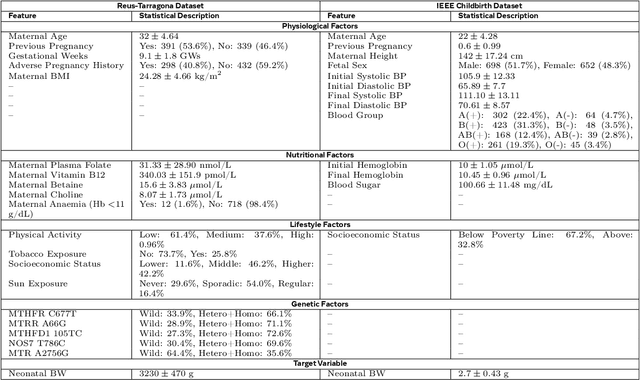

Birth weight (BW) is a key indicator of neonatal health, with low birth weight (LBW) linked to increased mortality and morbidity. Early prediction of BW enables timely interventions; however, current methods like ultrasonography have limitations, including reduced accuracy before 20 weeks and operator dependent variability. Existing models often neglect nutritional and genetic influences, focusing mainly on physiological and lifestyle factors. This study presents an attention-based transformer model with a multi-encoder architecture for early (less than 12 weeks of gestation) BW prediction. Our model effectively integrates diverse maternal data such as physiological, lifestyle, nutritional, and genetic, addressing limitations seen in prior attention-based models such as TabNet. The model achieves a Mean Absolute Error (MAE) of 122 grams and an R-squared value of 0.94, demonstrating high predictive accuracy and interoperability with our in-house private dataset. Independent validation confirms generalizability (MAE: 105 grams, R-squared: 0.95) with the IEEE children dataset. To enhance clinical utility, predicted BW is classified into low and normal categories, achieving a sensitivity of 97.55% and a specificity of 94.48%, facilitating early risk stratification. Model interpretability is reinforced through feature importance and SHAP analyses, highlighting significant influences of maternal age, tobacco exposure, and vitamin B12 status, with genetic factors playing a secondary role. Our results emphasize the potential of advanced deep-learning models to improve early BW prediction, offering clinicians a robust, interpretable, and personalized tool for identifying pregnancies at risk and optimizing neonatal outcomes.
FGR-Net:Interpretable fundus imagegradeability classification based on deepreconstruction learning
Sep 16, 2024
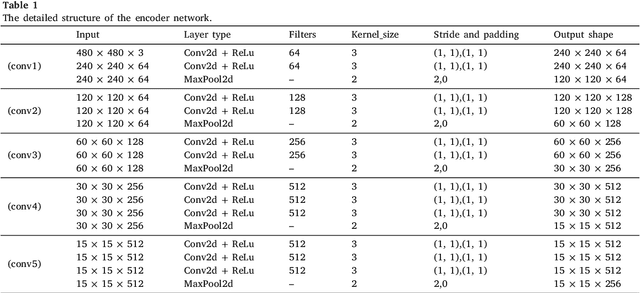
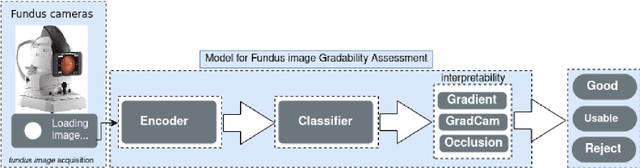
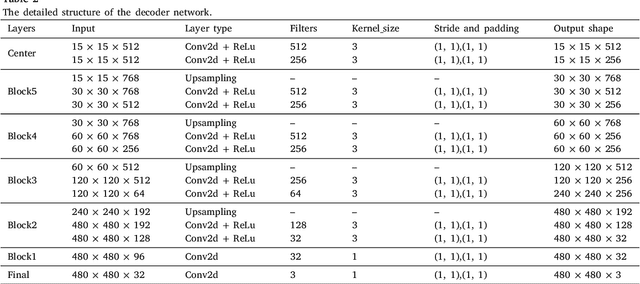
The performance of diagnostic Computer-Aided Design (CAD) systems for retinal diseases depends on the quality of the retinal images being screened. Thus, many studies have been developed to evaluate and assess the quality of such retinal images. However, most of them did not investigate the relationship between the accuracy of the developed models and the quality of the visualization of interpretability methods for distinguishing between gradable and non-gradable retinal images. Consequently, this paper presents a novel framework called FGR-Net to automatically assess and interpret underlying fundus image quality by merging an autoencoder network with a classifier network. The FGR-Net model also provides an interpretable quality assessment through visualizations. In particular, FGR-Net uses a deep autoencoder to reconstruct the input image in order to extract the visual characteristics of the input fundus images based on self-supervised learning. The extracted features by the autoencoder are then fed into a deep classifier network to distinguish between gradable and ungradable fundus images. FGR-Net is evaluated with different interpretability methods, which indicates that the autoencoder is a key factor in forcing the classifier to focus on the relevant structures of the fundus images, such as the fovea, optic disk, and prominent blood vessels. Additionally, the interpretability methods can provide visual feedback for ophthalmologists to understand how our model evaluates the quality of fundus images. The experimental results showed the superiority of FGR-Net over the state-of-the-art quality assessment methods, with an accuracy of 89% and an F1-score of 87%.
Adaptive Affinity-Based Generalization For MRI Imaging Segmentation Across Resource-Limited Settings
Apr 03, 2024The joint utilization of diverse data sources for medical imaging segmentation has emerged as a crucial area of research, aiming to address challenges such as data heterogeneity, domain shift, and data quality discrepancies. Integrating information from multiple data domains has shown promise in improving model generalizability and adaptability. However, this approach often demands substantial computational resources, hindering its practicality. In response, knowledge distillation (KD) has garnered attention as a solution. KD involves training light-weight models to emulate the behavior of more resource-intensive models, thereby mitigating the computational burden while maintaining performance. This paper addresses the pressing need to develop a lightweight and generalizable model for medical imaging segmentation that can effectively handle data integration challenges. Our proposed approach introduces a novel relation-based knowledge framework by seamlessly combining adaptive affinity-based and kernel-based distillation through a gram matrix that can capture the style representation across features. This methodology empowers the student model to accurately replicate the feature representations of the teacher model, facilitating robust performance even in the face of domain shift and data heterogeneity. To validate our innovative approach, we conducted experiments on publicly available multi-source prostate MRI data. The results demonstrate a significant enhancement in segmentation performance using lightweight networks. Notably, our method achieves this improvement while reducing both inference time and storage usage, rendering it a practical and efficient solution for real-time medical imaging segmentation.
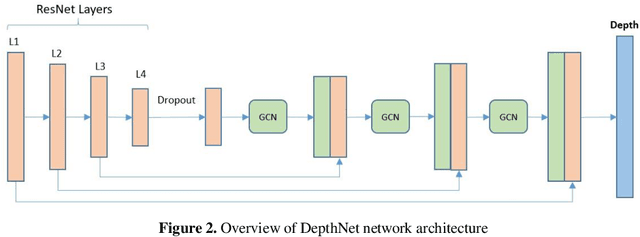
GCNDepth: Self-supervised Monocular Depth Estimation based on Graph Convolutional Network
Dec 13, 2021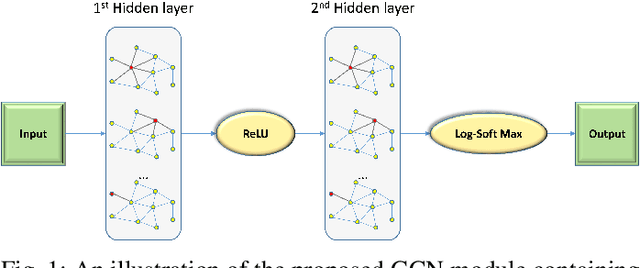
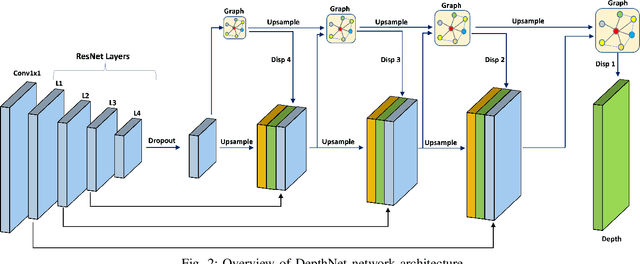
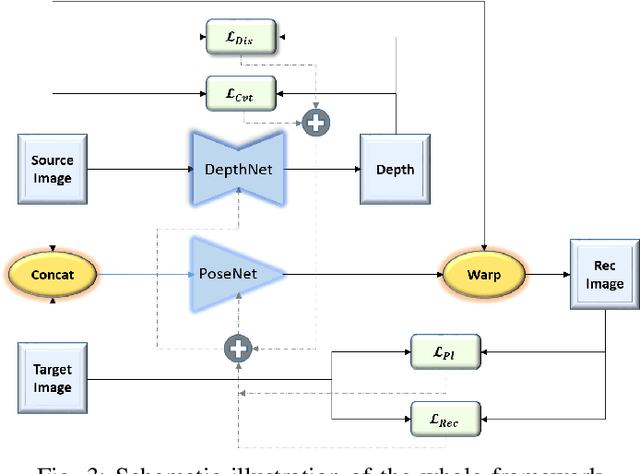
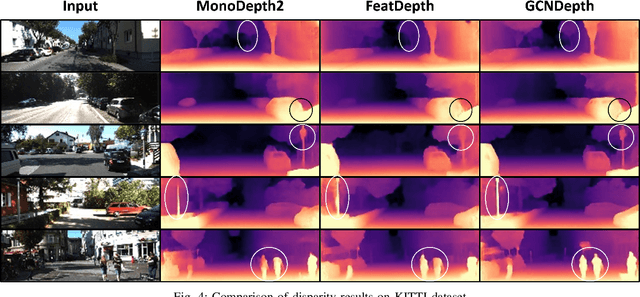
Depth estimation is a challenging task of 3D reconstruction to enhance the accuracy sensing of environment awareness. This work brings a new solution with a set of improvements, which increase the quantitative and qualitative understanding of depth maps compared to existing methods. Recently, a convolutional neural network (CNN) has demonstrated its extraordinary ability in estimating depth maps from monocular videos. However, traditional CNN does not support topological structure and they can work only on regular image regions with determined size and weights. On the other hand, graph convolutional networks (GCN) can handle the convolution on non-Euclidean data and it can be applied to irregular image regions within a topological structure. Therefore, in this work in order to preserve object geometric appearances and distributions, we aim at exploiting GCN for a self-supervised depth estimation model. Our model consists of two parallel auto-encoder networks: the first is an auto-encoder that will depend on ResNet-50 and extract the feature from the input image and on multi-scale GCN to estimate the depth map. In turn, the second network will be used to estimate the ego-motion vector (i.e., 3D pose) between two consecutive frames based on ResNet-18. Both the estimated 3D pose and depth map will be used for constructing a target image. A combination of loss functions related to photometric, projection, and smoothness is used to cope with bad depth prediction and preserve the discontinuities of the objects. In particular, our method provided comparable and promising results with a high prediction accuracy of 89% on the publicly KITTI and Make3D datasets along with a reduction of 40% in the number of trainable parameters compared to the state of the art solutions. The source code is publicly available at https://github.com/ArminMasoumian/GCNDepth.git
Designing and Analyzing the PID and Fuzzy Control System for an Inverted Pendulum
Nov 09, 2021


The inverted pendulum is a non-linear unbalanced system that needs to be controlled using motors to achieve stability and equilibrium. The inverted pendulum is constructed with Lego and using the Lego Mindstorm NXT, which is a programmable robot capable of completing many different functions. In this paper, an initial design of the inverted pendulum is proposed and the performance of different sensors, which are compatible with the Lego Mindstorm NXT was studied. Furthermore, the ability of computer vision to achieve the stability required to maintain the system is also investigated. The inverted pendulum is a conventional cart that can be controlled using a Fuzzy Logic controller that produces a self-tuning PID control for the cart to move on. The fuzzy logic and PID are simulated in MATLAB and Simulink, and the program for the robot is developed in the LabVIEW software.
Using The Feedback of Dynamic Active-Pixel Vision Sensor to Prevent Slip in Real Time
Nov 09, 2021
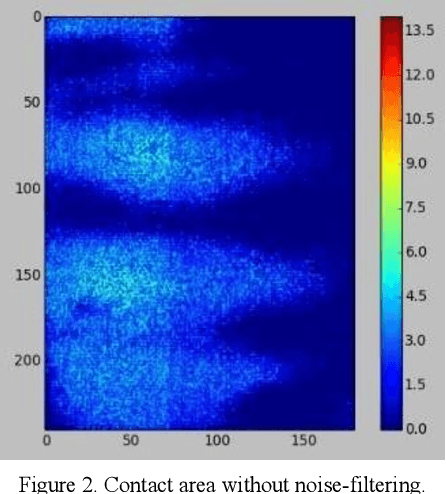
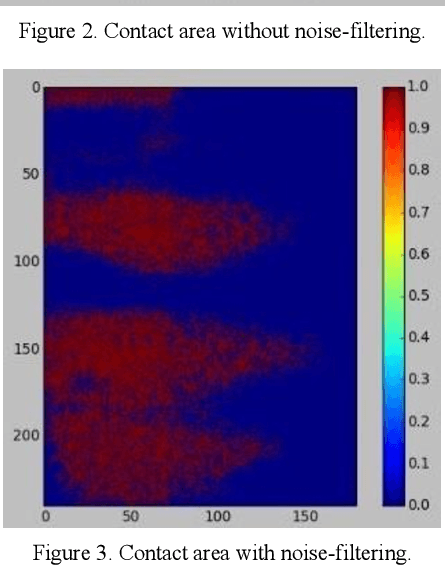
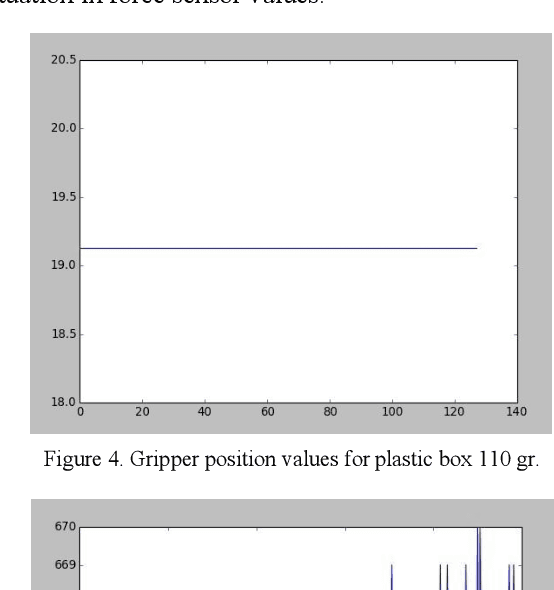
The objective of this paper is to describe an approach to detect the slip and contact force in real-time feedback. In this novel approach, the DAVIS camera is used as a vision tactile sensor due to its fast process speed and high resolution. Two hundred experiments were performed on four objects with different shapes, sizes, weights, and materials to compare the accuracy and response of the Baxter robot grippers to avoid slipping. The advanced approach is validated by using a force-sensitive resistor (FSR402). The events captured with the DAVIS camera are processed with specific algorithms to provide feedback to the Baxter robot aiding it to detect the slip.
Absolute distance prediction based on deep learning object detection and monocular depth estimation models
Nov 02, 2021
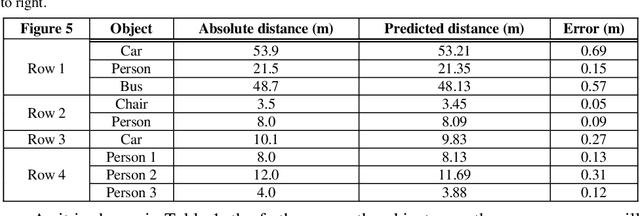
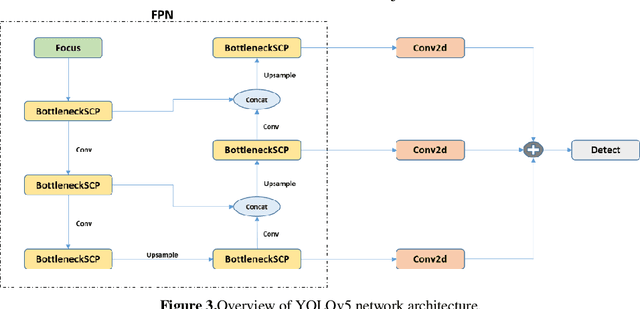
Determining the distance between the objects in a scene and the camera sensor from 2D images is feasible by estimating depth images using stereo cameras or 3D cameras. The outcome of depth estimation is relative distances that can be used to calculate absolute distances to be applicable in reality. However, distance estimation is very challenging using 2D monocular cameras. This paper presents a deep learning framework that consists of two deep networks for depth estimation and object detection using a single image. Firstly, objects in the scene are detected and localized using the You Only Look Once (YOLOv5) network. In parallel, the estimated depth image is computed using a deep autoencoder network to detect the relative distances. The proposed object detection based YOLO was trained using a supervised learning technique, in turn, the network of depth estimation was self-supervised training. The presented distance estimation framework was evaluated on real images of outdoor scenes. The achieved results show that the proposed framework is promising and it yields an accuracy of 96% with RMSE of 0.203 of the correct absolute distance.
Adversarial Learning with Multiscale Features and Kernel Factorization for Retinal Blood Vessel Segmentation
Jul 05, 2019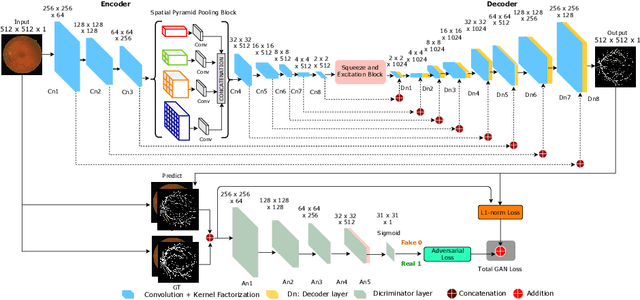
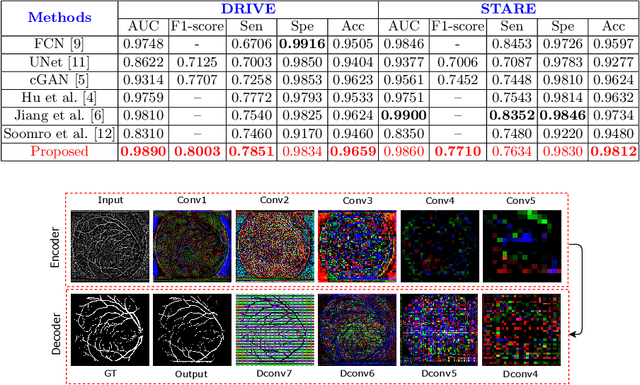
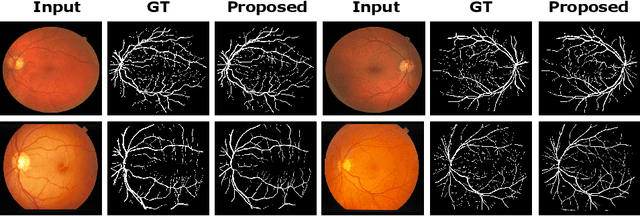
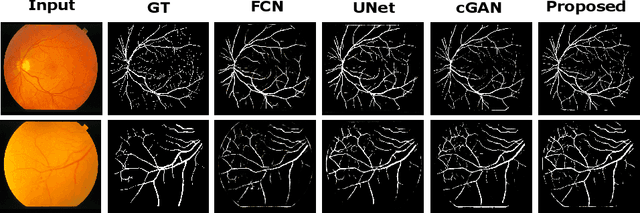
In this paper, we propose an efficient blood vessel segmentation method for the eye fundus images using adversarial learning with multiscale features and kernel factorization. In the generator network of the adversarial framework, spatial pyramid pooling, kernel factorization and squeeze excitation block are employed to enhance the feature representation in spatial domain on different scales with reduced computational complexity. In turn, the discriminator network of the adversarial framework is formulated by combining convolutional layers with an additional squeeze excitation block to differentiate the generated segmentation mask from its respective ground truth. Before feeding the images to the network, we pre-processed them by using edge sharpening and Gaussian regularization to reach an optimized solution for vessel segmentation. The output of the trained model is post-processed using morphological operations to remove the small speckles of noise. The proposed method qualitatively and quantitatively outperforms state-of-the-art vessel segmentation methods using DRIVE and STARE datasets.
An Efficient Solution for Breast Tumor Segmentation and Classification in Ultrasound Images Using Deep Adversarial Learning
Jul 01, 2019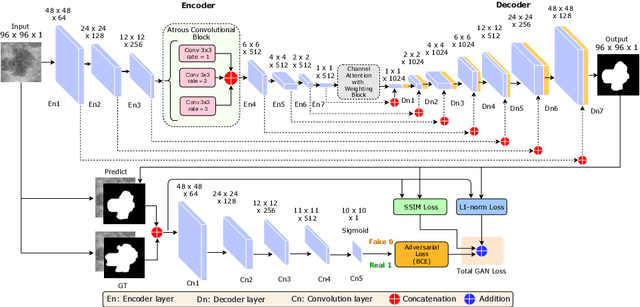
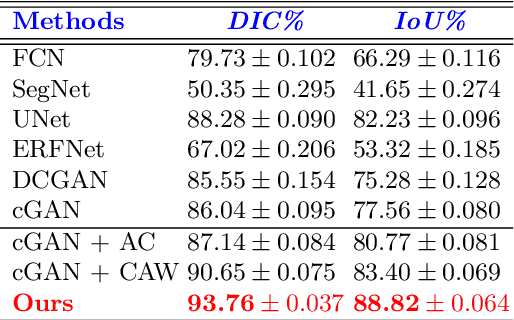
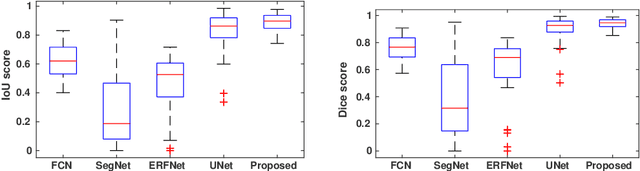

This paper proposes an efficient solution for tumor segmentation and classification in breast ultrasound (BUS) images. We propose to add an atrous convolution layer to the conditional generative adversarial network (cGAN) segmentation model to learn tumor features at different resolutions of BUS images. To automatically re-balance the relative impact of each of the highest level encoded features, we also propose to add a channel-wise weighting block in the network. In addition, the SSIM and L1-norm loss with the typical adversarial loss are used as a loss function to train the model. Our model outperforms the state-of-the-art segmentation models in terms of the Dice and IoU metrics, achieving top scores of 93.76% and 88.82%, respectively. In the classification stage, we show that few statistics features extracted from the shape of the boundaries of the predicted masks can properly discriminate between benign and malignant tumors with an accuracy of 85%$
MobileGAN: Skin Lesion Segmentation Using a Lightweight Generative Adversarial Network
Jul 01, 2019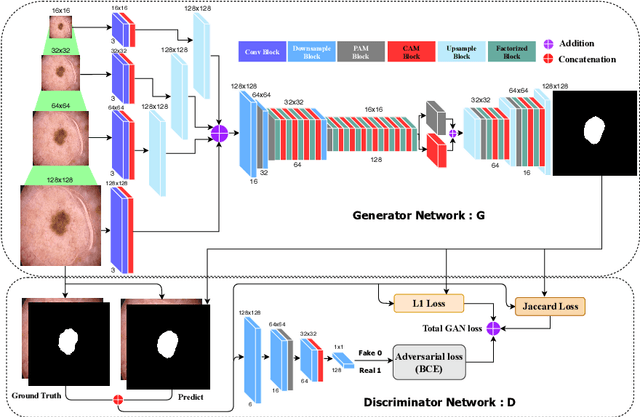
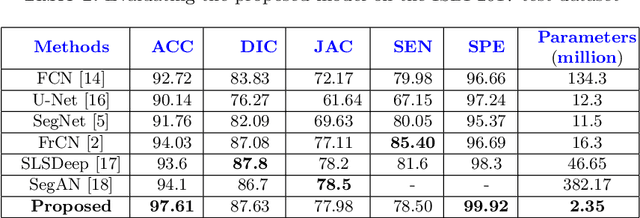
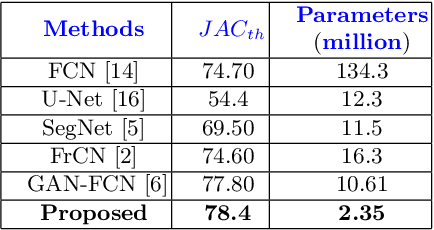
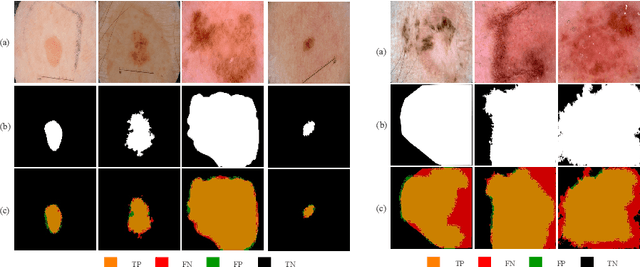
Skin lesion segmentation in dermoscopic images is a challenge due to their blurry and irregular boundaries. Most of the segmentation approaches based on deep learning are time and memory consuming due to the hundreds of millions of parameters. Consequently, it is difficult to apply them to real dermatoscope devices with limited GPU and memory resources. In this paper, we propose a lightweight and efficient Generative Adversarial Networks (GAN) model, called MobileGAN for skin lesion segmentation. More precisely, the MobileGAN combines 1D non-bottleneck factorization networks with position and channel attention modules in a GAN model. The proposed model is evaluated on the test dataset of the ISBI 2017 challenges and the validation dataset of ISIC 2018 challenges. Although the proposed network has only 2.35 millions of parameters, it is still comparable with the state-of-the-art. The experimental results show that our MobileGAN obtains comparable performance with an accuracy of 97.61%.