 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSignAttention: On the Interpretability of Transformer Models for Sign Language Translation
Oct 18, 2024This paper presents the first comprehensive interpretability analysis of a Transformer-based Sign Language Translation (SLT) model, focusing on the translation from video-based Greek Sign Language to glosses and text. Leveraging the Greek Sign Language Dataset, we examine the attention mechanisms within the model to understand how it processes and aligns visual input with sequential glosses. Our analysis reveals that the model pays attention to clusters of frames rather than individual ones, with a diagonal alignment pattern emerging between poses and glosses, which becomes less distinct as the number of glosses increases. We also explore the relative contributions of cross-attention and self-attention at each decoding step, finding that the model initially relies on video frames but shifts its focus to previously predicted tokens as the translation progresses. This work contributes to a deeper understanding of SLT models, paving the way for the development of more transparent and reliable translation systems essential for real-world applications.
FGR-Net:Interpretable fundus imagegradeability classification based on deepreconstruction learning
Sep 16, 2024
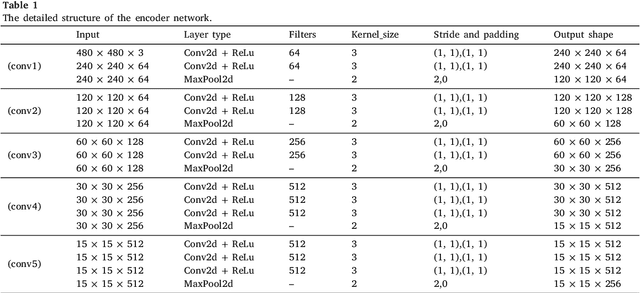
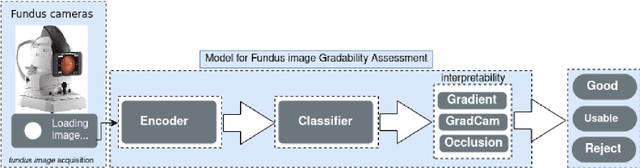
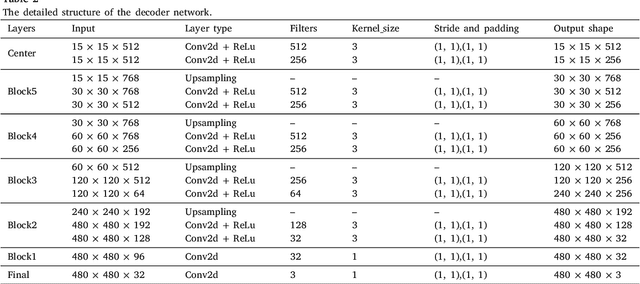
The performance of diagnostic Computer-Aided Design (CAD) systems for retinal diseases depends on the quality of the retinal images being screened. Thus, many studies have been developed to evaluate and assess the quality of such retinal images. However, most of them did not investigate the relationship between the accuracy of the developed models and the quality of the visualization of interpretability methods for distinguishing between gradable and non-gradable retinal images. Consequently, this paper presents a novel framework called FGR-Net to automatically assess and interpret underlying fundus image quality by merging an autoencoder network with a classifier network. The FGR-Net model also provides an interpretable quality assessment through visualizations. In particular, FGR-Net uses a deep autoencoder to reconstruct the input image in order to extract the visual characteristics of the input fundus images based on self-supervised learning. The extracted features by the autoencoder are then fed into a deep classifier network to distinguish between gradable and ungradable fundus images. FGR-Net is evaluated with different interpretability methods, which indicates that the autoencoder is a key factor in forcing the classifier to focus on the relevant structures of the fundus images, such as the fovea, optic disk, and prominent blood vessels. Additionally, the interpretability methods can provide visual feedback for ophthalmologists to understand how our model evaluates the quality of fundus images. The experimental results showed the superiority of FGR-Net over the state-of-the-art quality assessment methods, with an accuracy of 89% and an F1-score of 87%.
Sign Languague Recognition without frame-sequencing constraints: A proof of concept on the Argentinian Sign Language
Oct 26, 2023Automatic sign language recognition (SLR) is an important topic within the areas of human-computer interaction and machine learning. On the one hand, it poses a complex challenge that requires the intervention of various knowledge areas, such as video processing, image processing, intelligent systems and linguistics. On the other hand, robust recognition of sign language could assist in the translation process and the integration of hearing-impaired people, as well as the teaching of sign language for the hearing population. SLR systems usually employ Hidden Markov Models, Dynamic Time Warping or similar models to recognize signs. Such techniques exploit the sequential ordering of frames to reduce the number of hypothesis. This paper presents a general probabilistic model for sign classification that combines sub-classifiers based on different types of features such as position, movement and handshape. The model employs a bag-of-words approach in all classification steps, to explore the hypothesis that ordering is not essential for recognition. The proposed model achieved an accuracy rate of 97% on an Argentinian Sign Language dataset containing 64 classes of signs and 3200 samples, providing some evidence that indeed recognition without ordering is possible.
Invariance Measures for Neural Networks
Oct 26, 2023Invariances in neural networks are useful and necessary for many tasks. However, the representation of the invariance of most neural network models has not been characterized. We propose measures to quantify the invariance of neural networks in terms of their internal representation. The measures are efficient and interpretable, and can be applied to any neural network model. They are also more sensitive to invariance than previously defined measures. We validate the measures and their properties in the domain of affine transformations and the CIFAR10 and MNIST datasets, including their stability and interpretability. Using the measures, we perform a first analysis of CNN models and show that their internal invariance is remarkably stable to random weight initializations, but not to changes in dataset or transformation. We believe the measures will enable new avenues of research in invariance representation.
Distribution of Action Movements (DAM): A Descriptor for Human Action Recognition
Oct 26, 2023Human action recognition from skeletal data is an important and active area of research in which the state of the art has not yet achieved near-perfect accuracy on many well-known datasets. In this paper, we introduce the Distribution of Action Movements Descriptor, a novel action descriptor based on the distribution of the directions of the motions of the joints between frames, over the set of all possible motions in the dataset. The descriptor is computed as a normalized histogram over a set of representative directions of the joints, which are in turn obtained via clustering. While the descriptor is global in the sense that it represents the overall distribution of movement directions of an action, it is able to partially retain its temporal structure by applying a windowing scheme. The descriptor, together with a standard classifier, outperforms several state-of-the-art techniques on many well-known datasets.
Handshape recognition for Argentinian Sign Language using ProbSom
Oct 26, 2023



Automatic sign language recognition is an important topic within the areas of human-computer interaction and machine learning. On the one hand, it poses a complex challenge that requires the intervention of various knowledge areas, such as video processing, image processing, intelligent systems and linguistics. On the other hand, robust recognition of sign language could assist in the translation process and the integration of hearing-impaired people. This paper offers two main contributions: first, the creation of a database of handshapes for the Argentinian Sign Language (LSA), which is a topic that has barely been discussed so far. Secondly, a technique for image processing, descriptor extraction and subsequent handshape classification using a supervised adaptation of self-organizing maps that is called ProbSom. This technique is compared to others in the state of the art, such as Support Vector Machines (SVM), Random Forests, and Neural Networks. The database that was built contains 800 images with 16 LSA handshapes, and is a first step towards building a comprehensive database of Argentinian signs. The ProbSom-based neural classifier, using the proposed descriptor, achieved an accuracy rate above 90%.
LSA64: An Argentinian Sign Language Dataset
Oct 26, 2023Automatic sign language recognition is a research area that encompasses human-computer interaction, computer vision and machine learning. Robust automatic recognition of sign language could assist in the translation process and the integration of hearing-impaired people, as well as the teaching of sign language to the hearing population. Sign languages differ significantly in different countries and even regions, and their syntax and semantics are different as well from those of written languages. While the techniques for automatic sign language recognition are mostly the same for different languages, training a recognition system for a new language requires having an entire dataset for that language. This paper presents a dataset of 64 signs from the Argentinian Sign Language (LSA). The dataset, called LSA64, contains 3200 videos of 64 different LSA signs recorded by 10 subjects, and is a first step towards building a comprehensive research-level dataset of Argentinian signs, specifically tailored to sign language recognition or other machine learning tasks. The subjects that performed the signs wore colored gloves to ease the hand tracking and segmentation steps, allowing experiments on the dataset to focus specifically on the recognition of signs. We also present a pre-processed version of the dataset, from which we computed statistics of movement, position and handshape of the signs.
Revisiting Data Augmentation for Rotational Invariance in Convolutional Neural Networks
Oct 12, 2023Convolutional Neural Networks (CNN) offer state of the art performance in various computer vision tasks. Many of those tasks require different subtypes of affine invariances (scale, rotational, translational) to image transformations. Convolutional layers are translation equivariant by design, but in their basic form lack invariances. In this work we investigate how best to include rotational invariance in a CNN for image classification. Our experiments show that networks trained with data augmentation alone can classify rotated images nearly as well as in the normal unrotated case; this increase in representational power comes only at the cost of training time. We also compare data augmentation versus two modified CNN models for achieving rotational invariance or equivariance, Spatial Transformer Networks and Group Equivariant CNNs, finding no significant accuracy increase with these specialized methods. In the case of data augmented networks, we also analyze which layers help the network to encode the rotational invariance, which is important for understanding its limitations and how to best retrain a network with data augmentation to achieve invariance to rotation.