 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFGR-Net:Interpretable fundus imagegradeability classification based on deepreconstruction learning
Sep 16, 2024
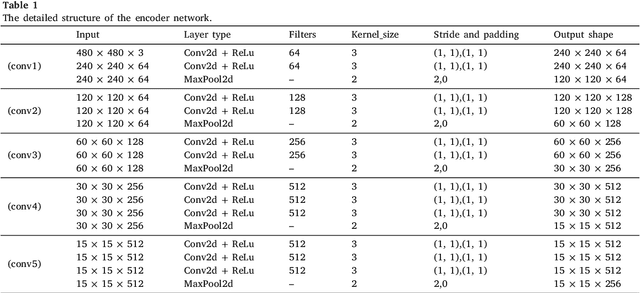
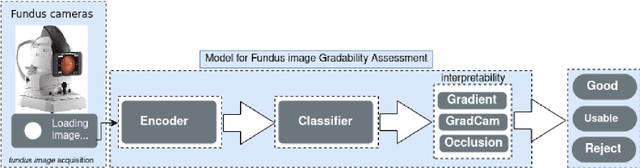
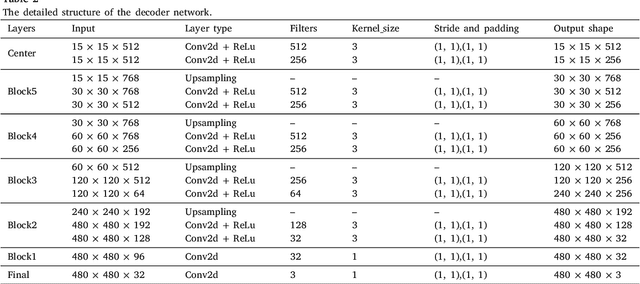
The performance of diagnostic Computer-Aided Design (CAD) systems for retinal diseases depends on the quality of the retinal images being screened. Thus, many studies have been developed to evaluate and assess the quality of such retinal images. However, most of them did not investigate the relationship between the accuracy of the developed models and the quality of the visualization of interpretability methods for distinguishing between gradable and non-gradable retinal images. Consequently, this paper presents a novel framework called FGR-Net to automatically assess and interpret underlying fundus image quality by merging an autoencoder network with a classifier network. The FGR-Net model also provides an interpretable quality assessment through visualizations. In particular, FGR-Net uses a deep autoencoder to reconstruct the input image in order to extract the visual characteristics of the input fundus images based on self-supervised learning. The extracted features by the autoencoder are then fed into a deep classifier network to distinguish between gradable and ungradable fundus images. FGR-Net is evaluated with different interpretability methods, which indicates that the autoencoder is a key factor in forcing the classifier to focus on the relevant structures of the fundus images, such as the fovea, optic disk, and prominent blood vessels. Additionally, the interpretability methods can provide visual feedback for ophthalmologists to understand how our model evaluates the quality of fundus images. The experimental results showed the superiority of FGR-Net over the state-of-the-art quality assessment methods, with an accuracy of 89% and an F1-score of 87%.
GCNDepth: Self-supervised Monocular Depth Estimation based on Graph Convolutional Network
Dec 13, 2021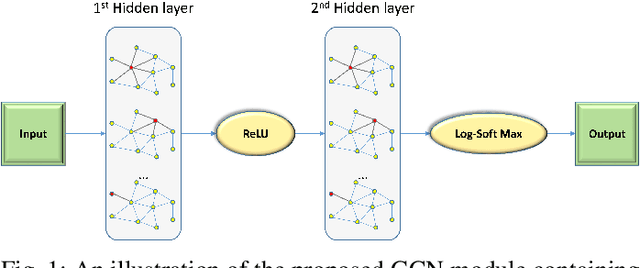
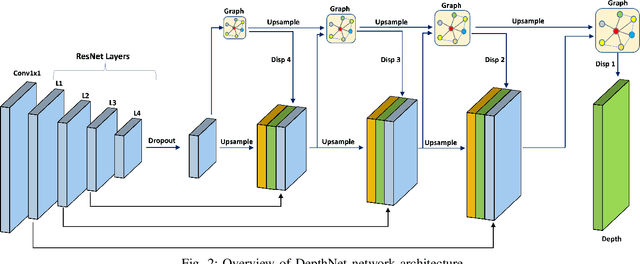
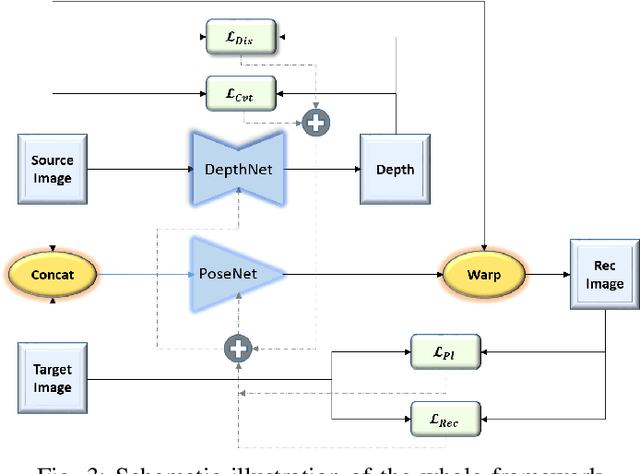
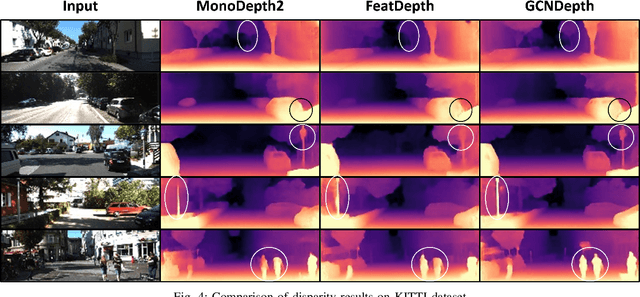
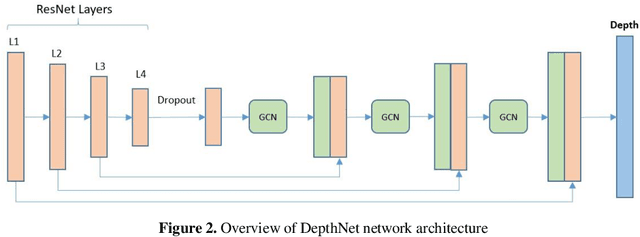
Depth estimation is a challenging task of 3D reconstruction to enhance the accuracy sensing of environment awareness. This work brings a new solution with a set of improvements, which increase the quantitative and qualitative understanding of depth maps compared to existing methods. Recently, a convolutional neural network (CNN) has demonstrated its extraordinary ability in estimating depth maps from monocular videos. However, traditional CNN does not support topological structure and they can work only on regular image regions with determined size and weights. On the other hand, graph convolutional networks (GCN) can handle the convolution on non-Euclidean data and it can be applied to irregular image regions within a topological structure. Therefore, in this work in order to preserve object geometric appearances and distributions, we aim at exploiting GCN for a self-supervised depth estimation model. Our model consists of two parallel auto-encoder networks: the first is an auto-encoder that will depend on ResNet-50 and extract the feature from the input image and on multi-scale GCN to estimate the depth map. In turn, the second network will be used to estimate the ego-motion vector (i.e., 3D pose) between two consecutive frames based on ResNet-18. Both the estimated 3D pose and depth map will be used for constructing a target image. A combination of loss functions related to photometric, projection, and smoothness is used to cope with bad depth prediction and preserve the discontinuities of the objects. In particular, our method provided comparable and promising results with a high prediction accuracy of 89% on the publicly KITTI and Make3D datasets along with a reduction of 40% in the number of trainable parameters compared to the state of the art solutions. The source code is publicly available at https://github.com/ArminMasoumian/GCNDepth.git
Absolute distance prediction based on deep learning object detection and monocular depth estimation models
Nov 02, 2021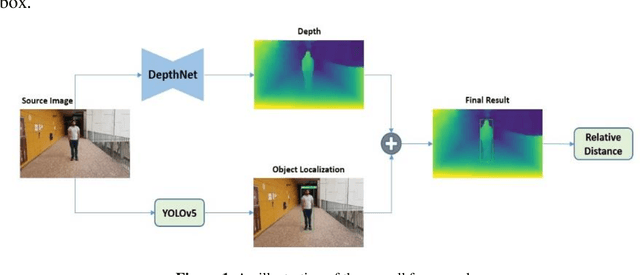
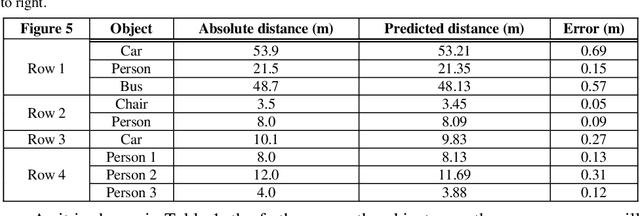
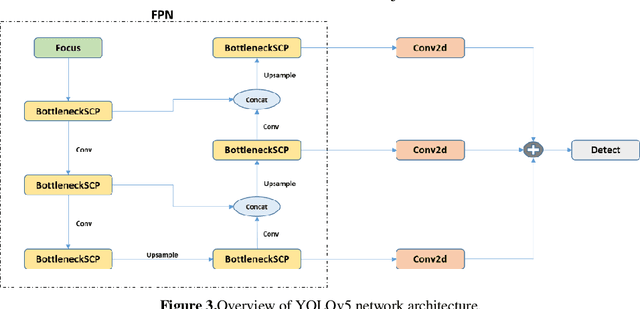
Determining the distance between the objects in a scene and the camera sensor from 2D images is feasible by estimating depth images using stereo cameras or 3D cameras. The outcome of depth estimation is relative distances that can be used to calculate absolute distances to be applicable in reality. However, distance estimation is very challenging using 2D monocular cameras. This paper presents a deep learning framework that consists of two deep networks for depth estimation and object detection using a single image. Firstly, objects in the scene are detected and localized using the You Only Look Once (YOLOv5) network. In parallel, the estimated depth image is computed using a deep autoencoder network to detect the relative distances. The proposed object detection based YOLO was trained using a supervised learning technique, in turn, the network of depth estimation was self-supervised training. The presented distance estimation framework was evaluated on real images of outdoor scenes. The achieved results show that the proposed framework is promising and it yields an accuracy of 96% with RMSE of 0.203 of the correct absolute distance.
REFUGE CHALLENGE 2018-Task 2:Deep Optic Disc and Cup Segmentation in Fundus Images Using U-Net and Multi-scale Feature Matching Networks
Jul 30, 2018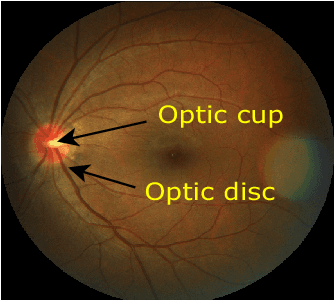

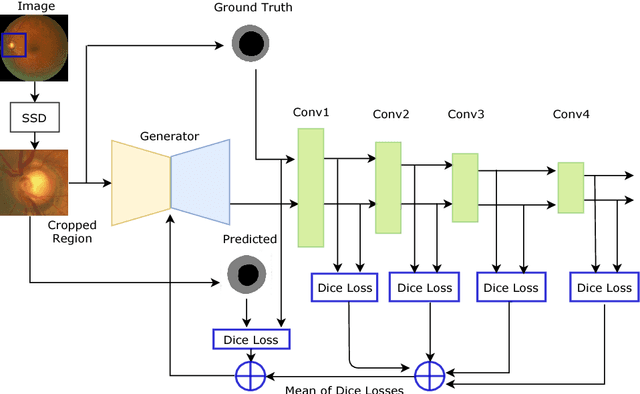
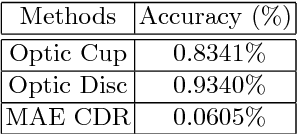
In this paper, an optic disc and cup segmentation method is proposed using U-Net followed by a multi-scale feature matching network. The proposed method targets task 2 of the REFUGE challenge 2018. In order to solve the segmentation problem of task 2, we firstly crop the input image using single shot multibox detector (SSD). The cropped image is then passed to an encoder-decoder network with skip connections also known as generator. Afterwards, both the ground truth and generated images are fed to a convolution neural network (CNN) to extract their multi-level features. A dice loss function is then used to match the features of the two images by minimizing the error at each layer. The aggregation of error from each layer is back-propagated through the generator network to enforce it to generate a segmented image closer to the ground truth. The CNN network improves the performance of the generator network without increasing the complexity of the model.
Retinal Optic Disc Segmentation using Conditional Generative Adversarial Network
Jun 11, 2018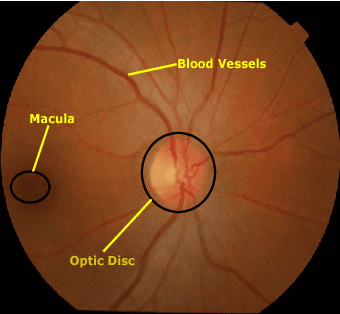
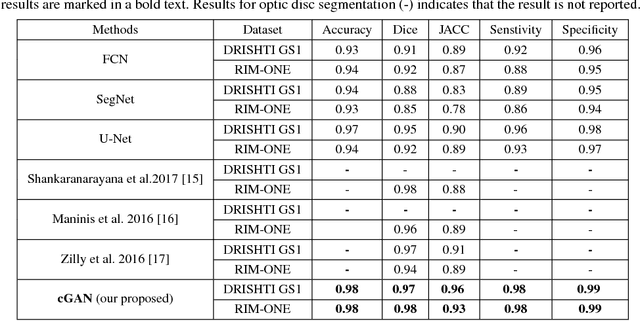
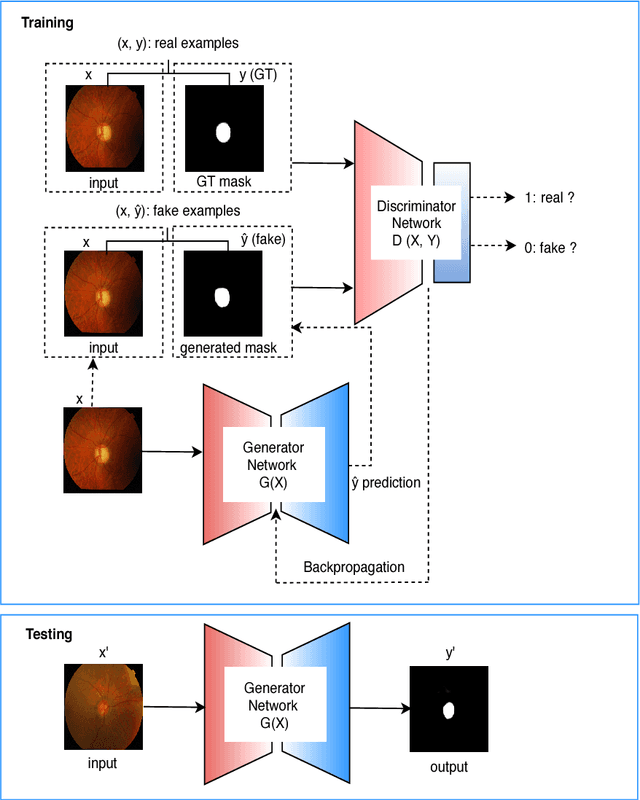

This paper proposed a retinal image segmentation method based on conditional Generative Adversarial Network (cGAN) to segment optic disc. The proposed model consists of two successive networks: generator and discriminator. The generator learns to map information from the observing input (i.e., retinal fundus color image), to the output (i.e., binary mask). Then, the discriminator learns as a loss function to train this mapping by comparing the ground-truth and the predicted output with observing the input image as a condition.Experiments were performed on two publicly available dataset; DRISHTI GS1 and RIM-ONE. The proposed model outperformed state-of-the-art-methods by achieving around 0.96% and 0.98% of Jaccard and Dice coefficients, respectively. Moreover, an image segmentation is performed in less than a second on recent GPU.
Conditional Generative Adversarial and Convolutional Networks for X-ray Breast Mass Segmentation and Shape Classification
Jun 10, 2018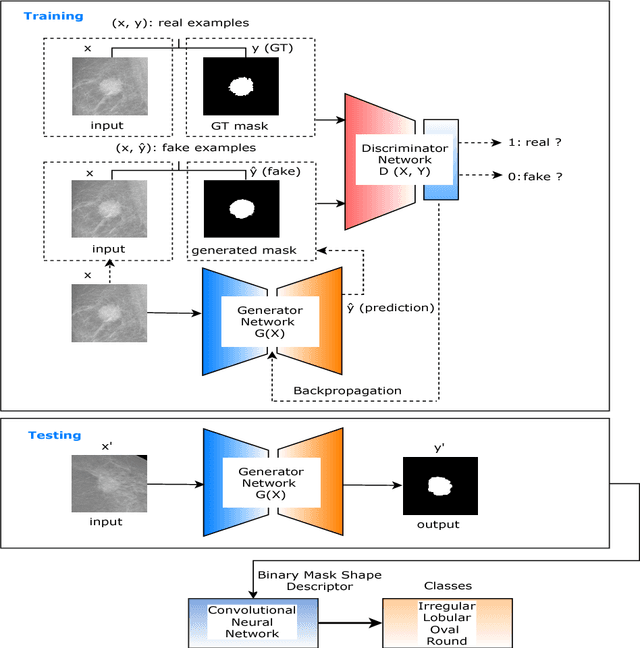
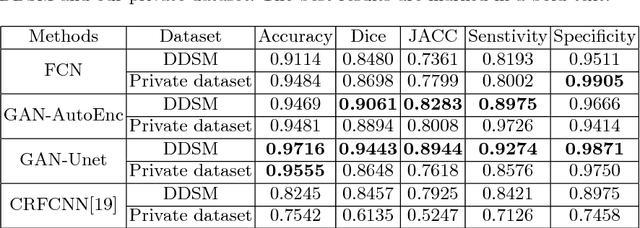

This paper proposes a novel approach based on conditional Generative Adversarial Networks (cGAN) for breast mass segmentation in mammography. We hypothesized that the cGAN structure is well-suited to accurately outline the mass area, especially when the training data is limited. The generative network learns intrinsic features of tumors while the adversarial network enforces segmentations to be similar to the ground truth. Experiments performed on dozens of malignant tumors extracted from the public DDSM dataset and from our in-house private dataset confirm our hypothesis with very high Dice coefficient and Jaccard index (>94% and >89%, respectively) outperforming the scores obtained by other state-of-the-art approaches. Furthermore, in order to detect portray significant morphological features of the segmented tumor, a specific Convolutional Neural Network (CNN) have also been designed for classifying the segmented tumor areas into four types (irregular, lobular, oval and round), which provides an overall accuracy about 72% with the DDSM dataset.
SLSDeep: Skin Lesion Segmentation Based on Dilated Residual and Pyramid Pooling Networks
May 31, 2018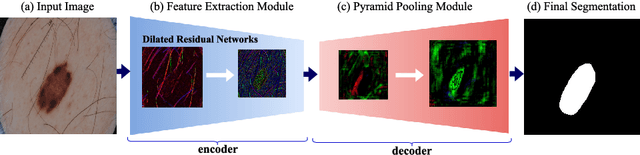
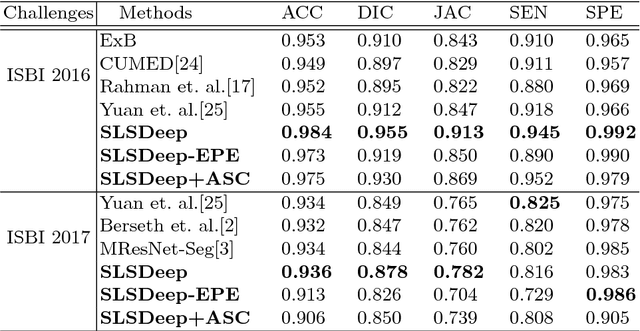
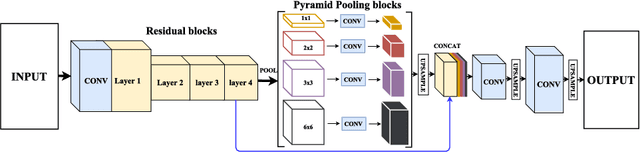
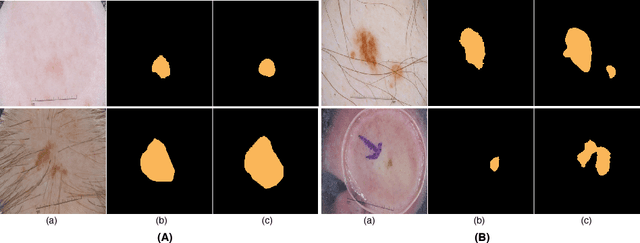
Skin lesion segmentation (SLS) in dermoscopic images is a crucial task for automated diagnosis of melanoma. In this paper, we present a robust deep learning SLS model, so-called SLSDeep, which is represented as an encoder-decoder network. The encoder network is constructed by dilated residual layers, in turn, a pyramid pooling network followed by three convolution layers is used for the decoder. Unlike the traditional methods employing a cross-entropy loss, we investigated a loss function by combining both Negative Log Likelihood (NLL) and End Point Error (EPE) to accurately segment the melanoma regions with sharp boundaries. The robustness of the proposed model was evaluated on two public databases: ISBI 2016 and 2017 for skin lesion analysis towards melanoma detection challenge. The proposed model outperforms the state-of-the-art methods in terms of segmentation accuracy. Moreover, it is capable to segment more than $100$ images of size 384x384 per second on a recent GPU.