 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGCNDepth: Self-supervised Monocular Depth Estimation based on Graph Convolutional Network
Dec 13, 2021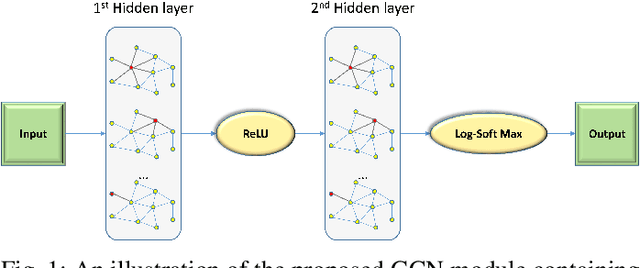
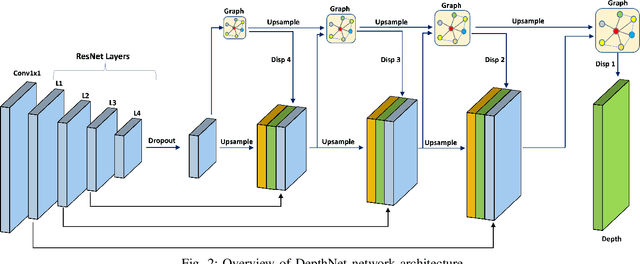
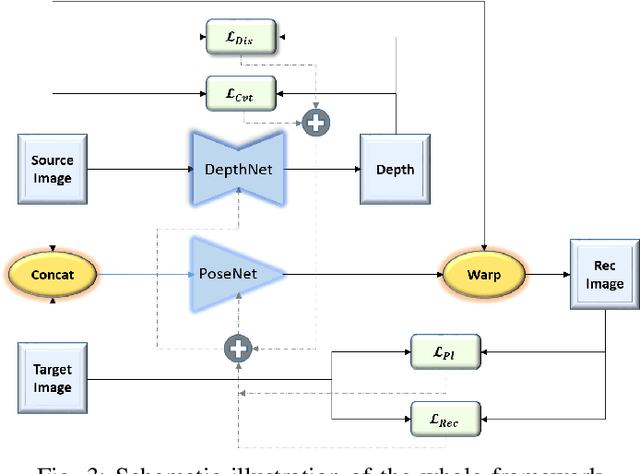
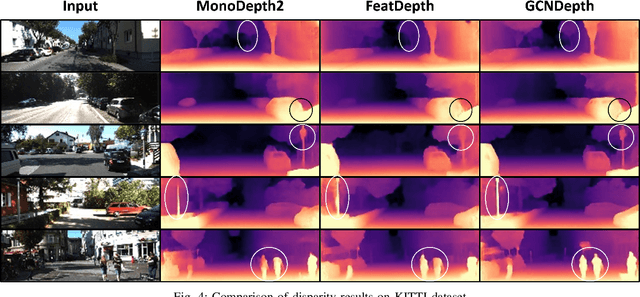
Depth estimation is a challenging task of 3D reconstruction to enhance the accuracy sensing of environment awareness. This work brings a new solution with a set of improvements, which increase the quantitative and qualitative understanding of depth maps compared to existing methods. Recently, a convolutional neural network (CNN) has demonstrated its extraordinary ability in estimating depth maps from monocular videos. However, traditional CNN does not support topological structure and they can work only on regular image regions with determined size and weights. On the other hand, graph convolutional networks (GCN) can handle the convolution on non-Euclidean data and it can be applied to irregular image regions within a topological structure. Therefore, in this work in order to preserve object geometric appearances and distributions, we aim at exploiting GCN for a self-supervised depth estimation model. Our model consists of two parallel auto-encoder networks: the first is an auto-encoder that will depend on ResNet-50 and extract the feature from the input image and on multi-scale GCN to estimate the depth map. In turn, the second network will be used to estimate the ego-motion vector (i.e., 3D pose) between two consecutive frames based on ResNet-18. Both the estimated 3D pose and depth map will be used for constructing a target image. A combination of loss functions related to photometric, projection, and smoothness is used to cope with bad depth prediction and preserve the discontinuities of the objects. In particular, our method provided comparable and promising results with a high prediction accuracy of 89% on the publicly KITTI and Make3D datasets along with a reduction of 40% in the number of trainable parameters compared to the state of the art solutions. The source code is publicly available at https://github.com/ArminMasoumian/GCNDepth.git
Designing and Analyzing the PID and Fuzzy Control System for an Inverted Pendulum
Nov 09, 2021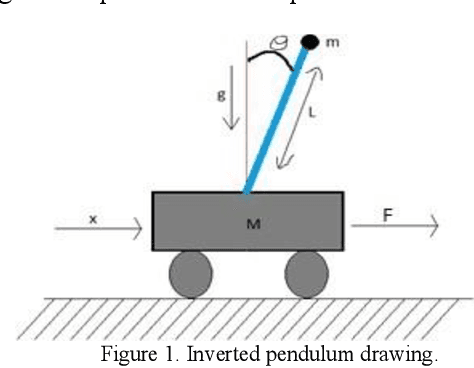


The inverted pendulum is a non-linear unbalanced system that needs to be controlled using motors to achieve stability and equilibrium. The inverted pendulum is constructed with Lego and using the Lego Mindstorm NXT, which is a programmable robot capable of completing many different functions. In this paper, an initial design of the inverted pendulum is proposed and the performance of different sensors, which are compatible with the Lego Mindstorm NXT was studied. Furthermore, the ability of computer vision to achieve the stability required to maintain the system is also investigated. The inverted pendulum is a conventional cart that can be controlled using a Fuzzy Logic controller that produces a self-tuning PID control for the cart to move on. The fuzzy logic and PID are simulated in MATLAB and Simulink, and the program for the robot is developed in the LabVIEW software.
Using The Feedback of Dynamic Active-Pixel Vision Sensor to Prevent Slip in Real Time
Nov 09, 2021
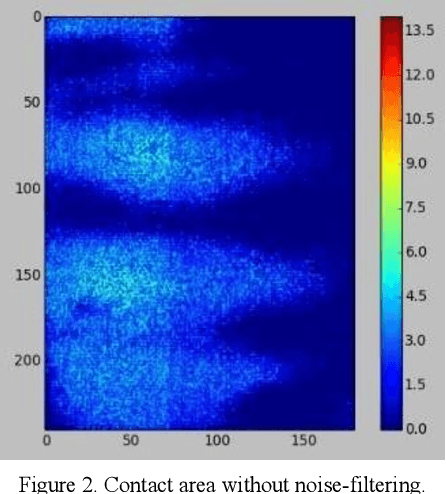
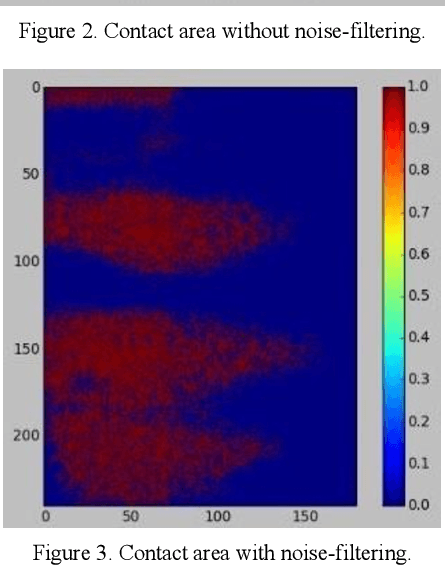
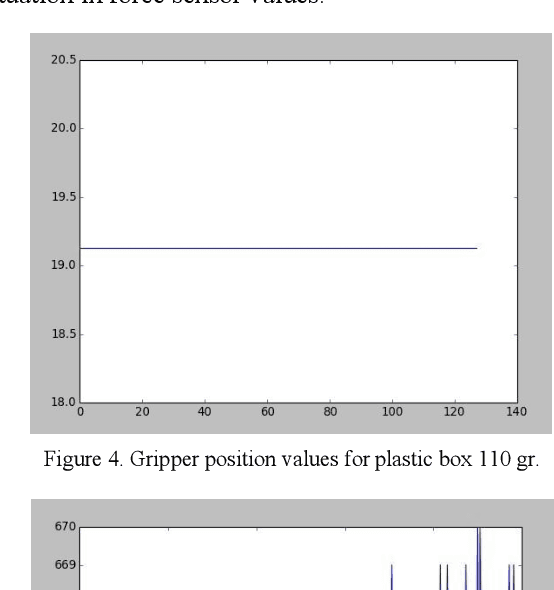
The objective of this paper is to describe an approach to detect the slip and contact force in real-time feedback. In this novel approach, the DAVIS camera is used as a vision tactile sensor due to its fast process speed and high resolution. Two hundred experiments were performed on four objects with different shapes, sizes, weights, and materials to compare the accuracy and response of the Baxter robot grippers to avoid slipping. The advanced approach is validated by using a force-sensitive resistor (FSR402). The events captured with the DAVIS camera are processed with specific algorithms to provide feedback to the Baxter robot aiding it to detect the slip.
DQRE-SCnet: A novel hybrid approach for selecting users in Federated Learning with Deep-Q-Reinforcement Learning based on Spectral Clustering
Nov 07, 2021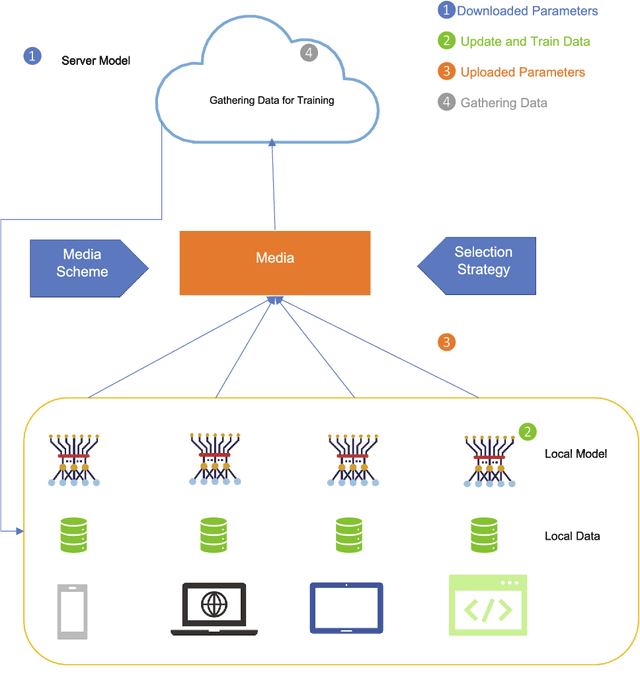
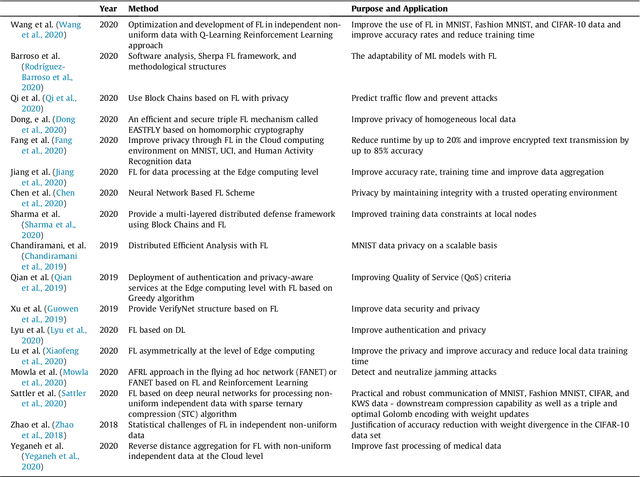

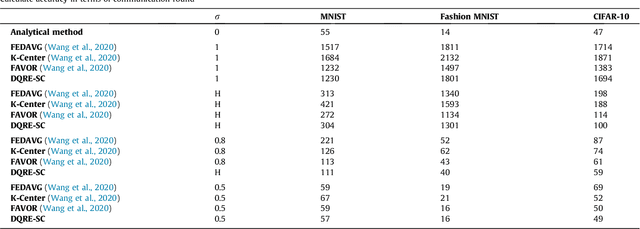
Machine learning models based on sensitive data in the real-world promise advances in areas ranging from medical screening to disease outbreaks, agriculture, industry, defense science, and more. In many applications, learning participant communication rounds benefit from collecting their own private data sets, teaching detailed machine learning models on the real data, and sharing the benefits of using these models. Due to existing privacy and security concerns, most people avoid sensitive data sharing for training. Without each user demonstrating their local data to a central server, Federated Learning allows various parties to train a machine learning algorithm on their shared data jointly. This method of collective privacy learning results in the expense of important communication during training. Most large-scale machine-learning applications require decentralized learning based on data sets generated on various devices and places. Such datasets represent an essential obstacle to decentralized learning, as their diverse contexts contribute to significant differences in the delivery of data across devices and locations. Researchers have proposed several ways to achieve data privacy in Federated Learning systems. However, there are still challenges with homogeneous local data. This research approach is to select nodes (users) to share their data in Federated Learning for independent data-based equilibrium to improve accuracy, reduce training time, and increase convergence. Therefore, this research presents a combined Deep-QReinforcement Learning Ensemble based on Spectral Clustering called DQRE-SCnet to choose a subset of devices in each communication round. Based on the results, it has been displayed that it is possible to decrease the number of communication rounds needed in Federated Learning.
Absolute distance prediction based on deep learning object detection and monocular depth estimation models
Nov 02, 2021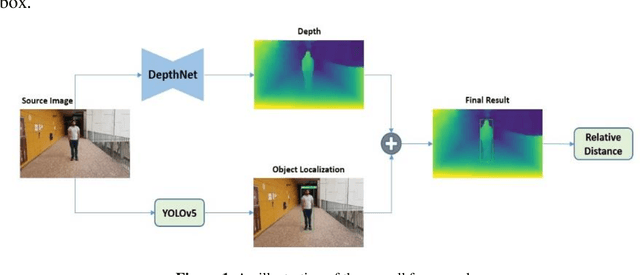
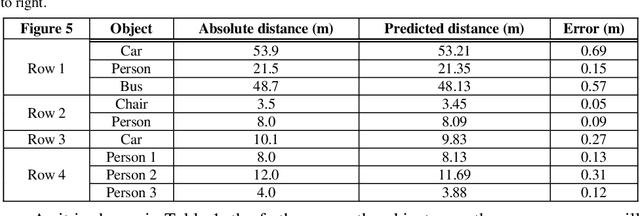
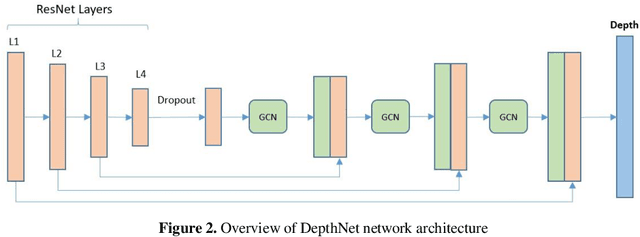
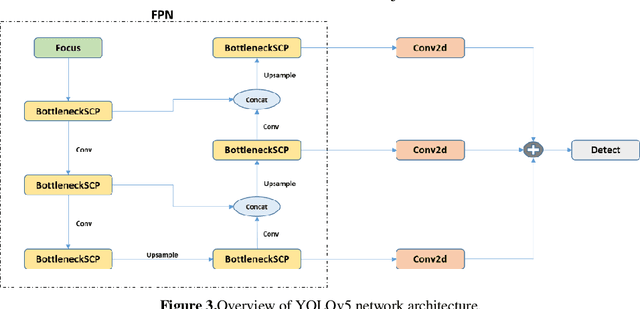
Determining the distance between the objects in a scene and the camera sensor from 2D images is feasible by estimating depth images using stereo cameras or 3D cameras. The outcome of depth estimation is relative distances that can be used to calculate absolute distances to be applicable in reality. However, distance estimation is very challenging using 2D monocular cameras. This paper presents a deep learning framework that consists of two deep networks for depth estimation and object detection using a single image. Firstly, objects in the scene are detected and localized using the You Only Look Once (YOLOv5) network. In parallel, the estimated depth image is computed using a deep autoencoder network to detect the relative distances. The proposed object detection based YOLO was trained using a supervised learning technique, in turn, the network of depth estimation was self-supervised training. The presented distance estimation framework was evaluated on real images of outdoor scenes. The achieved results show that the proposed framework is promising and it yields an accuracy of 96% with RMSE of 0.203 of the correct absolute distance.