 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDQRE-SCnet: A novel hybrid approach for selecting users in Federated Learning with Deep-Q-Reinforcement Learning based on Spectral Clustering
Nov 07, 2021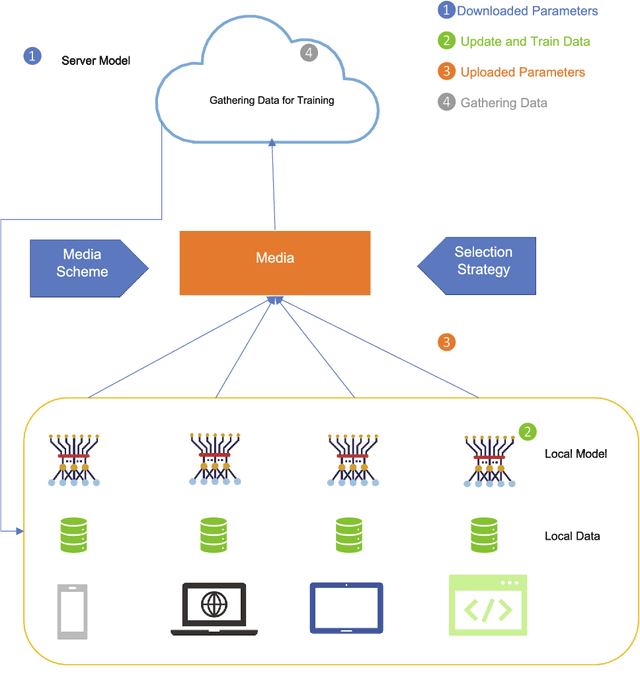
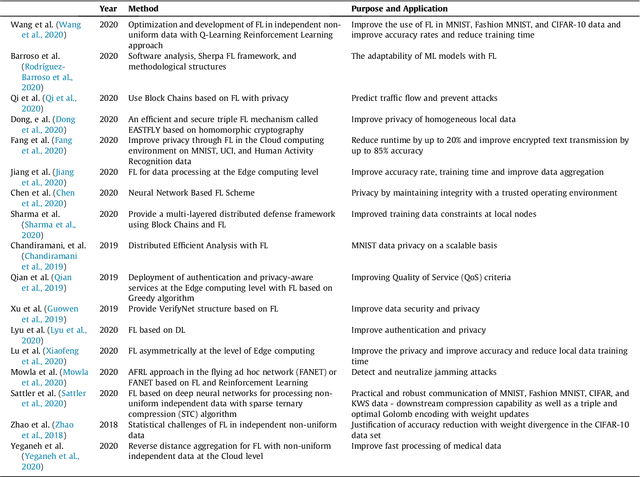

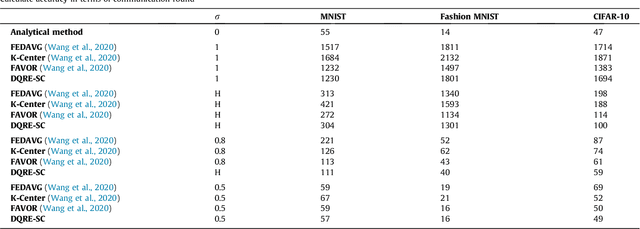
Machine learning models based on sensitive data in the real-world promise advances in areas ranging from medical screening to disease outbreaks, agriculture, industry, defense science, and more. In many applications, learning participant communication rounds benefit from collecting their own private data sets, teaching detailed machine learning models on the real data, and sharing the benefits of using these models. Due to existing privacy and security concerns, most people avoid sensitive data sharing for training. Without each user demonstrating their local data to a central server, Federated Learning allows various parties to train a machine learning algorithm on their shared data jointly. This method of collective privacy learning results in the expense of important communication during training. Most large-scale machine-learning applications require decentralized learning based on data sets generated on various devices and places. Such datasets represent an essential obstacle to decentralized learning, as their diverse contexts contribute to significant differences in the delivery of data across devices and locations. Researchers have proposed several ways to achieve data privacy in Federated Learning systems. However, there are still challenges with homogeneous local data. This research approach is to select nodes (users) to share their data in Federated Learning for independent data-based equilibrium to improve accuracy, reduce training time, and increase convergence. Therefore, this research presents a combined Deep-QReinforcement Learning Ensemble based on Spectral Clustering called DQRE-SCnet to choose a subset of devices in each communication round. Based on the results, it has been displayed that it is possible to decrease the number of communication rounds needed in Federated Learning.