 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGCNDepth: Self-supervised Monocular Depth Estimation based on Graph Convolutional Network
Dec 13, 2021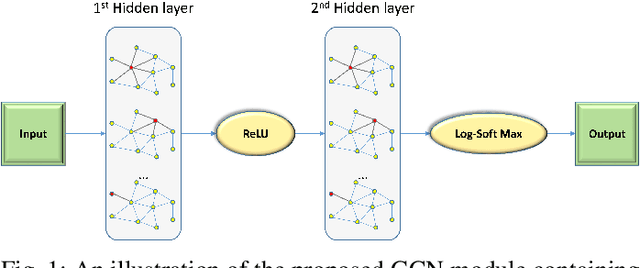
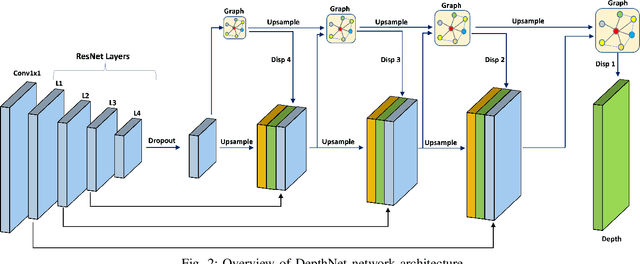
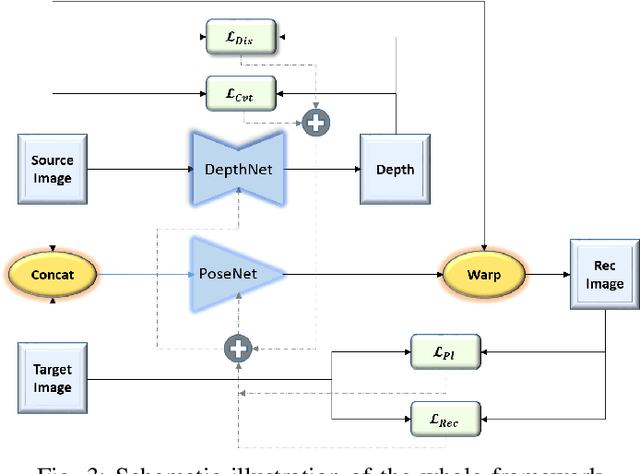
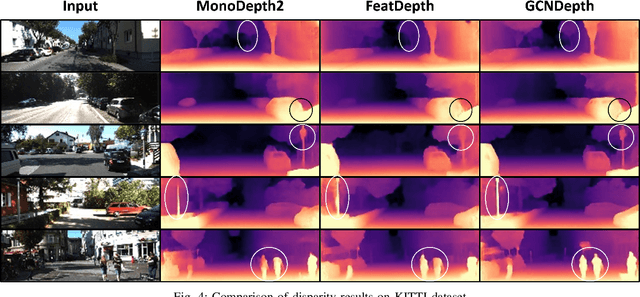
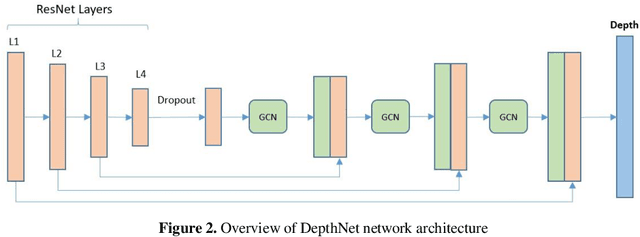
Depth estimation is a challenging task of 3D reconstruction to enhance the accuracy sensing of environment awareness. This work brings a new solution with a set of improvements, which increase the quantitative and qualitative understanding of depth maps compared to existing methods. Recently, a convolutional neural network (CNN) has demonstrated its extraordinary ability in estimating depth maps from monocular videos. However, traditional CNN does not support topological structure and they can work only on regular image regions with determined size and weights. On the other hand, graph convolutional networks (GCN) can handle the convolution on non-Euclidean data and it can be applied to irregular image regions within a topological structure. Therefore, in this work in order to preserve object geometric appearances and distributions, we aim at exploiting GCN for a self-supervised depth estimation model. Our model consists of two parallel auto-encoder networks: the first is an auto-encoder that will depend on ResNet-50 and extract the feature from the input image and on multi-scale GCN to estimate the depth map. In turn, the second network will be used to estimate the ego-motion vector (i.e., 3D pose) between two consecutive frames based on ResNet-18. Both the estimated 3D pose and depth map will be used for constructing a target image. A combination of loss functions related to photometric, projection, and smoothness is used to cope with bad depth prediction and preserve the discontinuities of the objects. In particular, our method provided comparable and promising results with a high prediction accuracy of 89% on the publicly KITTI and Make3D datasets along with a reduction of 40% in the number of trainable parameters compared to the state of the art solutions. The source code is publicly available at https://github.com/ArminMasoumian/GCNDepth.git
Absolute distance prediction based on deep learning object detection and monocular depth estimation models
Nov 02, 2021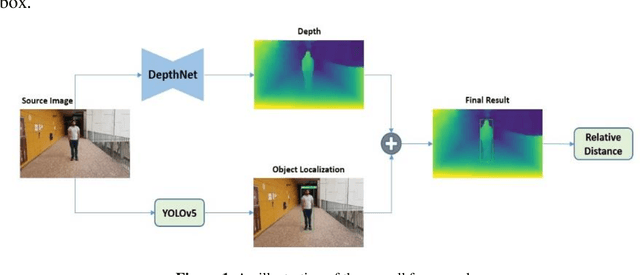
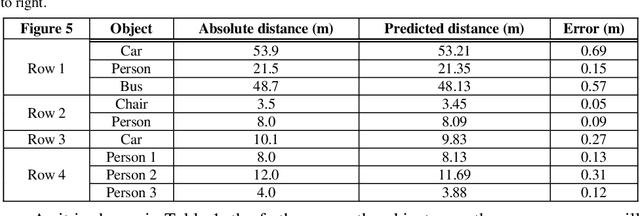
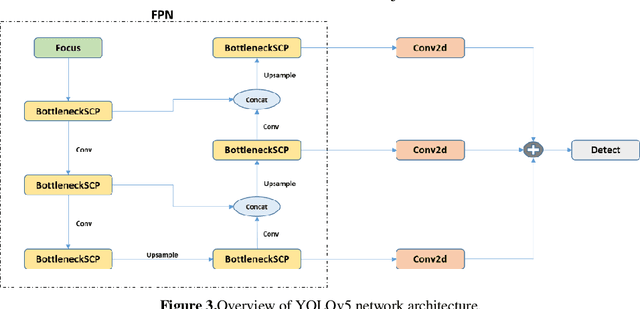
Determining the distance between the objects in a scene and the camera sensor from 2D images is feasible by estimating depth images using stereo cameras or 3D cameras. The outcome of depth estimation is relative distances that can be used to calculate absolute distances to be applicable in reality. However, distance estimation is very challenging using 2D monocular cameras. This paper presents a deep learning framework that consists of two deep networks for depth estimation and object detection using a single image. Firstly, objects in the scene are detected and localized using the You Only Look Once (YOLOv5) network. In parallel, the estimated depth image is computed using a deep autoencoder network to detect the relative distances. The proposed object detection based YOLO was trained using a supervised learning technique, in turn, the network of depth estimation was self-supervised training. The presented distance estimation framework was evaluated on real images of outdoor scenes. The achieved results show that the proposed framework is promising and it yields an accuracy of 96% with RMSE of 0.203 of the correct absolute distance.