 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFGR-Net:Interpretable fundus imagegradeability classification based on deepreconstruction learning
Sep 16, 2024
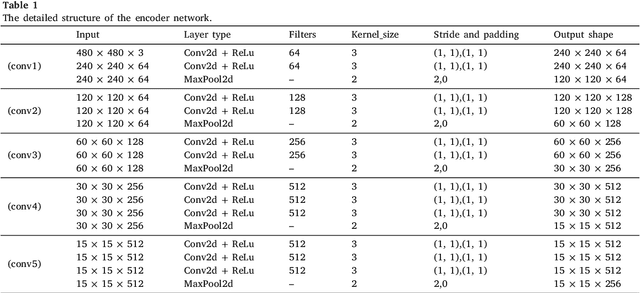
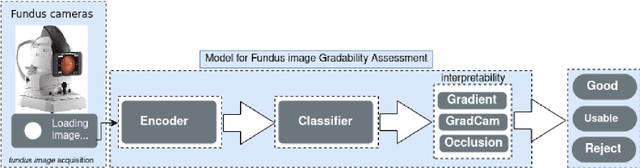
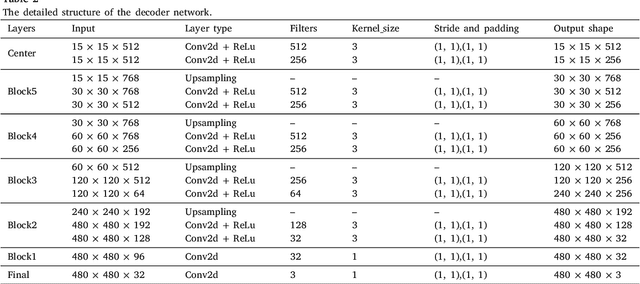
The performance of diagnostic Computer-Aided Design (CAD) systems for retinal diseases depends on the quality of the retinal images being screened. Thus, many studies have been developed to evaluate and assess the quality of such retinal images. However, most of them did not investigate the relationship between the accuracy of the developed models and the quality of the visualization of interpretability methods for distinguishing between gradable and non-gradable retinal images. Consequently, this paper presents a novel framework called FGR-Net to automatically assess and interpret underlying fundus image quality by merging an autoencoder network with a classifier network. The FGR-Net model also provides an interpretable quality assessment through visualizations. In particular, FGR-Net uses a deep autoencoder to reconstruct the input image in order to extract the visual characteristics of the input fundus images based on self-supervised learning. The extracted features by the autoencoder are then fed into a deep classifier network to distinguish between gradable and ungradable fundus images. FGR-Net is evaluated with different interpretability methods, which indicates that the autoencoder is a key factor in forcing the classifier to focus on the relevant structures of the fundus images, such as the fovea, optic disk, and prominent blood vessels. Additionally, the interpretability methods can provide visual feedback for ophthalmologists to understand how our model evaluates the quality of fundus images. The experimental results showed the superiority of FGR-Net over the state-of-the-art quality assessment methods, with an accuracy of 89% and an F1-score of 87%.
AWEU-Net: An Attention-Aware Weight Excitation U-Net for Lung Nodule Segmentation
Oct 11, 2021
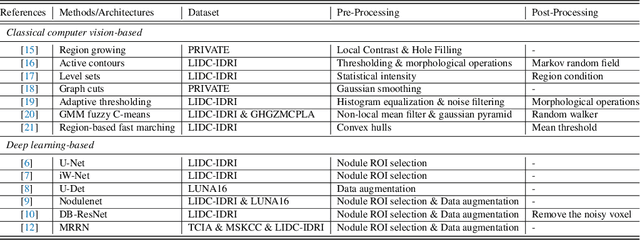

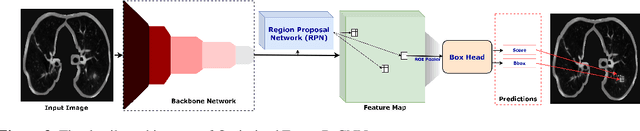
Lung cancer is deadly cancer that causes millions of deaths every year around the world. Accurate lung nodule detection and segmentation in computed tomography (CT) images is the most important part of diagnosing lung cancer in the early stage. Most of the existing systems are semi-automated and need to manually select the lung and nodules regions to perform the segmentation task. To address these challenges, we proposed a fully automated end-to-end lung nodule detection and segmentation system based on a deep learning approach. In this paper, we used Optimized Faster R-CNN; a state-of-the-art detection model to detect the lung nodule regions in the CT scans. Furthermore, we proposed an attention-aware weight excitation U-Net, called AWEU-Net, for lung nodule segmentation and boundaries detection. To achieve more accurate nodule segmentation, in AWEU-Net, we proposed position attention-aware weight excitation (PAWE), and channel attention-aware weight excitation (CAWE) blocks to highlight the best aligned spatial and channel features in the input feature maps. The experimental results demonstrate that our proposed model yields a Dice score of 89.79% and 90.35%, and an intersection over union (IoU) of 82.34% and 83.21% on the publicly LUNA16 and LIDC-IDRI datasets, respectively.
Adversarial Learning with Multiscale Features and Kernel Factorization for Retinal Blood Vessel Segmentation
Jul 05, 2019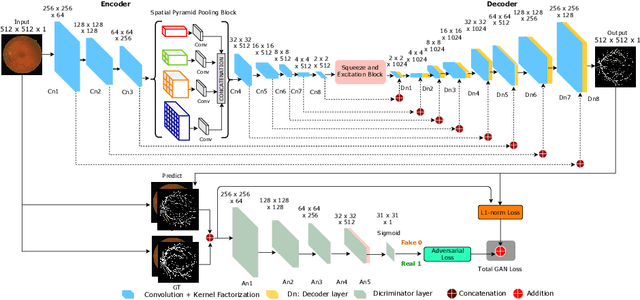
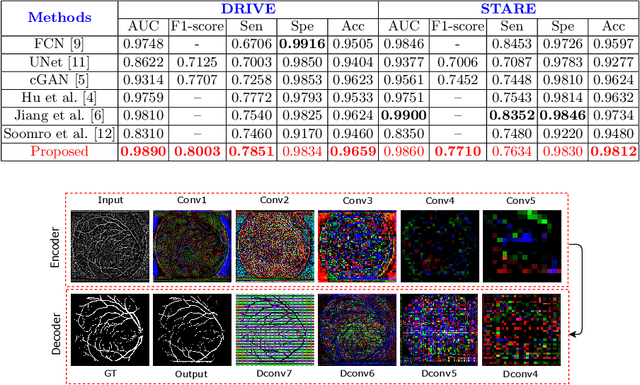
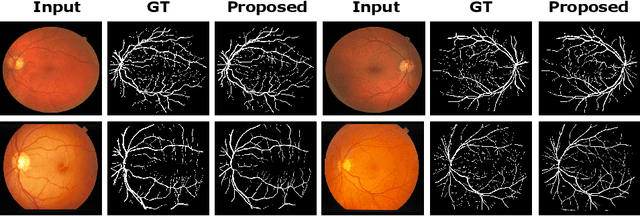
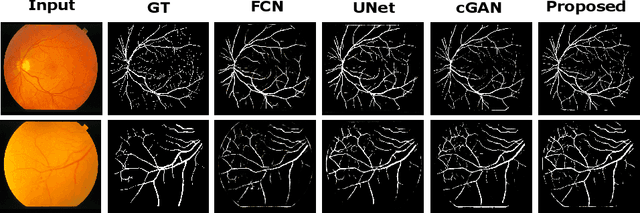
In this paper, we propose an efficient blood vessel segmentation method for the eye fundus images using adversarial learning with multiscale features and kernel factorization. In the generator network of the adversarial framework, spatial pyramid pooling, kernel factorization and squeeze excitation block are employed to enhance the feature representation in spatial domain on different scales with reduced computational complexity. In turn, the discriminator network of the adversarial framework is formulated by combining convolutional layers with an additional squeeze excitation block to differentiate the generated segmentation mask from its respective ground truth. Before feeding the images to the network, we pre-processed them by using edge sharpening and Gaussian regularization to reach an optimized solution for vessel segmentation. The output of the trained model is post-processed using morphological operations to remove the small speckles of noise. The proposed method qualitatively and quantitatively outperforms state-of-the-art vessel segmentation methods using DRIVE and STARE datasets.
An Efficient Solution for Breast Tumor Segmentation and Classification in Ultrasound Images Using Deep Adversarial Learning
Jul 01, 2019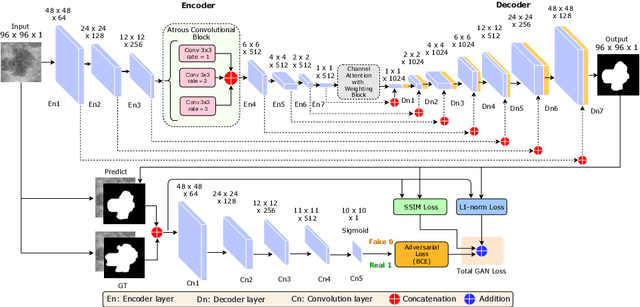
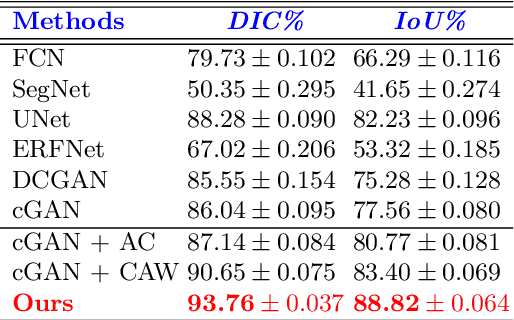
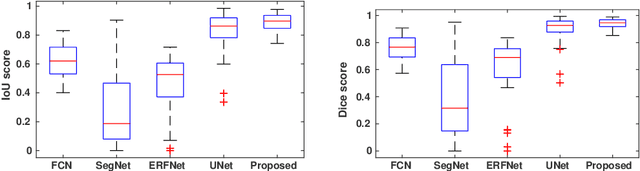

This paper proposes an efficient solution for tumor segmentation and classification in breast ultrasound (BUS) images. We propose to add an atrous convolution layer to the conditional generative adversarial network (cGAN) segmentation model to learn tumor features at different resolutions of BUS images. To automatically re-balance the relative impact of each of the highest level encoded features, we also propose to add a channel-wise weighting block in the network. In addition, the SSIM and L1-norm loss with the typical adversarial loss are used as a loss function to train the model. Our model outperforms the state-of-the-art segmentation models in terms of the Dice and IoU metrics, achieving top scores of 93.76% and 88.82%, respectively. In the classification stage, we show that few statistics features extracted from the shape of the boundaries of the predicted masks can properly discriminate between benign and malignant tumors with an accuracy of 85%$
MobileGAN: Skin Lesion Segmentation Using a Lightweight Generative Adversarial Network
Jul 01, 2019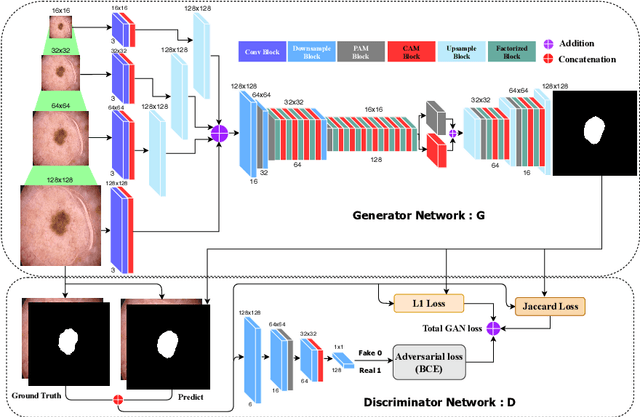
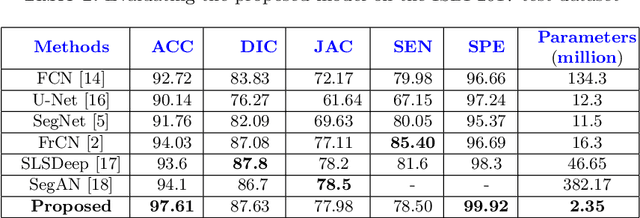
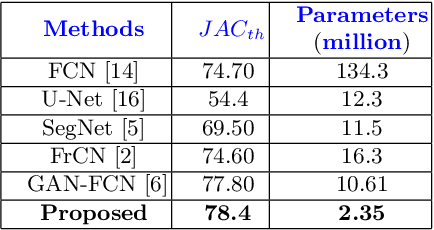
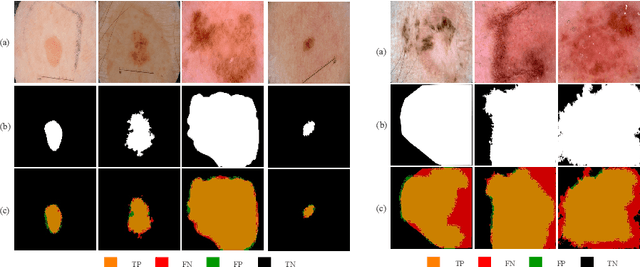
Skin lesion segmentation in dermoscopic images is a challenge due to their blurry and irregular boundaries. Most of the segmentation approaches based on deep learning are time and memory consuming due to the hundreds of millions of parameters. Consequently, it is difficult to apply them to real dermatoscope devices with limited GPU and memory resources. In this paper, we propose a lightweight and efficient Generative Adversarial Networks (GAN) model, called MobileGAN for skin lesion segmentation. More precisely, the MobileGAN combines 1D non-bottleneck factorization networks with position and channel attention modules in a GAN model. The proposed model is evaluated on the test dataset of the ISBI 2017 challenges and the validation dataset of ISIC 2018 challenges. Although the proposed network has only 2.35 millions of parameters, it is still comparable with the state-of-the-art. The experimental results show that our MobileGAN obtains comparable performance with an accuracy of 97.61%.