 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAWEU-Net: An Attention-Aware Weight Excitation U-Net for Lung Nodule Segmentation
Oct 11, 2021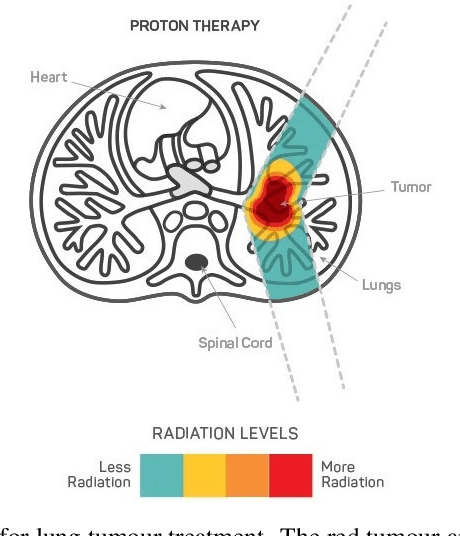
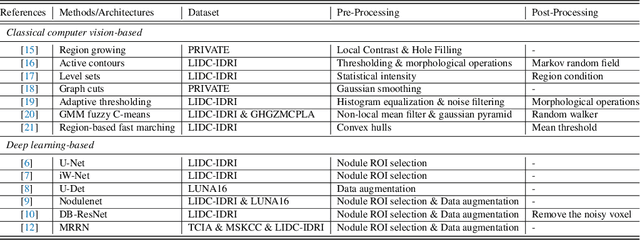

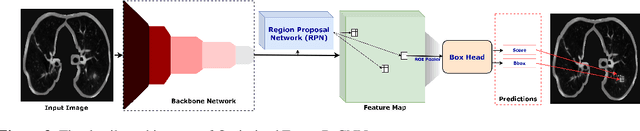
Lung cancer is deadly cancer that causes millions of deaths every year around the world. Accurate lung nodule detection and segmentation in computed tomography (CT) images is the most important part of diagnosing lung cancer in the early stage. Most of the existing systems are semi-automated and need to manually select the lung and nodules regions to perform the segmentation task. To address these challenges, we proposed a fully automated end-to-end lung nodule detection and segmentation system based on a deep learning approach. In this paper, we used Optimized Faster R-CNN; a state-of-the-art detection model to detect the lung nodule regions in the CT scans. Furthermore, we proposed an attention-aware weight excitation U-Net, called AWEU-Net, for lung nodule segmentation and boundaries detection. To achieve more accurate nodule segmentation, in AWEU-Net, we proposed position attention-aware weight excitation (PAWE), and channel attention-aware weight excitation (CAWE) blocks to highlight the best aligned spatial and channel features in the input feature maps. The experimental results demonstrate that our proposed model yields a Dice score of 89.79% and 90.35%, and an intersection over union (IoU) of 82.34% and 83.21% on the publicly LUNA16 and LIDC-IDRI datasets, respectively.
MobileGAN: Skin Lesion Segmentation Using a Lightweight Generative Adversarial Network
Jul 01, 2019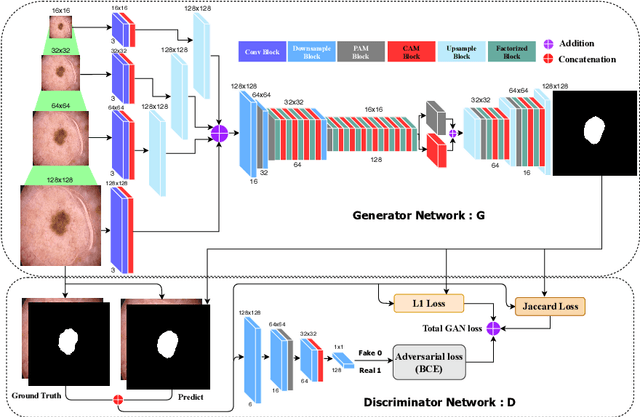
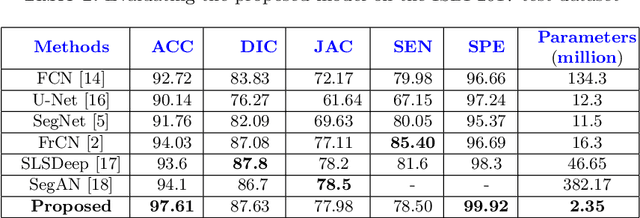
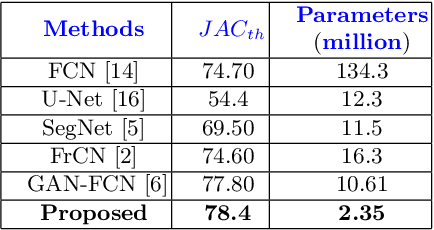
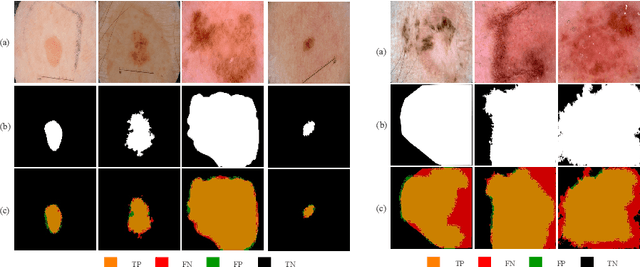
Skin lesion segmentation in dermoscopic images is a challenge due to their blurry and irregular boundaries. Most of the segmentation approaches based on deep learning are time and memory consuming due to the hundreds of millions of parameters. Consequently, it is difficult to apply them to real dermatoscope devices with limited GPU and memory resources. In this paper, we propose a lightweight and efficient Generative Adversarial Networks (GAN) model, called MobileGAN for skin lesion segmentation. More precisely, the MobileGAN combines 1D non-bottleneck factorization networks with position and channel attention modules in a GAN model. The proposed model is evaluated on the test dataset of the ISBI 2017 challenges and the validation dataset of ISIC 2018 challenges. Although the proposed network has only 2.35 millions of parameters, it is still comparable with the state-of-the-art. The experimental results show that our MobileGAN obtains comparable performance with an accuracy of 97.61%.
MACNet: Multi-scale Atrous Convolution Networks for Food Places Classification in Egocentric Photo-streams
Aug 29, 2018
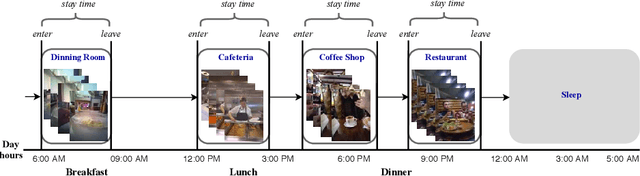
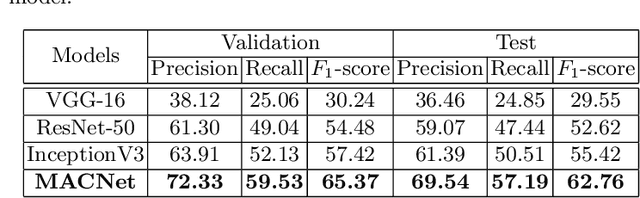
First-person (wearable) camera continually captures unscripted interactions of the camera user with objects, people, and scenes reflecting his personal and relational tendencies. One of the preferences of people is their interaction with food events. The regulation of food intake and its duration has a great importance to protect against diseases. Consequently, this work aims to develop a smart model that is able to determine the recurrences of a person on food places during a day. This model is based on a deep end-to-end model for automatic food places recognition by analyzing egocentric photo-streams. In this paper, we apply multi-scale Atrous convolution networks to extract the key features related to food places of the input images. The proposed model is evaluated on an in-house private dataset called "EgoFoodPlaces". Experimental results shows promising results of food places classification recognition in egocentric photo-streams.
CuisineNet: Food Attributes Classification using Multi-scale Convolution Network
Jun 08, 2018
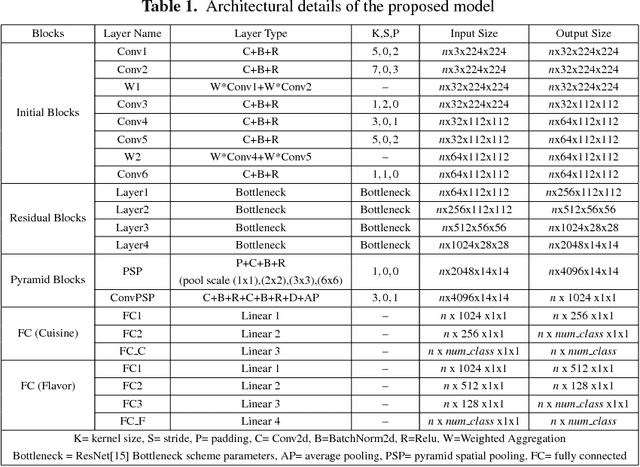
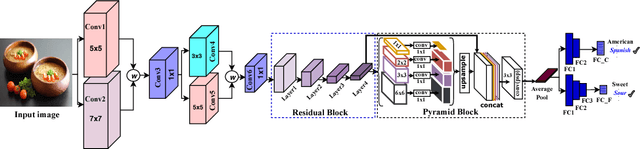
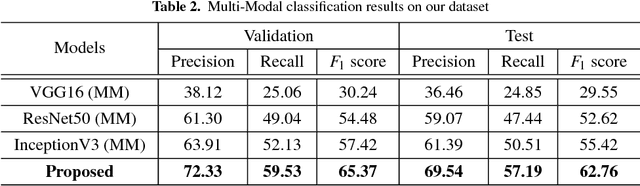
Diversity of food and its attributes represents the culinary habits of peoples from different countries. Thus, this paper addresses the problem of identifying food culture of people around the world and its flavor by classifying two main food attributes, cuisine and flavor. A deep learning model based on multi-scale convotuional networks is proposed for extracting more accurate features from input images. The aggregation of multi-scale convolution layers with different kernel size is also used for weighting the features results from different scales. In addition, a joint loss function based on Negative Log Likelihood (NLL) is used to fit the model probability to multi labeled classes for multi-modal classification task. Furthermore, this work provides a new dataset for food attributes, so-called Yummly48K, extracted from the popular food website, Yummly. Our model is assessed on the constructed Yummly48K dataset. The experimental results show that our proposed method yields 65% and 62% average F1 score on validation and test set which outperforming the state-of-the-art models.
SLSDeep: Skin Lesion Segmentation Based on Dilated Residual and Pyramid Pooling Networks
May 31, 2018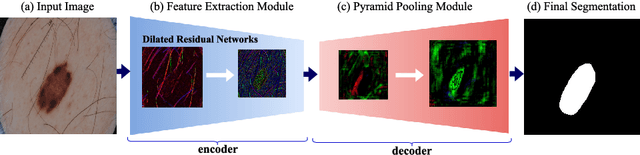
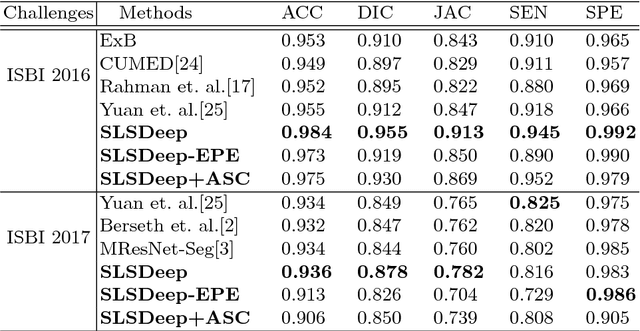
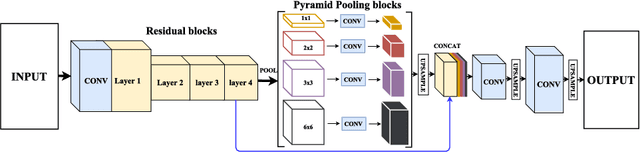
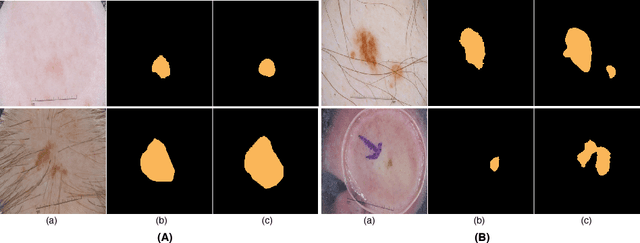
Skin lesion segmentation (SLS) in dermoscopic images is a crucial task for automated diagnosis of melanoma. In this paper, we present a robust deep learning SLS model, so-called SLSDeep, which is represented as an encoder-decoder network. The encoder network is constructed by dilated residual layers, in turn, a pyramid pooling network followed by three convolution layers is used for the decoder. Unlike the traditional methods employing a cross-entropy loss, we investigated a loss function by combining both Negative Log Likelihood (NLL) and End Point Error (EPE) to accurately segment the melanoma regions with sharp boundaries. The robustness of the proposed model was evaluated on two public databases: ISBI 2016 and 2017 for skin lesion analysis towards melanoma detection challenge. The proposed model outperforms the state-of-the-art methods in terms of segmentation accuracy. Moreover, it is capable to segment more than $100$ images of size 384x384 per second on a recent GPU.