 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCuisineNet: Food Attributes Classification using Multi-scale Convolution Network
Jun 08, 2018
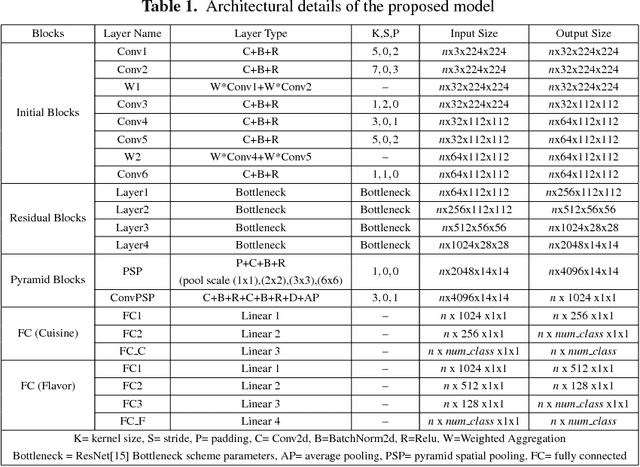
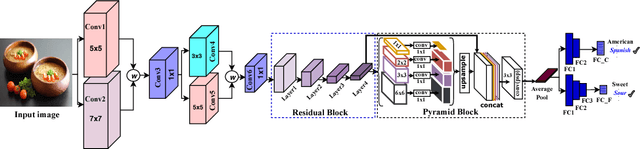
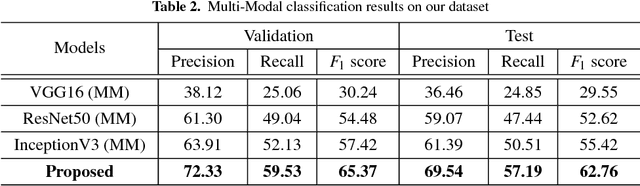
Diversity of food and its attributes represents the culinary habits of peoples from different countries. Thus, this paper addresses the problem of identifying food culture of people around the world and its flavor by classifying two main food attributes, cuisine and flavor. A deep learning model based on multi-scale convotuional networks is proposed for extracting more accurate features from input images. The aggregation of multi-scale convolution layers with different kernel size is also used for weighting the features results from different scales. In addition, a joint loss function based on Negative Log Likelihood (NLL) is used to fit the model probability to multi labeled classes for multi-modal classification task. Furthermore, this work provides a new dataset for food attributes, so-called Yummly48K, extracted from the popular food website, Yummly. Our model is assessed on the constructed Yummly48K dataset. The experimental results show that our proposed method yields 65% and 62% average F1 score on validation and test set which outperforming the state-of-the-art models.
EiTAKA at SemEval-2018 Task 1: An Ensemble of N-Channels ConvNet and XGboost Regressors for Emotion Analysis of Tweets
Feb 26, 2018



This paper describes our system that has been used in Task1 Affect in Tweets. We combine two different approaches. The first one called N-Stream ConvNets, which is a deep learning approach where the second one is XGboost regresseor based on a set of embedding and lexicons based features. Our system was evaluated on the testing sets of the tasks outperforming all other approaches for the Arabic version of valence intensity regression task and valence ordinal classification task.
GRAMPAL: A Morphological Processor for Spanish implemented in Prolog
Jul 18, 1995
A model for the full treatment of Spanish inflection for verbs, nouns and adjectives is presented. This model is based on feature unification and it relies upon a lexicon of allomorphs both for stems and morphemes. Word forms are built by the concatenation of allomorphs by means of special contextual features. We make use of standard Definite Clause Grammars (DCG) included in most Prolog implementations, instead of the typical finite-state approach. This allows us to take advantage of the declarativity and bidirectionality of Logic Programming for NLP. The most salient feature of this approach is simplicity: A really straightforward rule and lexical components. We have developed a very simple model for complex phenomena. Declarativity, bidirectionality, consistency and completeness of the model are discussed: all and only correct word forms are analysed or generated, even alternative ones and gaps in paradigms are preserved. A Prolog implementation has been developed for both analysis and generation of Spanish word forms. It consists of only six DCG rules, because our {\em lexicalist\/} approach --i.e. most information is in the dictionary. Although it is quite efficient, the current implementation could be improved for analysis by using the non logical features of Prolog, especially in word segmentation and dictionary access.
* 11 pages