 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation for Adaptive MRI Prostate Segmentation Based on Limit-Trained Multi-Teacher Models
Mar 16, 2023With numerous medical tasks, the performance of deep models has recently experienced considerable improvements. These models are often adept learners. Yet, their intricate architectural design and high computational complexity make deploying them in clinical settings challenging, particularly with devices with limited resources. To deal with this issue, Knowledge Distillation (KD) has been proposed as a compression method and an acceleration technology. KD is an efficient learning strategy that can transfer knowledge from a burdensome model (i.e., teacher model) to a lightweight model (i.e., student model). Hence we can obtain a compact model with low parameters with preserving the teacher's performance. Therefore, we develop a KD-based deep model for prostate MRI segmentation in this work by combining features-based distillation with Kullback-Leibler divergence, Lovasz, and Dice losses. We further demonstrate its effectiveness by applying two compression procedures: 1) distilling knowledge to a student model from a single well-trained teacher, and 2) since most of the medical applications have a small dataset, we train multiple teachers that each one trained with a small set of images to learn an adaptive student model as close to the teachers as possible considering the desired accuracy and fast inference time. Extensive experiments were conducted on a public multi-site prostate tumor dataset, showing that the proposed adaptation KD strategy improves the dice similarity score by 9%, outperforming all tested well-established baseline models.
Retinal Optic Disc Segmentation using Conditional Generative Adversarial Network
Jun 11, 2018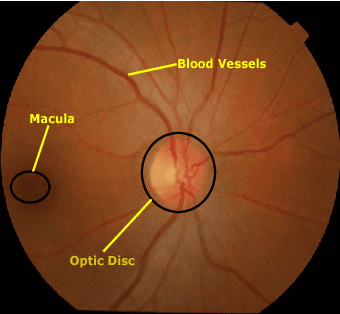
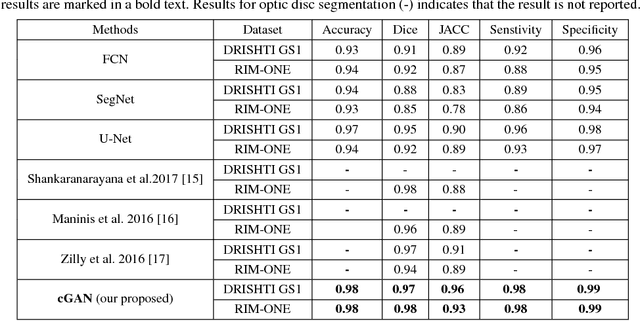
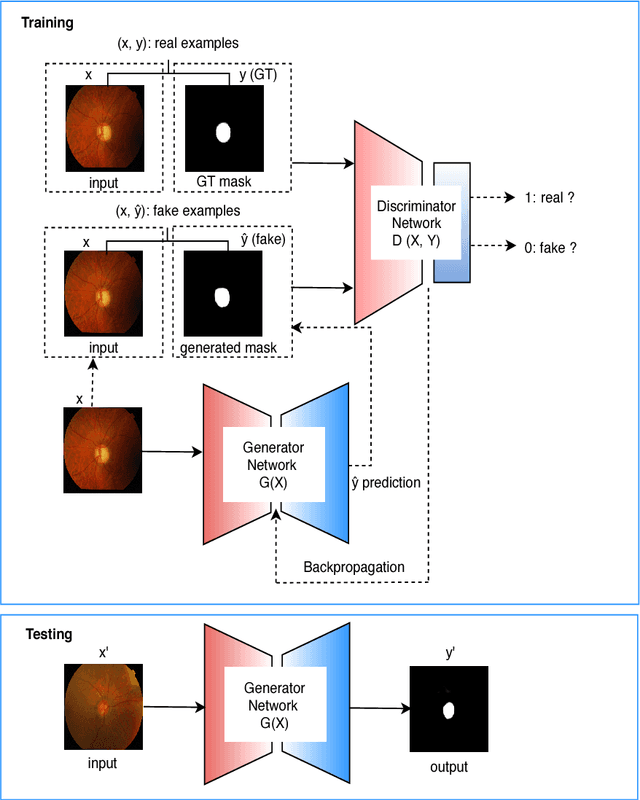

This paper proposed a retinal image segmentation method based on conditional Generative Adversarial Network (cGAN) to segment optic disc. The proposed model consists of two successive networks: generator and discriminator. The generator learns to map information from the observing input (i.e., retinal fundus color image), to the output (i.e., binary mask). Then, the discriminator learns as a loss function to train this mapping by comparing the ground-truth and the predicted output with observing the input image as a condition.Experiments were performed on two publicly available dataset; DRISHTI GS1 and RIM-ONE. The proposed model outperformed state-of-the-art-methods by achieving around 0.96% and 0.98% of Jaccard and Dice coefficients, respectively. Moreover, an image segmentation is performed in less than a second on recent GPU.