 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUn análisis bibliométrico de la producción científica acerca del agrupamiento de trayectorias GPS
Apr 27, 2024Clustering algorithms or methods for GPS trajectories are in constant evolution due to the interest aroused in part of the scientific community. With the development of clustering algorithms considered traditional, improvements to these algorithms and even unique methods considered as "novelty" for science have emerged. This work aims to analyze the scientific production that exists around the topic "GPS trajectory clustering" by means of bibliometrics. Therefore, a total of 559 articles from the main collection of Scopus were analyzed, previously filtering the generated sample to discard any article that does not have a direct relationship with the topic to be analyzed. This analysis establishes an ideal environment for other disciplines and researchers, since it provides a current state of the trend of the subject of study in their field of research. -- Los algoritmos o m\'etodos de agrupamiento para trayectorias GPS se encuentran en constante evoluci\'on debido al inter\'es que despierta en parte de la comunidad cient\'ifica. Con el desarrollo de los algoritmos de agrupamiento considerados tradicionales han surgido mejoras a estos algoritmos e incluso m\'etodos \'unicos considerados como "novedad" para la ciencia. Este trabajo tiene como objetivo analizar la producci\'on cient\'ifica que existe alrededor del tema "agrupamiento de trayectorias GPS" mediante la bibliometr\'ia. Por lo tanto, fueron analizados un total de 559 art\'iculos de la colecci\'on principal de Scopus, realizando previamente un filtrado de la muestra generada para descartar todo aquel art\'iculo que no tenga una relaci\'on directa con el tema a analizar. Este an\'alisis establece un ambiente ideal para otras disciplinas e investigadores, ya que entrega un estado actual de la tendencia que lleva la tem\'atica de estudio en su campo de investigaci\'on.
First Experiences with the Identification of People at Risk for Diabetes in Argentina using Machine Learning Techniques
Mar 27, 2024Detecting Type 2 Diabetes (T2D) and Prediabetes (PD) is a real challenge for medicine due to the absence of pathogenic symptoms and the lack of known associated risk factors. Even though some proposals for machine learning models enable the identification of people at risk, the nature of the condition makes it so that a model suitable for one population may not necessarily be suitable for another. In this article, the development and assessment of predictive models to identify people at risk for T2D and PD specifically in Argentina are discussed. First, the database was thoroughly preprocessed and three specific datasets were generated considering a compromise between the number of records and the amount of available variables. After applying 5 different classification models, the results obtained show that a very good performance was observed for two datasets with some of these models. In particular, RF, DT, and ANN demonstrated great classification power, with good values for the metrics under consideration. Given the lack of this type of tool in Argentina, this work represents the first step towards the development of more sophisticated models.
Distribution of Action Movements (DAM): A Descriptor for Human Action Recognition
Oct 26, 2023Human action recognition from skeletal data is an important and active area of research in which the state of the art has not yet achieved near-perfect accuracy on many well-known datasets. In this paper, we introduce the Distribution of Action Movements Descriptor, a novel action descriptor based on the distribution of the directions of the motions of the joints between frames, over the set of all possible motions in the dataset. The descriptor is computed as a normalized histogram over a set of representative directions of the joints, which are in turn obtained via clustering. While the descriptor is global in the sense that it represents the overall distribution of movement directions of an action, it is able to partially retain its temporal structure by applying a windowing scheme. The descriptor, together with a standard classifier, outperforms several state-of-the-art techniques on many well-known datasets.
Sign Languague Recognition without frame-sequencing constraints: A proof of concept on the Argentinian Sign Language
Oct 26, 2023Automatic sign language recognition (SLR) is an important topic within the areas of human-computer interaction and machine learning. On the one hand, it poses a complex challenge that requires the intervention of various knowledge areas, such as video processing, image processing, intelligent systems and linguistics. On the other hand, robust recognition of sign language could assist in the translation process and the integration of hearing-impaired people, as well as the teaching of sign language for the hearing population. SLR systems usually employ Hidden Markov Models, Dynamic Time Warping or similar models to recognize signs. Such techniques exploit the sequential ordering of frames to reduce the number of hypothesis. This paper presents a general probabilistic model for sign classification that combines sub-classifiers based on different types of features such as position, movement and handshape. The model employs a bag-of-words approach in all classification steps, to explore the hypothesis that ordering is not essential for recognition. The proposed model achieved an accuracy rate of 97% on an Argentinian Sign Language dataset containing 64 classes of signs and 3200 samples, providing some evidence that indeed recognition without ordering is possible.
Handshape recognition for Argentinian Sign Language using ProbSom
Oct 26, 2023



Automatic sign language recognition is an important topic within the areas of human-computer interaction and machine learning. On the one hand, it poses a complex challenge that requires the intervention of various knowledge areas, such as video processing, image processing, intelligent systems and linguistics. On the other hand, robust recognition of sign language could assist in the translation process and the integration of hearing-impaired people. This paper offers two main contributions: first, the creation of a database of handshapes for the Argentinian Sign Language (LSA), which is a topic that has barely been discussed so far. Secondly, a technique for image processing, descriptor extraction and subsequent handshape classification using a supervised adaptation of self-organizing maps that is called ProbSom. This technique is compared to others in the state of the art, such as Support Vector Machines (SVM), Random Forests, and Neural Networks. The database that was built contains 800 images with 16 LSA handshapes, and is a first step towards building a comprehensive database of Argentinian signs. The ProbSom-based neural classifier, using the proposed descriptor, achieved an accuracy rate above 90%.
LSA64: An Argentinian Sign Language Dataset
Oct 26, 2023Automatic sign language recognition is a research area that encompasses human-computer interaction, computer vision and machine learning. Robust automatic recognition of sign language could assist in the translation process and the integration of hearing-impaired people, as well as the teaching of sign language to the hearing population. Sign languages differ significantly in different countries and even regions, and their syntax and semantics are different as well from those of written languages. While the techniques for automatic sign language recognition are mostly the same for different languages, training a recognition system for a new language requires having an entire dataset for that language. This paper presents a dataset of 64 signs from the Argentinian Sign Language (LSA). The dataset, called LSA64, contains 3200 videos of 64 different LSA signs recorded by 10 subjects, and is a first step towards building a comprehensive research-level dataset of Argentinian signs, specifically tailored to sign language recognition or other machine learning tasks. The subjects that performed the signs wore colored gloves to ease the hand tracking and segmentation steps, allowing experiments on the dataset to focus specifically on the recognition of signs. We also present a pre-processed version of the dataset, from which we computed statistics of movement, position and handshape of the signs.
Revisiting Data Augmentation for Rotational Invariance in Convolutional Neural Networks
Oct 12, 2023Convolutional Neural Networks (CNN) offer state of the art performance in various computer vision tasks. Many of those tasks require different subtypes of affine invariances (scale, rotational, translational) to image transformations. Convolutional layers are translation equivariant by design, but in their basic form lack invariances. In this work we investigate how best to include rotational invariance in a CNN for image classification. Our experiments show that networks trained with data augmentation alone can classify rotated images nearly as well as in the normal unrotated case; this increase in representational power comes only at the cost of training time. We also compare data augmentation versus two modified CNN models for achieving rotational invariance or equivariance, Spatial Transformer Networks and Group Equivariant CNNs, finding no significant accuracy increase with these specialized methods. In the case of data augmented networks, we also analyze which layers help the network to encode the rotational invariance, which is important for understanding its limitations and how to best retrain a network with data augmentation to achieve invariance to rotation.
User-Oriented Summaries Using a PSO Based Scoring Optimization Method
Jun 26, 2019
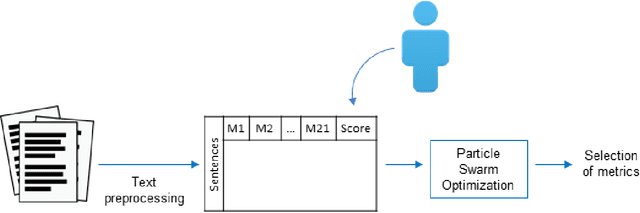
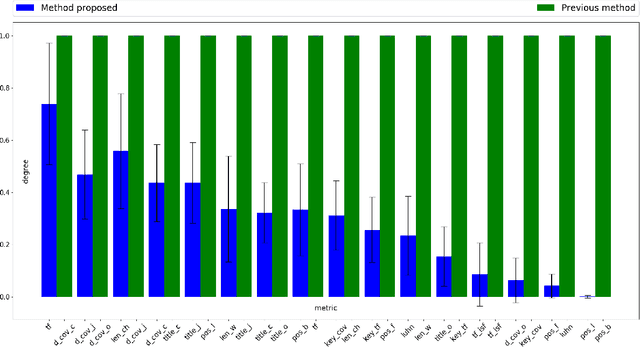
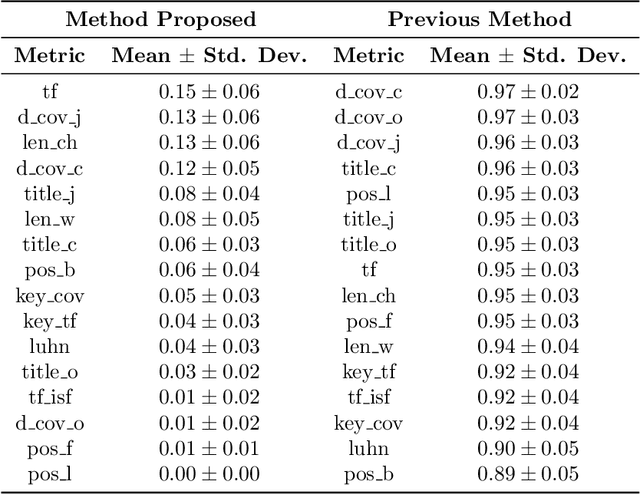
Automatic text summarization tools have a great impact on many fields, such as medicine, law, and scientific research in general. As information overload increases, automatic summaries allow handling the growing volume of documents, usually by assigning weights to the extracted phrases based on their significance in the expected summary. Obtaining the main contents of any given document in less time than it would take to do that manually is still an issue of interest. In~this~ article, a new method is presented that allows automatically generating extractive summaries from documents by adequately weighting sentence scoring features using \textit{Particle Swarm Optimization}. The key feature of the proposed method is the identification of those features that are closest to the criterion used by the individual when summarizing. The proposed method combines a binary representation and a continuous one, using an original variation of the technique developed by the authors of this paper. Our paper shows that using user labeled information in the training set helps to find better metrics and weights. The empirical results yield an improved accuracy compared to previous methods used in this field