 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUn análisis bibliométrico de la producción científica acerca del agrupamiento de trayectorias GPS
Apr 27, 2024Clustering algorithms or methods for GPS trajectories are in constant evolution due to the interest aroused in part of the scientific community. With the development of clustering algorithms considered traditional, improvements to these algorithms and even unique methods considered as "novelty" for science have emerged. This work aims to analyze the scientific production that exists around the topic "GPS trajectory clustering" by means of bibliometrics. Therefore, a total of 559 articles from the main collection of Scopus were analyzed, previously filtering the generated sample to discard any article that does not have a direct relationship with the topic to be analyzed. This analysis establishes an ideal environment for other disciplines and researchers, since it provides a current state of the trend of the subject of study in their field of research. -- Los algoritmos o m\'etodos de agrupamiento para trayectorias GPS se encuentran en constante evoluci\'on debido al inter\'es que despierta en parte de la comunidad cient\'ifica. Con el desarrollo de los algoritmos de agrupamiento considerados tradicionales han surgido mejoras a estos algoritmos e incluso m\'etodos \'unicos considerados como "novedad" para la ciencia. Este trabajo tiene como objetivo analizar la producci\'on cient\'ifica que existe alrededor del tema "agrupamiento de trayectorias GPS" mediante la bibliometr\'ia. Por lo tanto, fueron analizados un total de 559 art\'iculos de la colecci\'on principal de Scopus, realizando previamente un filtrado de la muestra generada para descartar todo aquel art\'iculo que no tenga una relaci\'on directa con el tema a analizar. Este an\'alisis establece un ambiente ideal para otras disciplinas e investigadores, ya que entrega un estado actual de la tendencia que lleva la tem\'atica de estudio en su campo de investigaci\'on.
User-Oriented Summaries Using a PSO Based Scoring Optimization Method
Jun 26, 2019
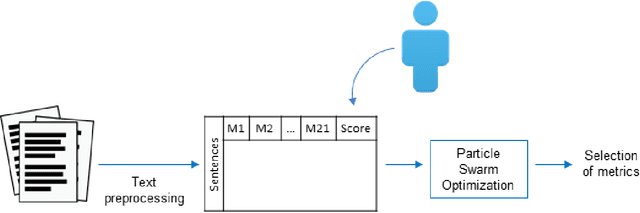
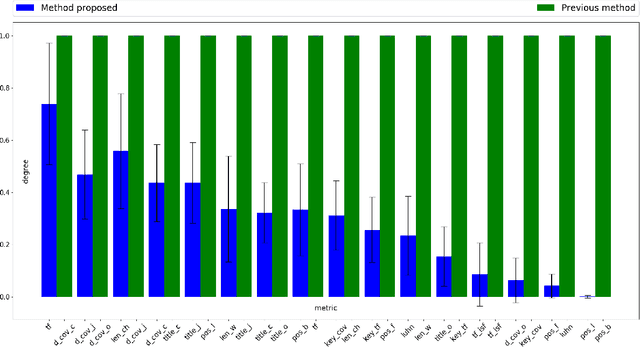
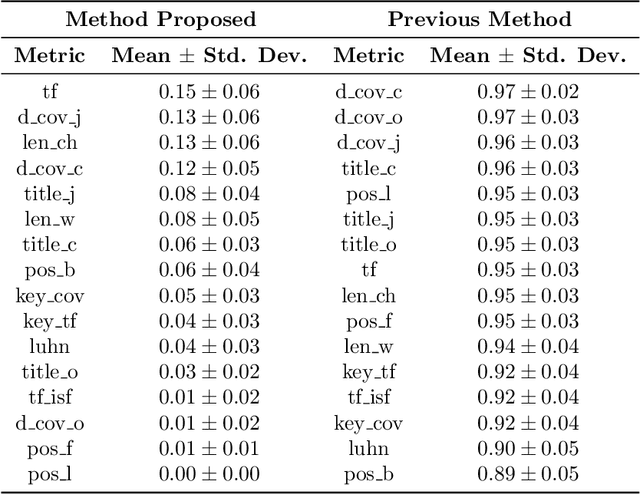
Automatic text summarization tools have a great impact on many fields, such as medicine, law, and scientific research in general. As information overload increases, automatic summaries allow handling the growing volume of documents, usually by assigning weights to the extracted phrases based on their significance in the expected summary. Obtaining the main contents of any given document in less time than it would take to do that manually is still an issue of interest. In~this~ article, a new method is presented that allows automatically generating extractive summaries from documents by adequately weighting sentence scoring features using \textit{Particle Swarm Optimization}. The key feature of the proposed method is the identification of those features that are closest to the criterion used by the individual when summarizing. The proposed method combines a binary representation and a continuous one, using an original variation of the technique developed by the authors of this paper. Our paper shows that using user labeled information in the training set helps to find better metrics and weights. The empirical results yield an improved accuracy compared to previous methods used in this field