 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Intent-Based Filtering for Multi-Party Conversations Using Knowledge Distillation from LLMs
Mar 21, 2025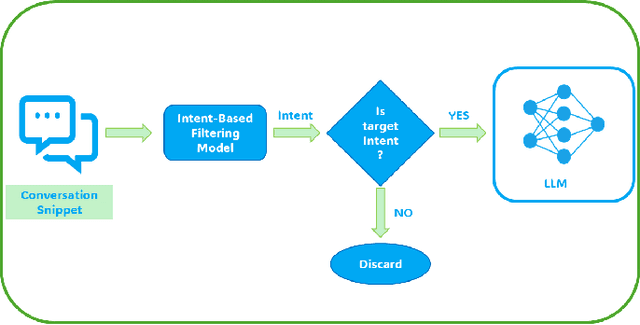
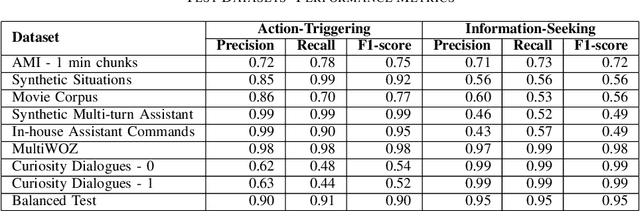
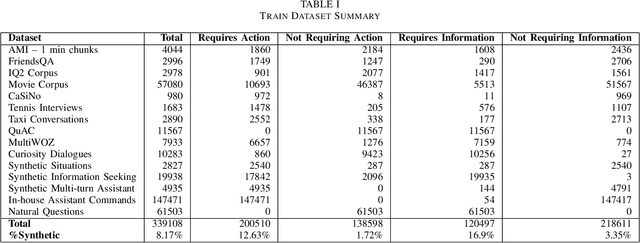

Large language models (LLMs) have showcased remarkable capabilities in conversational AI, enabling open-domain responses in chat-bots, as well as advanced processing of conversations like summarization, intent classification, and insights generation. However, these models are resource-intensive, demanding substantial memory and computational power. To address this, we propose a cost-effective solution that filters conversational snippets of interest for LLM processing, tailored to the target downstream application, rather than processing every snippet. In this work, we introduce an innovative approach that leverages knowledge distillation from LLMs to develop an intent-based filter for multi-party conversations, optimized for compute power constrained environments. Our method combines different strategies to create a diverse multi-party conversational dataset, that is annotated with the target intents and is then used to fine-tune the MobileBERT model for multi-label intent classification. This model achieves a balance between efficiency and performance, effectively filtering conversation snippets based on their intents. By passing only the relevant snippets to the LLM for further processing, our approach significantly reduces overall operational costs depending on the intents and the data distribution as demonstrated in our experiments.
Unsupervised Fine-Tuning Data Selection for ASR Using Self-Supervised Speech Models
Dec 03, 2022



Self-supervised learning (SSL) has been able to leverage unlabeled data to boost the performance of automatic speech recognition (ASR) models when we have access to only a small amount of transcribed speech data. However, this raises the question of which subset of the available unlabeled data should be selected for transcription. Our work investigates different unsupervised data selection techniques for fine-tuning the HuBERT model under a limited transcription budget. We investigate the impact of speaker diversity, gender bias, and topic diversity on the downstream ASR performance. We also devise two novel techniques for unsupervised data selection: pre-training loss based data selection and the perplexity of byte pair encoded clustered units (PBPE) and we show how these techniques compare to pure random data selection. Finally, we analyze the correlations between the inherent characteristics of the selected fine-tuning subsets as well as how these characteristics correlate with the resultant word error rate. We demonstrate the importance of token diversity, speaker diversity, and topic diversity in achieving the best performance in terms of WER.