 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Intent-Based Filtering for Multi-Party Conversations Using Knowledge Distillation from LLMs
Mar 21, 2025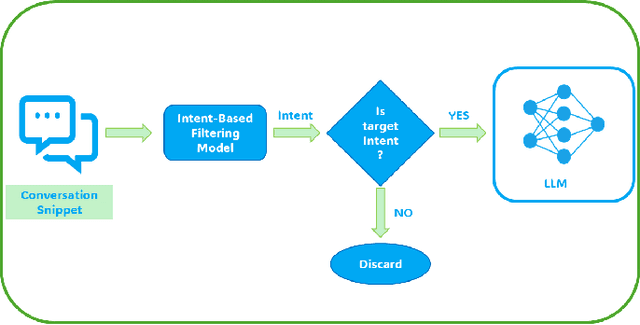
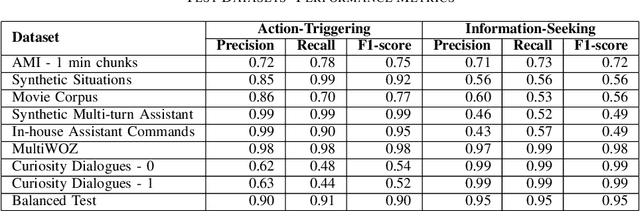
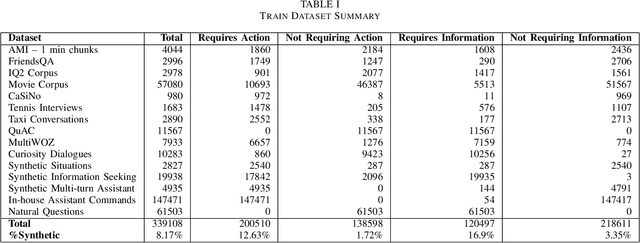

Large language models (LLMs) have showcased remarkable capabilities in conversational AI, enabling open-domain responses in chat-bots, as well as advanced processing of conversations like summarization, intent classification, and insights generation. However, these models are resource-intensive, demanding substantial memory and computational power. To address this, we propose a cost-effective solution that filters conversational snippets of interest for LLM processing, tailored to the target downstream application, rather than processing every snippet. In this work, we introduce an innovative approach that leverages knowledge distillation from LLMs to develop an intent-based filter for multi-party conversations, optimized for compute power constrained environments. Our method combines different strategies to create a diverse multi-party conversational dataset, that is annotated with the target intents and is then used to fine-tune the MobileBERT model for multi-label intent classification. This model achieves a balance between efficiency and performance, effectively filtering conversation snippets based on their intents. By passing only the relevant snippets to the LLM for further processing, our approach significantly reduces overall operational costs depending on the intents and the data distribution as demonstrated in our experiments.
Score Combination for Improved Parallel Corpus Filtering for Low Resource Conditions
Nov 16, 2020
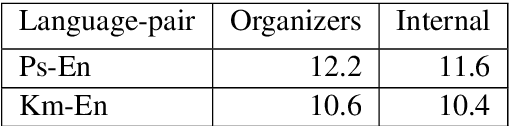

This paper describes our submission to the WMT20 sentence filtering task. We combine scores from (1) a custom LASER built for each source language, (2) a classifier built to distinguish positive and negative pairs by semantic alignment, and (3) the original scores included in the task devkit. For the mBART finetuning setup, provided by the organizers, our method shows 7% and 5% relative improvement over baseline, in sacreBLEU score on the test set for Pashto and Khmer respectively.
Synthetic Data for Neural Machine Translation of Spoken-Dialects
Nov 28, 2017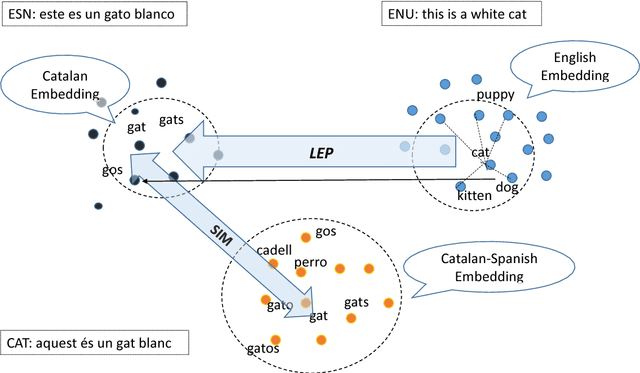
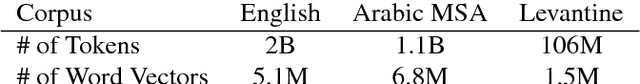
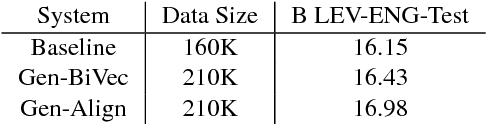

In this paper, we introduce a novel approach to generate synthetic data for training Neural Machine Translation systems. The proposed approach transforms a given parallel corpus between a written language and a target language to a parallel corpus between a spoken dialect variant and the target language. Our approach is language independent and can be used to generate data for any variant of the source language such as slang or spoken dialect or even for a different language that is closely related to the source language. The proposed approach is based on local embedding projection of distributed representations which utilizes monolingual embeddings to transform parallel data across language variants. We report experimental results on Levantine to English translation using Neural Machine Translation. We show that the generated data can improve a very large scale system by more than 2.8 Bleu points using synthetic spoken data which shows that it can be used to provide a reliable translation system for a spoken dialect that does not have sufficient parallel data.