 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Hybrid Parallelism for Large Language Models: Comparative Study and System Design Guide
Feb 09, 2026With the rapid growth of large language models (LLMs), a wide range of methods have been developed to distribute computation and memory across hardware devices for efficient training and inference. While existing surveys provide descriptive overviews of these techniques, systematic analysis of their benefits and trade offs and how such insights can inform principled methodology for designing optimal distributed systems remain limited. This paper offers a comprehensive review of collective operations and distributed parallel strategies, complemented by mathematical formulations to deepen theoretical understanding. We further examine hybrid parallelization designs, emphasizing communication computation overlap across different stages of model deployment, including both training and inference. Recent advances in automated search for optimal hybrid parallelization strategies using cost models are also discussed. Moreover, we present case studies with mainstream architecture categories to reveal empirical insights to guide researchers and practitioners in parallelism strategy selection. Finally, we highlight open challenges and limitations of current LLM training paradigms and outline promising directions for the next generation of large scale model development.
FLOP-Efficient Training: Early Stopping Based on Test-Time Compute Awareness
Jan 04, 2026Scaling training compute, measured in FLOPs, has long been shown to improve the accuracy of large language models, yet training remains resource-intensive. Prior work shows that increasing test-time compute (TTC)-for example through iterative sampling-can allow smaller models to rival or surpass much larger ones at lower overall cost. We introduce TTC-aware training, where an intermediate checkpoint and a corresponding TTC configuration can together match or exceed the accuracy of a fully trained model while requiring substantially fewer training FLOPs. Building on this insight, we propose an early stopping algorithm that jointly selects a checkpoint and TTC configuration to minimize training compute without sacrificing accuracy. To make this practical, we develop an efficient TTC evaluation method that avoids exhaustive search, and we formalize a break-even bound that identifies when increased inference compute compensates for reduced training compute. Experiments demonstrate up to 92\% reductions in training FLOPs while maintaining and sometimes remarkably improving accuracy. These results highlight a new perspective for balancing training and inference compute in model development, enabling faster deployment cycles and more frequent model refreshes. Codes will be publicly released.
A Distributed Generative AI Approach for Heterogeneous Multi-Domain Environments under Data Sharing constraints
Jul 17, 2025Federated Learning has gained increasing attention for its ability to enable multiple nodes to collaboratively train machine learning models without sharing their raw data. At the same time, Generative AI -- particularly Generative Adversarial Networks (GANs) -- have achieved remarkable success across a wide range of domains, such as healthcare, security, and Image Generation. However, training generative models typically requires large datasets and significant computational resources, which are often unavailable in real-world settings. Acquiring such resources can be costly and inefficient, especially when many underutilized devices -- such as IoT devices and edge devices -- with varying capabilities remain idle. Moreover, obtaining large datasets is challenging due to privacy concerns and copyright restrictions, as most devices are unwilling to share their data. To address these challenges, we propose a novel approach for decentralized GAN training that enables the utilization of distributed data and underutilized, low-capability devices while not sharing data in its raw form. Our approach is designed to tackle key challenges in decentralized environments, combining KLD-weighted Clustered Federated Learning to address the issues of data heterogeneity and multi-domain datasets, with Heterogeneous U-Shaped split learning to tackle the challenge of device heterogeneity under strict data sharing constraints -- ensuring that no labels or raw data, whether real or synthetic, are ever shared between nodes. Experimental results shows that our approach demonstrates consistent and significant improvements across key performance metrics, where it achieves 1.1x -- 2.2x higher image generation scores, an average 10% boost in classification metrics (up to 50% in multi-domain non-IID settings), in much lower latency compared to several benchmarks. Find our code at https://github.com/youssefga28/HuSCF-GAN.
Continuous Self-Improvement of Large Language Models by Test-time Training with Verifier-Driven Sample Selection
May 26, 2025Learning to adapt pretrained language models to unlabeled, out-of-distribution data is a critical challenge, as models often falter on structurally novel reasoning tasks even while excelling within their training distribution. We introduce a new framework called VDS-TTT - Verifier-Driven Sample Selection for Test-Time Training to efficiently address this. We use a learned verifier to score a pool of generated responses and select only from high ranking pseudo-labeled examples for fine-tuned adaptation. Specifically, for each input query our LLM generates N candidate answers; the verifier assigns a reliability score to each, and the response with the highest confidence and above a fixed threshold is paired with its query for test-time training. We fine-tune only low-rank LoRA adapter parameters, ensuring adaptation efficiency and fast convergence. Our proposed self-supervised framework is the first to synthesize verifier driven test-time training data for continuous self-improvement of the model. Experiments across three diverse benchmarks and three state-of-the-art LLMs demonstrate that VDS-TTT yields up to a 32.29% relative improvement over the base model and a 6.66% gain compared to verifier-based methods without test-time training, highlighting its effectiveness and efficiency for on-the-fly large language model adaptation.
On-Device Emoji Classifier Trained with GPT-based Data Augmentation for a Mobile Keyboard
Nov 06, 2024
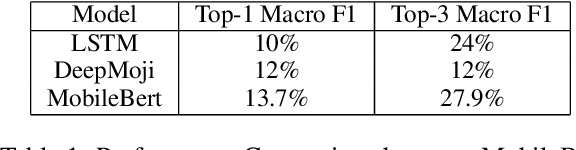
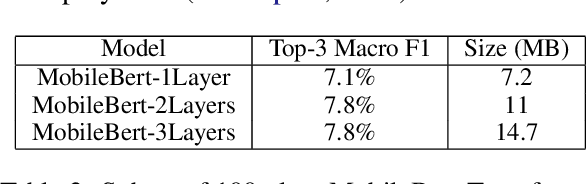

Emojis improve communication quality among smart-phone users that use mobile keyboards to exchange text. To predict emojis for users based on input text, we should consider the on-device low memory and time constraints, ensure that the on-device emoji classifier covers a wide range of emoji classes even though the emoji dataset is typically imbalanced, and adapt the emoji classifier output to user favorites. This paper proposes an on-device emoji classifier based on MobileBert with reasonable memory and latency requirements for SwiftKey. To account for the data imbalance, we utilize the widely used GPT to generate one or more tags for each emoji class. For each emoji and corresponding tags, we merge the original set with GPT-generated sentences and label them with this emoji without human intervention to alleviate the data imbalance. At inference time, we interpolate the emoji output with the user history for emojis for better emoji classifications. Results show that the proposed on-device emoji classifier deployed for SwiftKey increases the accuracy performance of emoji prediction particularly on rare emojis and emoji engagement.
Simply Trainable Nearest Neighbour Machine Translation with GPU Inference
Jul 29, 2024


Nearest neighbor machine translation is a successful approach for fast domain adaption, which interpolates the pre-trained transformers with domain-specific token-level k-nearest-neighbor (kNN) retrieval without retraining. Despite kNN MT's success, searching large reference corpus and fixed interpolation between the kNN and pre-trained model led to computational complexity and translation quality challenges. Among other papers, Dai et al. proposed methods to obtain a small number of reference samples dynamically for which they introduced a distance-aware interpolation method using an equation that includes free parameters. This paper proposes a simply trainable nearest neighbor machine translation and carry out inference experiments on GPU. Similar to Dai et al., we first adaptively construct a small datastore for each input sentence. Second, we train a single-layer network for the interpolation coefficient between the knnMT and pre-trained result to automatically interpolate in different domains. Experimental results on different domains show that our proposed method either improves or sometimes maintain the translation quality of methods in Dai et al. while being automatic. In addition, our GPU inference results demonstrate that knnMT can be integrated into GPUs with a drop of only 5% in terms of speed.
Federated Learning Based Multilingual Emoji Prediction In Clean and Attack Scenarios
Apr 10, 2023



Federated learning is a growing field in the machine learning community due to its decentralized and private design. Model training in federated learning is distributed over multiple clients giving access to lots of client data while maintaining privacy. Then, a server aggregates the training done on these multiple clients without access to their data, which could be emojis widely used in any social media service and instant messaging platforms to express users' sentiments. This paper proposes federated learning-based multilingual emoji prediction in both clean and attack scenarios. Emoji prediction data have been crawled from both Twitter and SemEval emoji datasets. This data is used to train and evaluate different transformer model sizes including a sparsely activated transformer with either the assumption of clean data in all clients or poisoned data via label flipping attack in some clients. Experimental results on these models show that federated learning in either clean or attacked scenarios performs similarly to centralized training in multilingual emoji prediction on seen and unseen languages under different data sources and distributions. Our trained transformers perform better than other techniques on the SemEval emoji dataset in addition to the privacy as well as distributed benefits of federated learning.
Deep Selector-JPEG: Adaptive JPEG Image Compression for Computer Vision in Image classification with Human Vision Criteria
Feb 19, 2023


With limited storage/bandwidth resources, input images to Computer Vision (CV) applications that use Deep Neural Networks (DNNs) are often encoded with JPEG that is tailored to Human Vision (HV). This paper presents Deep Selector-JPEG, an adaptive JPEG compression method that targets image classification while satisfying HV criteria. For each image, Deep Selector-JPEG selects adaptively a Quality Factor (QF) to compress the image so that a good trade-off between the Compression Ratio (CR) and DNN classifier Accuracy (Rate-Accuracy performance) can be achieved over a set of images for a variety of DNN classifiers while the MS-SSIM of such compressed image is greater than a threshold value predetermined by HV with a high probability. Deep Selector-JPEG is designed via light-weighted or heavy-weighted selector architectures. Experimental results show that in comparison with JPEG at the same CR, Deep Selector-JPEG achieves better Rate-Accuracy performance over the ImageNet validation set for all tested DNN classifiers with gains in classification accuracy between 0.2% and 1% at the same CRs while satisfying HV constraints. Deep Selector-JPEG can also roughly provide the original classification accuracy at higher CRs.
Fast Vocabulary Projection Method via Clustering for Multilingual Machine Translation on GPU
Aug 14, 2022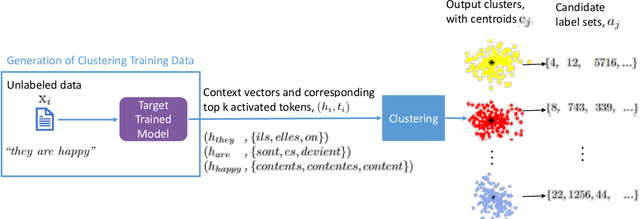
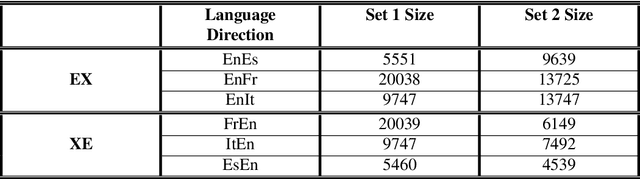
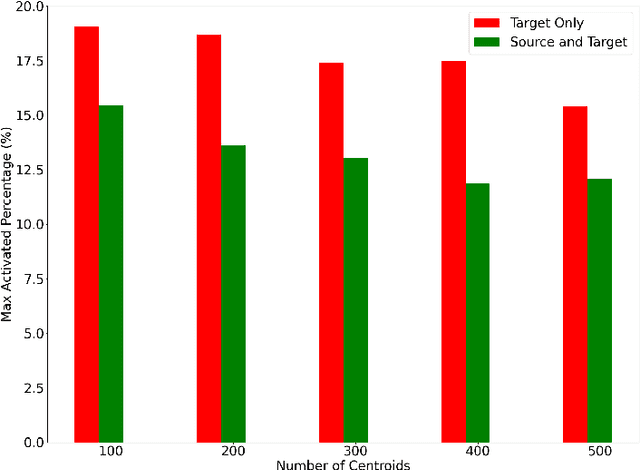
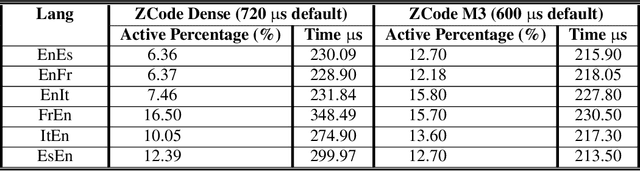
Multilingual Neural Machine Translation has been showing great success using transformer models. Deploying these models is challenging because they usually require large vocabulary (vocab) sizes for various languages. This limits the speed of predicting the output tokens in the last vocab projection layer. To alleviate these challenges, this paper proposes a fast vocabulary projection method via clustering which can be used for multilingual transformers on GPUs. First, we offline split the vocab search space into disjoint clusters given the hidden context vector of the decoder output, which results in much smaller vocab columns for vocab projection. Second, at inference time, the proposed method predicts the clusters and candidate active tokens for hidden context vectors at the vocab projection. This paper also includes analysis of different ways of building these clusters in multilingual settings. Our results show end-to-end speed gains in float16 GPU inference up to 25% while maintaining the BLEU score and slightly increasing memory cost. The proposed method speeds up the vocab projection step itself by up to 2.6x. We also conduct an extensive human evaluation to verify the proposed method preserves the quality of the translations from the original model.
High Performance Convolution Using Sparsity and Patterns for Inference in Deep Convolutional Neural Networks
Apr 16, 2021
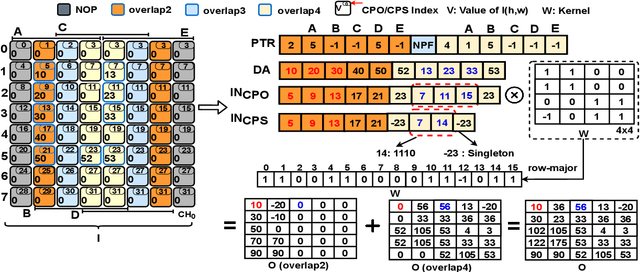
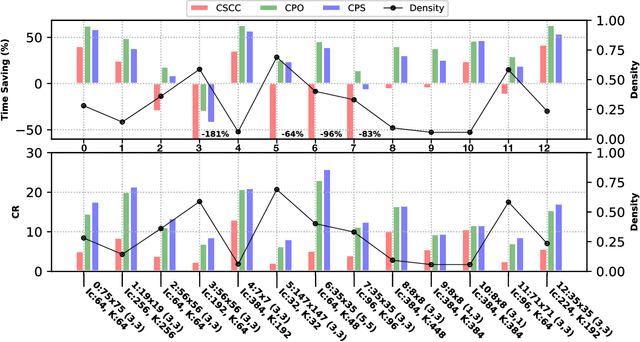
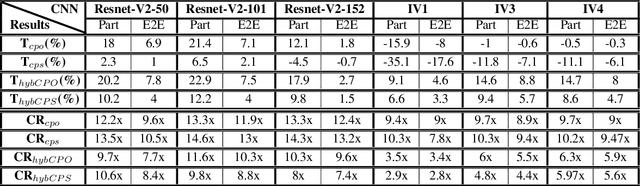
Deploying deep Convolutional Neural Networks (CNNs) is impacted by their memory footprint and speed requirements, which mainly come from convolution. Widely-used convolution algorithms, im2col and MEC, produce a lowered matrix from an activation map by redundantly storing the map's elements included at horizontal and/or vertical kernel overlappings without considering the sparsity of the map. Using the sparsity of the map, this paper proposes two new convolution algorithms dubbed Compressed Pattern Overlap (CPO) and Compressed Pattern Sets (CPS) that simultaneously decrease the memory footprint and increase the inference speed while preserving the accuracy. CPO recognizes non-zero elements (NZEs) at horizontal and vertical overlappings in the activation maps. CPS further improves the memory savings of CPO by compressing the index positions of neighboring NZEs. In both algorithms, channels/regions of the activation maps with all zeros are skipped. Then, CPO/CPS performs convolution via Sparse Matrix-Vector Multiplication (SpMv) done on their sparse representations. Experimental results conducted on CPUs show that average per-layer time savings reach up to 63% and Compression Ratio (CR) up to 26x with respect to im2col. In some layers, our average per layer CPO/CPS time savings are better by 28% and CR is better by 9.2x than the parallel implementation of MEC. For a given CNN's inference, we offline select for each convolution layer the best convolutional algorithm in terms of time between either CPO or CPS and im2col. Our algorithms were selected up to 56% of the non-pointwise convolutional layers. Our offline selections yield CNN inference time savings up to 9% and CR up to 10x.