 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Performance Convolution Using Sparsity and Patterns for Inference in Deep Convolutional Neural Networks
Paper and Code
Apr 16, 2021
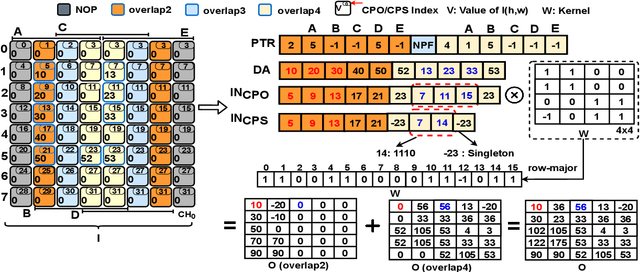
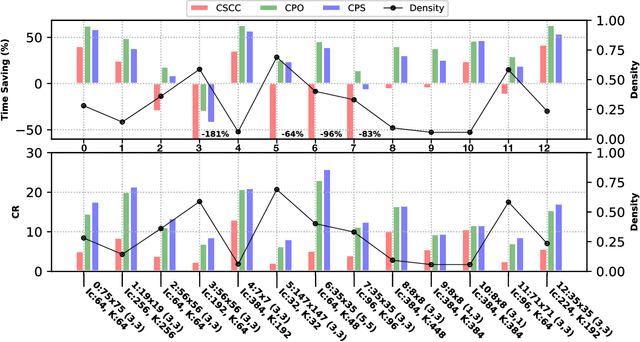
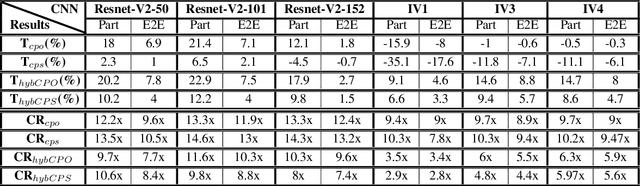
Deploying deep Convolutional Neural Networks (CNNs) is impacted by their memory footprint and speed requirements, which mainly come from convolution. Widely-used convolution algorithms, im2col and MEC, produce a lowered matrix from an activation map by redundantly storing the map's elements included at horizontal and/or vertical kernel overlappings without considering the sparsity of the map. Using the sparsity of the map, this paper proposes two new convolution algorithms dubbed Compressed Pattern Overlap (CPO) and Compressed Pattern Sets (CPS) that simultaneously decrease the memory footprint and increase the inference speed while preserving the accuracy. CPO recognizes non-zero elements (NZEs) at horizontal and vertical overlappings in the activation maps. CPS further improves the memory savings of CPO by compressing the index positions of neighboring NZEs. In both algorithms, channels/regions of the activation maps with all zeros are skipped. Then, CPO/CPS performs convolution via Sparse Matrix-Vector Multiplication (SpMv) done on their sparse representations. Experimental results conducted on CPUs show that average per-layer time savings reach up to 63% and Compression Ratio (CR) up to 26x with respect to im2col. In some layers, our average per layer CPO/CPS time savings are better by 28% and CR is better by 9.2x than the parallel implementation of MEC. For a given CNN's inference, we offline select for each convolution layer the best convolutional algorithm in terms of time between either CPO or CPS and im2col. Our algorithms were selected up to 56% of the non-pointwise convolutional layers. Our offline selections yield CNN inference time savings up to 9% and CR up to 10x.