 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalized Conditional Mutual Information Surrogate Loss for Deep Neural Classifiers
Jan 05, 2026In this paper, we propose a novel information theoretic surrogate loss; normalized conditional mutual information (NCMI); as a drop in alternative to the de facto cross-entropy (CE) for training deep neural network (DNN) based classifiers. We first observe that the model's NCMI is inversely proportional to its accuracy. Building on this insight, we introduce an alternating algorithm to efficiently minimize the NCMI. Across image recognition and whole-slide imaging (WSI) subtyping benchmarks, NCMI-trained models surpass state of the art losses by substantial margins at a computational cost comparable to that of CE. Notably, on ImageNet, NCMI yields a 2.77% top-1 accuracy improvement with ResNet-50 comparing to the CE; on CAMELYON-17, replacing CE with NCMI improves the macro-F1 by 8.6% over the strongest baseline. Gains are consistent across various architectures and batch sizes, suggesting that NCMI is a practical and competitive alternative to CE.
Deep Selector-JPEG: Adaptive JPEG Image Compression for Computer Vision in Image classification with Human Vision Criteria
Feb 19, 2023


With limited storage/bandwidth resources, input images to Computer Vision (CV) applications that use Deep Neural Networks (DNNs) are often encoded with JPEG that is tailored to Human Vision (HV). This paper presents Deep Selector-JPEG, an adaptive JPEG compression method that targets image classification while satisfying HV criteria. For each image, Deep Selector-JPEG selects adaptively a Quality Factor (QF) to compress the image so that a good trade-off between the Compression Ratio (CR) and DNN classifier Accuracy (Rate-Accuracy performance) can be achieved over a set of images for a variety of DNN classifiers while the MS-SSIM of such compressed image is greater than a threshold value predetermined by HV with a high probability. Deep Selector-JPEG is designed via light-weighted or heavy-weighted selector architectures. Experimental results show that in comparison with JPEG at the same CR, Deep Selector-JPEG achieves better Rate-Accuracy performance over the ImageNet validation set for all tested DNN classifiers with gains in classification accuracy between 0.2% and 1% at the same CRs while satisfying HV constraints. Deep Selector-JPEG can also roughly provide the original classification accuracy at higher CRs.
High Performance Convolution Using Sparsity and Patterns for Inference in Deep Convolutional Neural Networks
Apr 16, 2021
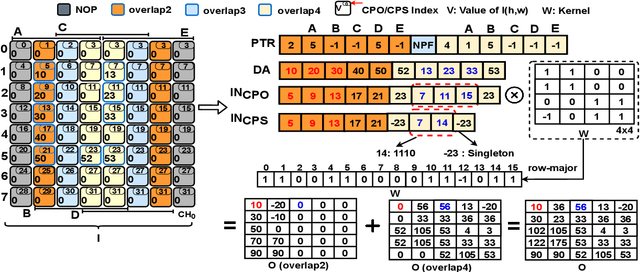
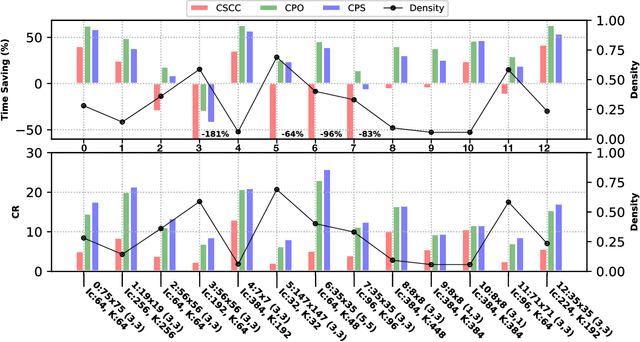
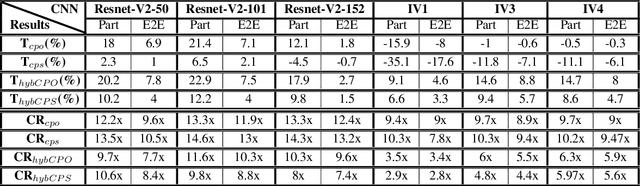
Deploying deep Convolutional Neural Networks (CNNs) is impacted by their memory footprint and speed requirements, which mainly come from convolution. Widely-used convolution algorithms, im2col and MEC, produce a lowered matrix from an activation map by redundantly storing the map's elements included at horizontal and/or vertical kernel overlappings without considering the sparsity of the map. Using the sparsity of the map, this paper proposes two new convolution algorithms dubbed Compressed Pattern Overlap (CPO) and Compressed Pattern Sets (CPS) that simultaneously decrease the memory footprint and increase the inference speed while preserving the accuracy. CPO recognizes non-zero elements (NZEs) at horizontal and vertical overlappings in the activation maps. CPS further improves the memory savings of CPO by compressing the index positions of neighboring NZEs. In both algorithms, channels/regions of the activation maps with all zeros are skipped. Then, CPO/CPS performs convolution via Sparse Matrix-Vector Multiplication (SpMv) done on their sparse representations. Experimental results conducted on CPUs show that average per-layer time savings reach up to 63% and Compression Ratio (CR) up to 26x with respect to im2col. In some layers, our average per layer CPO/CPS time savings are better by 28% and CR is better by 9.2x than the parallel implementation of MEC. For a given CNN's inference, we offline select for each convolution layer the best convolutional algorithm in terms of time between either CPO or CPS and im2col. Our algorithms were selected up to 56% of the non-pointwise convolutional layers. Our offline selections yield CNN inference time savings up to 9% and CR up to 10x.
Targeted Attack for Deep Hashing based Retrieval
May 08, 2020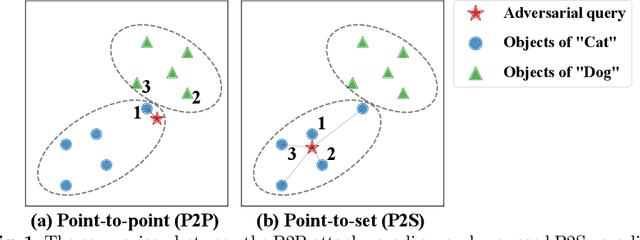
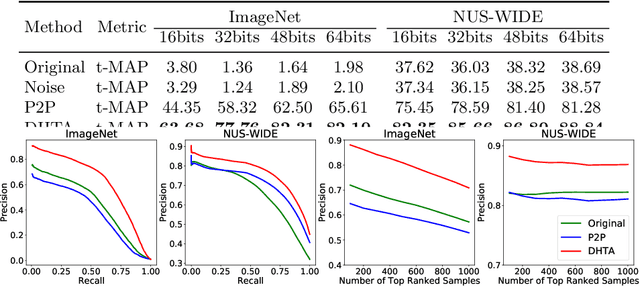
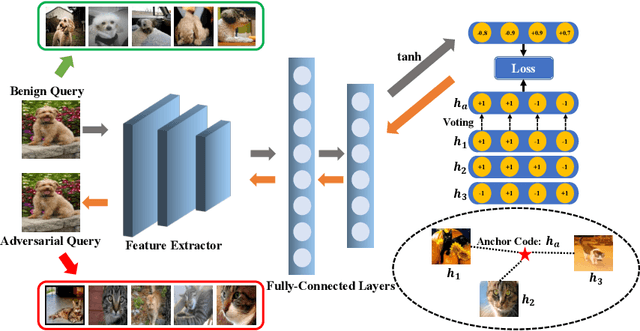
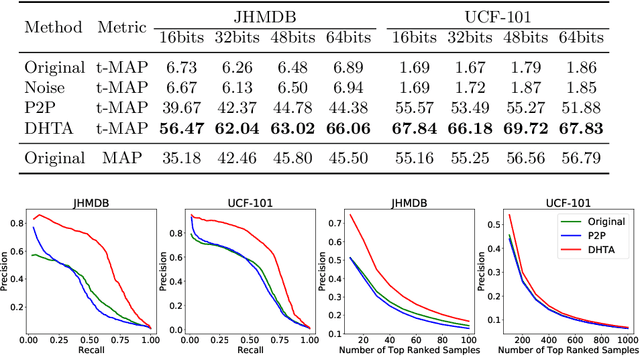
The deep hashing based retrieval method is widely adopted in large-scale image and video retrieval. However, there is little investigation on its security. In this paper, we propose a novel method, dubbed deep hashing targeted attack (DHTA), to study the targeted attack on such retrieval. Specifically, we first formulate the targeted attack as a point-to-set optimization, which minimizes the average distance between the hash code of an adversarial example and those of a set of objects with the target label. Then we design a novel component-voting scheme to obtain an anchor code as the representative of the set of hash codes of objects with the target label, whose optimality guarantee is also theoretically derived. To balance the performance and perceptibility, we propose to minimize the Hamming distance between the hash code of the adversarial example and the anchor code under the $\ell^\infty$ restriction on the perturbation. Extensive experiments verify that DHTA is effective in attacking both deep hashing based image retrieval and video retrieval.