 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Model Watermark via Reducing Parametric Vulnerability
Sep 09, 2023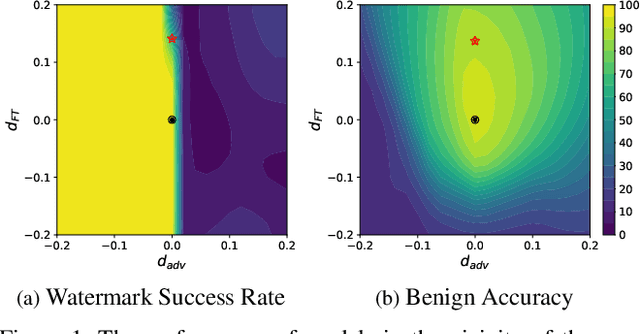
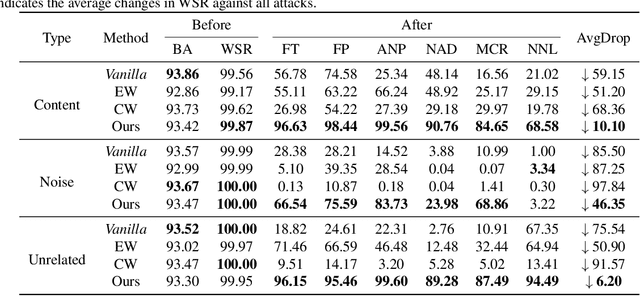
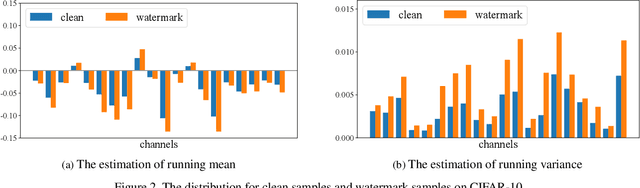
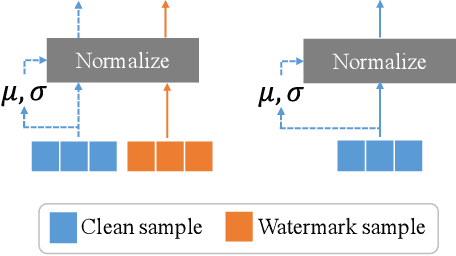
Deep neural networks are valuable assets considering their commercial benefits and huge demands for costly annotation and computation resources. To protect the copyright of DNNs, backdoor-based ownership verification becomes popular recently, in which the model owner can watermark the model by embedding a specific backdoor behavior before releasing it. The defenders (usually the model owners) can identify whether a suspicious third-party model is ``stolen'' from them based on the presence of the behavior. Unfortunately, these watermarks are proven to be vulnerable to removal attacks even like fine-tuning. To further explore this vulnerability, we investigate the parameter space and find there exist many watermark-removed models in the vicinity of the watermarked one, which may be easily used by removal attacks. Inspired by this finding, we propose a mini-max formulation to find these watermark-removed models and recover their watermark behavior. Extensive experiments demonstrate that our method improves the robustness of the model watermarking against parametric changes and numerous watermark-removal attacks. The codes for reproducing our main experiments are available at \url{https://github.com/GuanhaoGan/robust-model-watermarking}.
An Efficient Virtual Data Generation Method for Reducing Communication in Federated Learning
Jun 29, 2023



Communication overhead is one of the major challenges in Federated Learning(FL). A few classical schemes assume the server can extract the auxiliary information about training data of the participants from the local models to construct a central dummy dataset. The server uses the dummy dataset to finetune aggregated global model to achieve the target test accuracy in fewer communication rounds. In this paper, we summarize the above solutions into a data-based communication-efficient FL framework. The key of the proposed framework is to design an efficient extraction module(EM) which ensures the dummy dataset has a positive effect on finetuning aggregated global model. Different from the existing methods that use generator to design EM, our proposed method, FedINIBoost borrows the idea of gradient match to construct EM. Specifically, FedINIBoost builds a proxy dataset of the real dataset in two steps for each participant at each communication round. Then the server aggregates all the proxy datasets to form a central dummy dataset, which is used to finetune aggregated global model. Extensive experiments verify the superiority of our method compared with the existing classical method, FedAVG, FedProx, Moon and FedFTG. Moreover, FedINIBoost plays a significant role in finetuning the performance of aggregated global model at the initial stage of FL.
When Adversarial Training Meets Vision Transformers: Recipes from Training to Architecture
Oct 14, 2022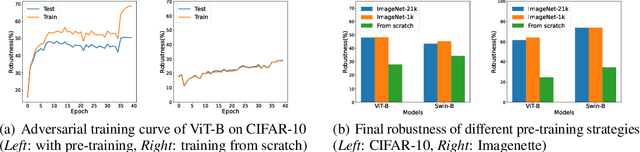
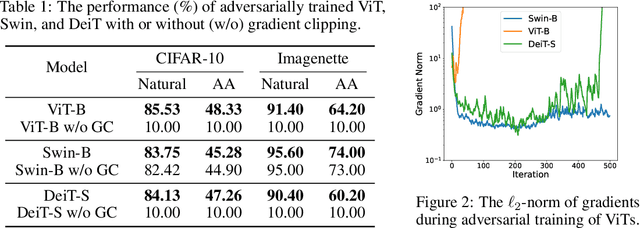
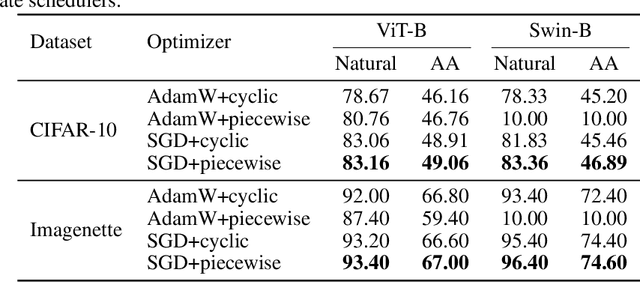
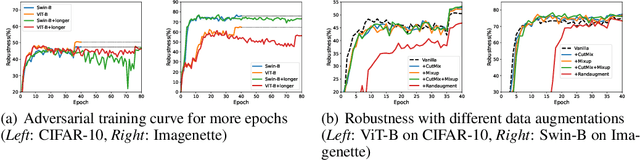
Vision Transformers (ViTs) have recently achieved competitive performance in broad vision tasks. Unfortunately, on popular threat models, naturally trained ViTs are shown to provide no more adversarial robustness than convolutional neural networks (CNNs). Adversarial training is still required for ViTs to defend against such adversarial attacks. In this paper, we provide the first and comprehensive study on the adversarial training recipe of ViTs via extensive evaluation of various training techniques across benchmark datasets. We find that pre-training and SGD optimizer are necessary for ViTs' adversarial training. Further considering ViT as a new type of model architecture, we investigate its adversarial robustness from the perspective of its unique architectural components. We find, when randomly masking gradients from some attention blocks or masking perturbations on some patches during adversarial training, the adversarial robustness of ViTs can be remarkably improved, which may potentially open up a line of work to explore the architectural information inside the newly designed models like ViTs. Our code is available at https://github.com/mo666666/When-Adversarial-Training-Meets-Vision-Transformers.
On the Effectiveness of Adversarial Training against Backdoor Attacks
Feb 22, 2022

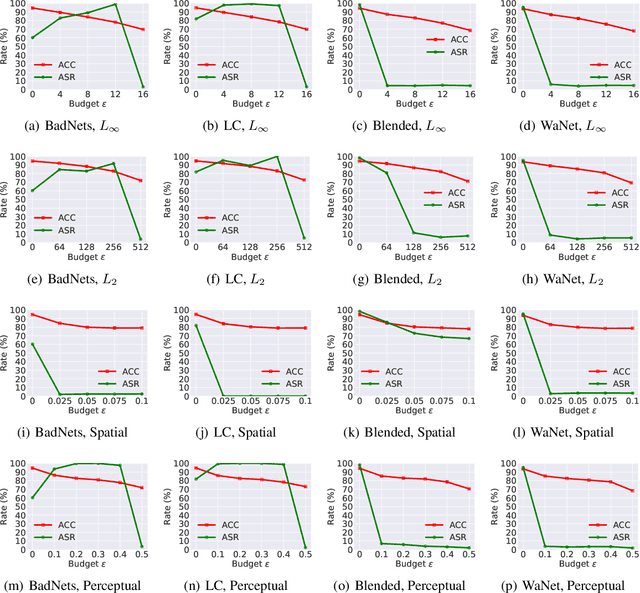
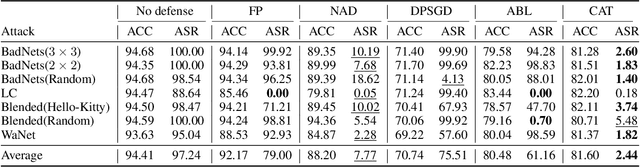
DNNs' demand for massive data forces practitioners to collect data from the Internet without careful check due to the unacceptable cost, which brings potential risks of backdoor attacks. A backdoored model always predicts a target class in the presence of a predefined trigger pattern, which can be easily realized via poisoning a small amount of data. In general, adversarial training is believed to defend against backdoor attacks since it helps models to keep their prediction unchanged even if we perturb the input image (as long as within a feasible range). Unfortunately, few previous studies succeed in doing so. To explore whether adversarial training could defend against backdoor attacks or not, we conduct extensive experiments across different threat models and perturbation budgets, and find the threat model in adversarial training matters. For instance, adversarial training with spatial adversarial examples provides notable robustness against commonly-used patch-based backdoor attacks. We further propose a hybrid strategy which provides satisfactory robustness across different backdoor attacks.
Adversarial Neuron Pruning Purifies Backdoored Deep Models
Oct 27, 2021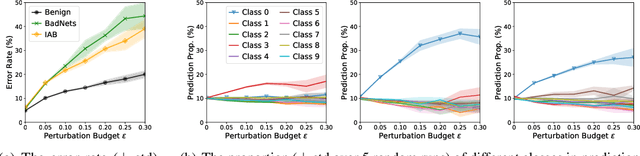



As deep neural networks (DNNs) are growing larger, their requirements for computational resources become huge, which makes outsourcing training more popular. Training in a third-party platform, however, may introduce potential risks that a malicious trainer will return backdoored DNNs, which behave normally on clean samples but output targeted misclassifications whenever a trigger appears at the test time. Without any knowledge of the trigger, it is difficult to distinguish or recover benign DNNs from backdoored ones. In this paper, we first identify an unexpected sensitivity of backdoored DNNs, that is, they are much easier to collapse and tend to predict the target label on clean samples when their neurons are adversarially perturbed. Based on these observations, we propose a novel model repairing method, termed Adversarial Neuron Pruning (ANP), which prunes some sensitive neurons to purify the injected backdoor. Experiments show, even with only an extremely small amount of clean data (e.g., 1%), ANP effectively removes the injected backdoor without causing obvious performance degradation.
Clean-label Backdoor Attack against Deep Hashing based Retrieval
Sep 18, 2021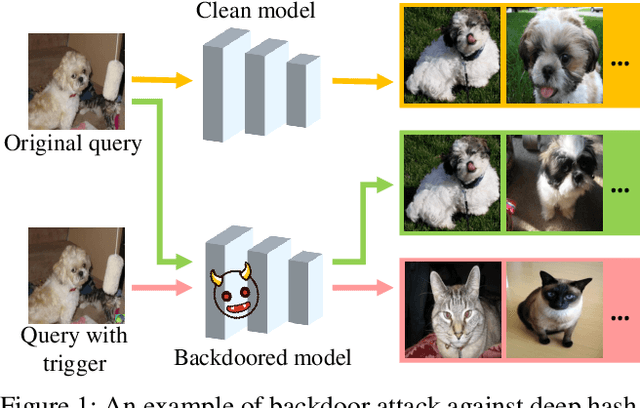
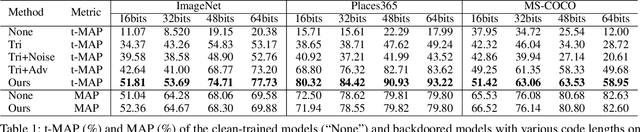
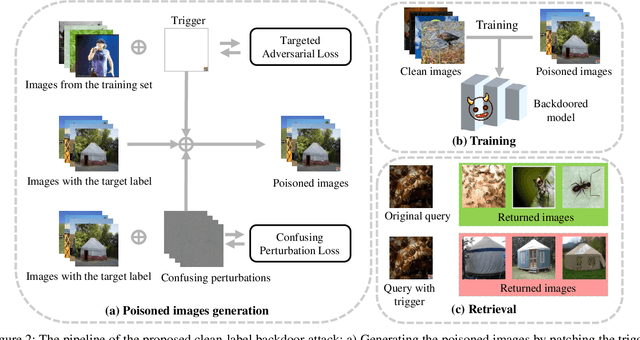
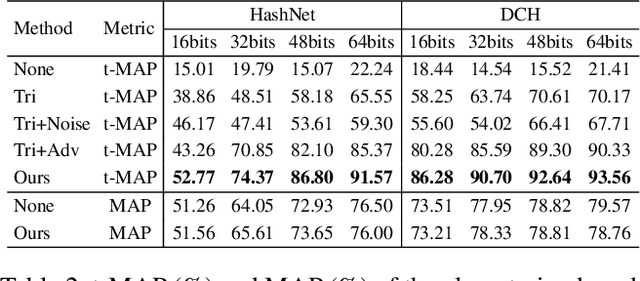
Deep hashing has become a popular method in large-scale image retrieval due to its computational and storage efficiency. However, recent works raise the security concerns of deep hashing. Although existing works focus on the vulnerability of deep hashing in terms of adversarial perturbations, we identify a more pressing threat, backdoor attack, when the attacker has access to the training data. A backdoored deep hashing model behaves normally on original query images, while returning the images with the target label when the trigger presents, which makes the attack hard to be detected. In this paper, we uncover this security concern by utilizing clean-label data poisoning. To the best of our knowledge, this is the first attempt at the backdoor attack against deep hashing models. To craft the poisoned images, we first generate the targeted adversarial patch as the backdoor trigger. Furthermore, we propose the confusing perturbations to disturb the hashing code learning, such that the hashing model can learn more about the trigger. The confusing perturbations are imperceptible and generated by dispersing the images with the target label in the Hamming space. We have conducted extensive experiments to verify the efficacy of our backdoor attack under various settings. For instance, it can achieve 63% targeted mean average precision on ImageNet under 48 bits code length with only 40 poisoned images.
Temporal Calibrated Regularization for Robust Noisy Label Learning
Jul 01, 2020
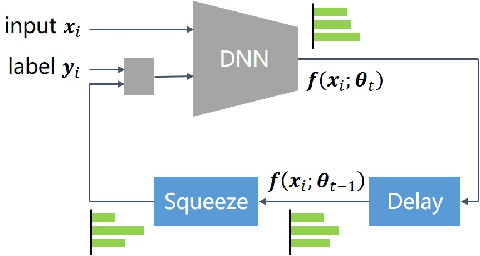
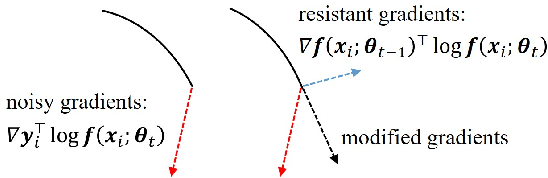
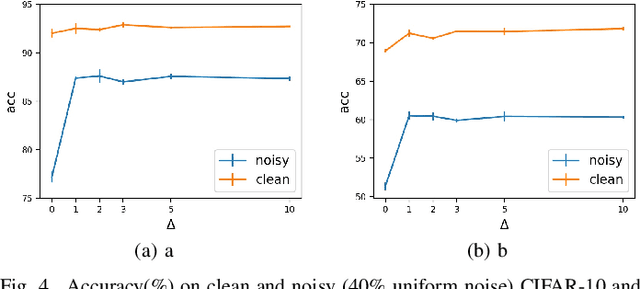
Deep neural networks (DNNs) exhibit great success on many tasks with the help of large-scale well annotated datasets. However, labeling large-scale data can be very costly and error-prone so that it is difficult to guarantee the annotation quality (i.e., having noisy labels). Training on these noisy labeled datasets may adversely deteriorate their generalization performance. Existing methods either rely on complex training stage division or bring too much computation for marginal performance improvement. In this paper, we propose a Temporal Calibrated Regularization (TCR), in which we utilize the original labels and the predictions in the previous epoch together to make DNN inherit the simple pattern it has learned with little overhead. We conduct extensive experiments on various neural network architectures and datasets, and find that it consistently enhances the robustness of DNNs to label noise.
Targeted Attack for Deep Hashing based Retrieval
May 08, 2020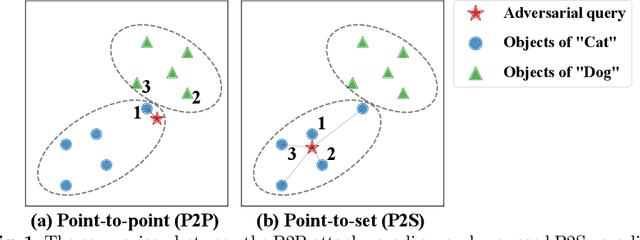
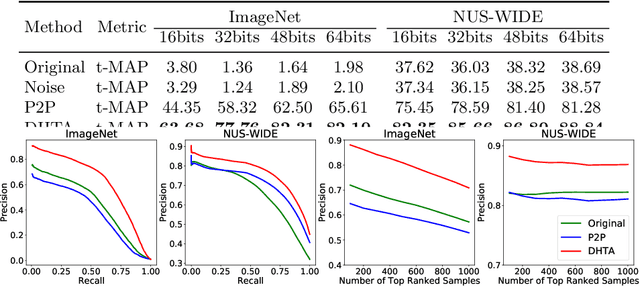
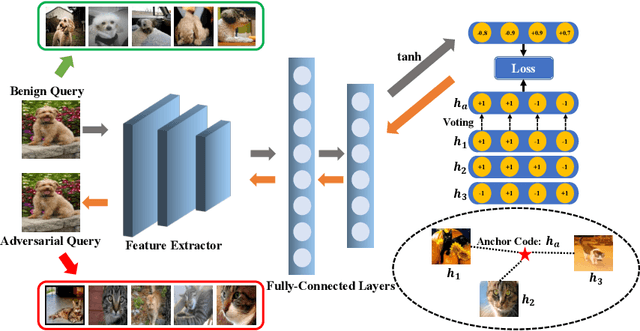
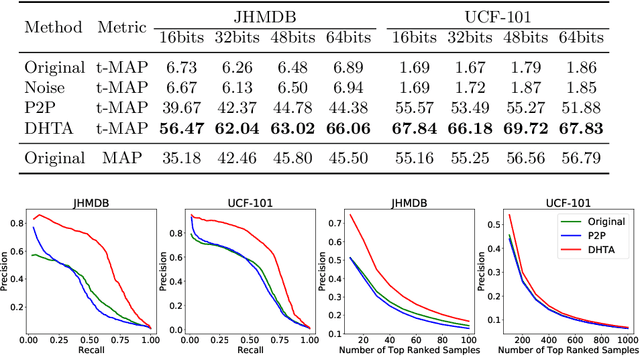
The deep hashing based retrieval method is widely adopted in large-scale image and video retrieval. However, there is little investigation on its security. In this paper, we propose a novel method, dubbed deep hashing targeted attack (DHTA), to study the targeted attack on such retrieval. Specifically, we first formulate the targeted attack as a point-to-set optimization, which minimizes the average distance between the hash code of an adversarial example and those of a set of objects with the target label. Then we design a novel component-voting scheme to obtain an anchor code as the representative of the set of hash codes of objects with the target label, whose optimality guarantee is also theoretically derived. To balance the performance and perceptibility, we propose to minimize the Hamming distance between the hash code of the adversarial example and the anchor code under the $\ell^\infty$ restriction on the perturbation. Extensive experiments verify that DHTA is effective in attacking both deep hashing based image retrieval and video retrieval.
Revisiting Loss Landscape for Adversarial Robustness
Apr 13, 2020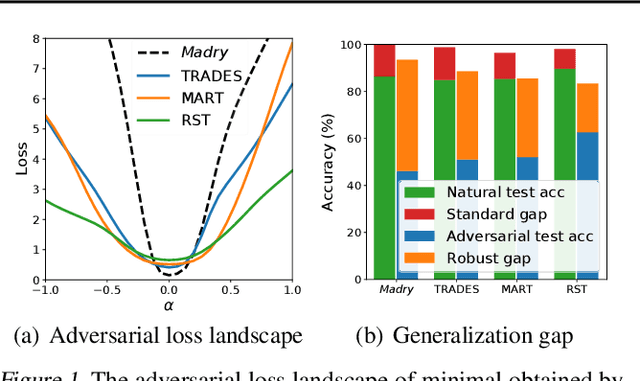



The study on improving the robustness of deep neural networks against adversarial examples grows rapidly in recent years. Among them, adversarial training is the most promising one, based on which, a lot of improvements have been developed, such as adding regularizations or leveraging unlabeled data. However, these improvements seem to come from isolated perspectives, so that we are curious about if there is something in common behind them. In this paper, we investigate the surface geometry of several well-recognized adversarial training variants, and reveal that their adversarial loss landscape is closely related to the adversarially robust generalization, i.e., the flatter the adversarial loss landscape, the smaller the adversarially robust generalization gap. Based on this finding, we then propose a simple yet effective module, Adversarial Weight Perturbation (AWP), to directly regularize the flatness of the adversarial loss landscape in the adversarial training framework. Extensive experiments demonstrate that AWP indeed owns flatter landscape and can be easily incorporated into various adversarial training variants to enhance their adversarial robustness further.
Matrix Smoothing: A Regularization for DNN with Transition Matrix under Noisy Labels
Mar 26, 2020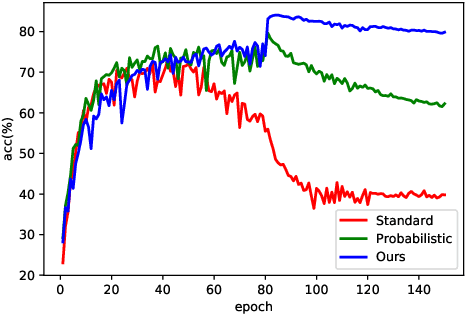
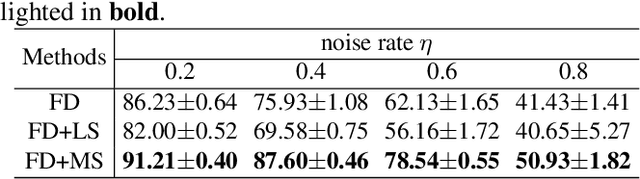
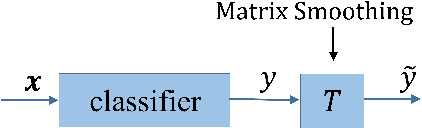
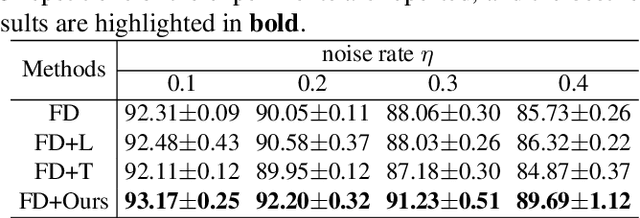
Training deep neural networks (DNNs) in the presence of noisy labels is an important and challenging task. Probabilistic modeling, which consists of a classifier and a transition matrix, depicts the transformation from true labels to noisy labels and is a promising approach. However, recent probabilistic methods directly apply transition matrix to DNN, neglect DNN's susceptibility to overfitting, and achieve unsatisfactory performance, especially under the uniform noise. In this paper, inspired by label smoothing, we proposed a novel method, in which a smoothed transition matrix is used for updating DNN, to restrict the overfitting of DNN in probabilistic modeling. Our method is termed Matrix Smoothing. We also empirically demonstrate that our method not only improves the robustness of probabilistic modeling significantly, but also even obtains a better estimation of the transition matrix.