 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClean-label Backdoor Attack against Deep Hashing based Retrieval
Paper and Code
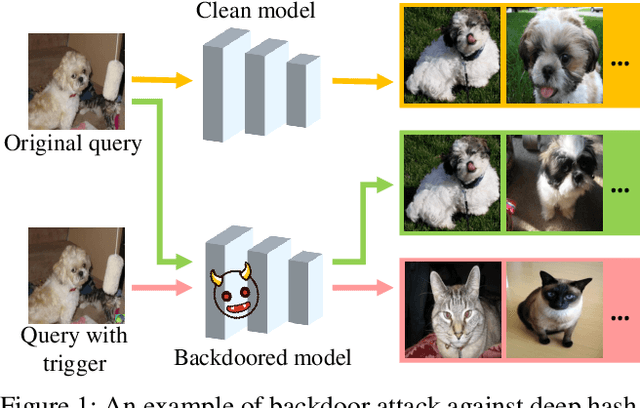
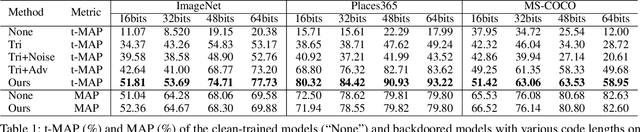
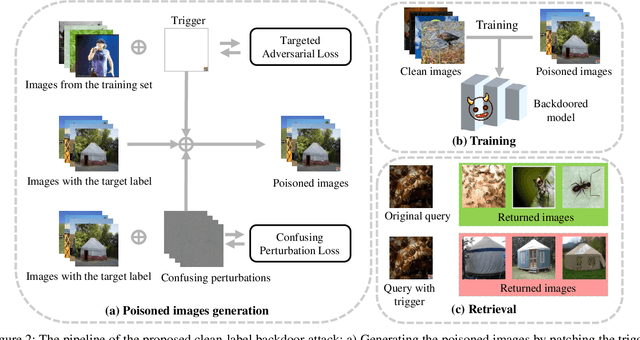
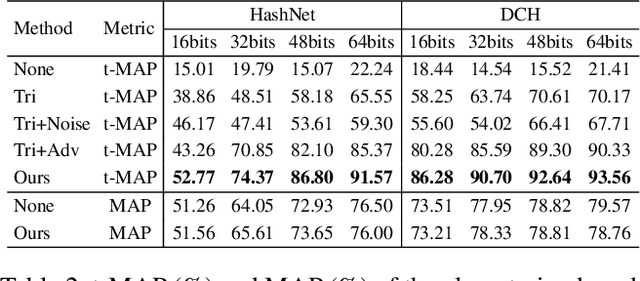
Deep hashing has become a popular method in large-scale image retrieval due to its computational and storage efficiency. However, recent works raise the security concerns of deep hashing. Although existing works focus on the vulnerability of deep hashing in terms of adversarial perturbations, we identify a more pressing threat, backdoor attack, when the attacker has access to the training data. A backdoored deep hashing model behaves normally on original query images, while returning the images with the target label when the trigger presents, which makes the attack hard to be detected. In this paper, we uncover this security concern by utilizing clean-label data poisoning. To the best of our knowledge, this is the first attempt at the backdoor attack against deep hashing models. To craft the poisoned images, we first generate the targeted adversarial patch as the backdoor trigger. Furthermore, we propose the confusing perturbations to disturb the hashing code learning, such that the hashing model can learn more about the trigger. The confusing perturbations are imperceptible and generated by dispersing the images with the target label in the Hamming space. We have conducted extensive experiments to verify the efficacy of our backdoor attack under various settings. For instance, it can achieve 63% targeted mean average precision on ImageNet under 48 bits code length with only 40 poisoned images.