 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Model Watermark via Reducing Parametric Vulnerability
Sep 09, 2023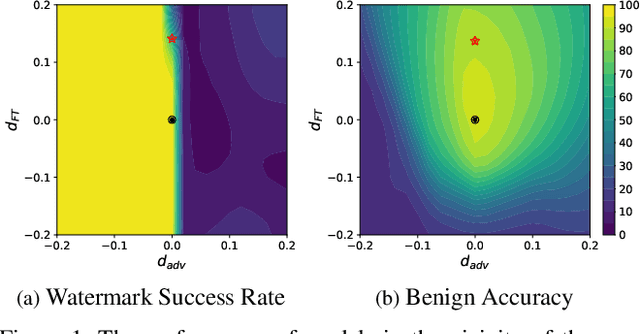
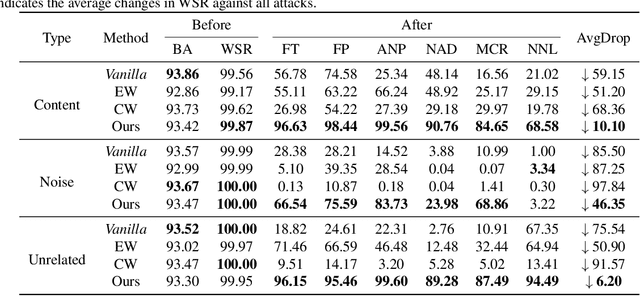
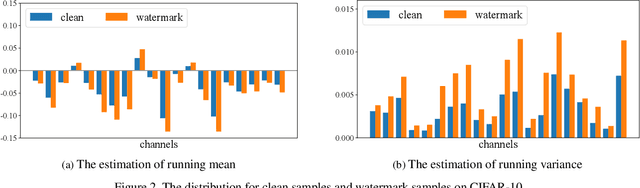
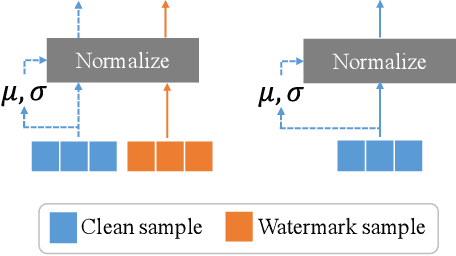
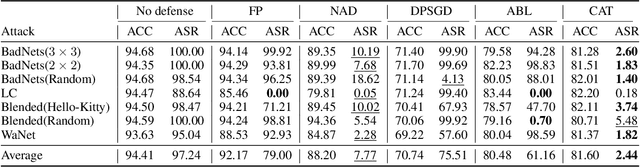
Deep neural networks are valuable assets considering their commercial benefits and huge demands for costly annotation and computation resources. To protect the copyright of DNNs, backdoor-based ownership verification becomes popular recently, in which the model owner can watermark the model by embedding a specific backdoor behavior before releasing it. The defenders (usually the model owners) can identify whether a suspicious third-party model is ``stolen'' from them based on the presence of the behavior. Unfortunately, these watermarks are proven to be vulnerable to removal attacks even like fine-tuning. To further explore this vulnerability, we investigate the parameter space and find there exist many watermark-removed models in the vicinity of the watermarked one, which may be easily used by removal attacks. Inspired by this finding, we propose a mini-max formulation to find these watermark-removed models and recover their watermark behavior. Extensive experiments demonstrate that our method improves the robustness of the model watermarking against parametric changes and numerous watermark-removal attacks. The codes for reproducing our main experiments are available at \url{https://github.com/GuanhaoGan/robust-model-watermarking}.
On the Effectiveness of Adversarial Training against Backdoor Attacks
Feb 22, 2022

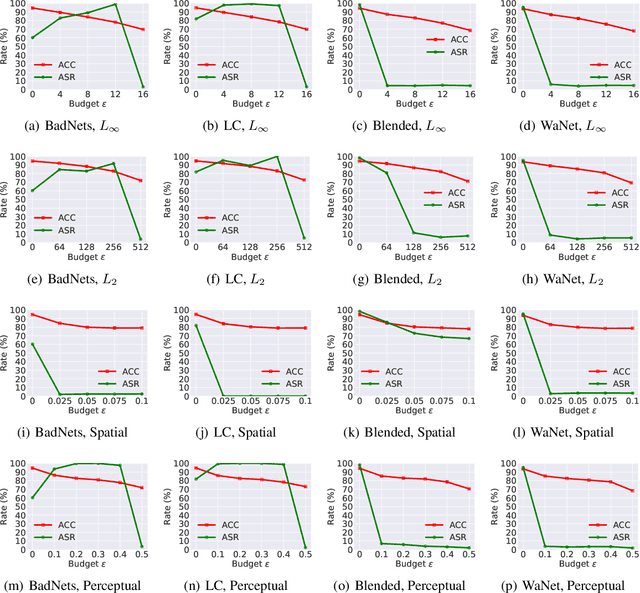
DNNs' demand for massive data forces practitioners to collect data from the Internet without careful check due to the unacceptable cost, which brings potential risks of backdoor attacks. A backdoored model always predicts a target class in the presence of a predefined trigger pattern, which can be easily realized via poisoning a small amount of data. In general, adversarial training is believed to defend against backdoor attacks since it helps models to keep their prediction unchanged even if we perturb the input image (as long as within a feasible range). Unfortunately, few previous studies succeed in doing so. To explore whether adversarial training could defend against backdoor attacks or not, we conduct extensive experiments across different threat models and perturbation budgets, and find the threat model in adversarial training matters. For instance, adversarial training with spatial adversarial examples provides notable robustness against commonly-used patch-based backdoor attacks. We further propose a hybrid strategy which provides satisfactory robustness across different backdoor attacks.