 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross Domain LifeLong Sequential Modeling for Online Click-Through Rate Prediction
Dec 11, 2023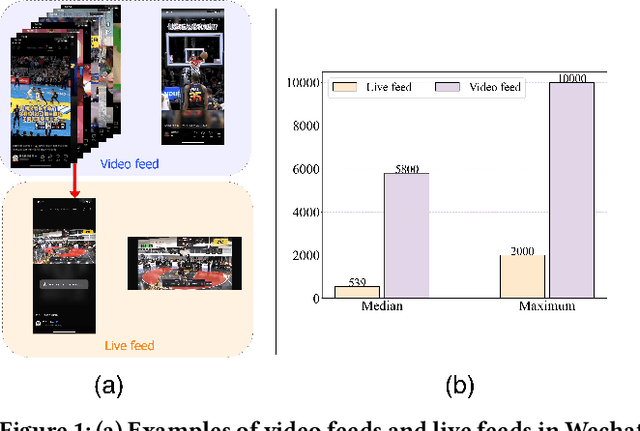

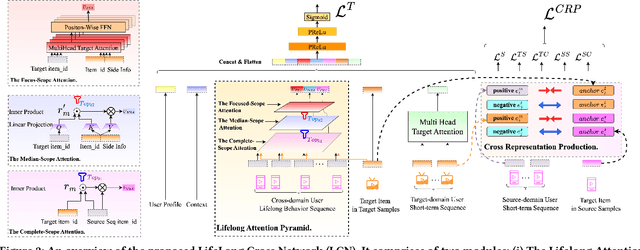
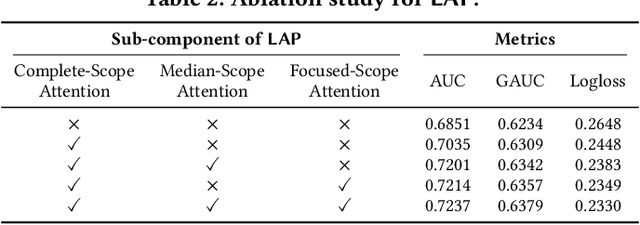
Deep neural networks (DNNs) that incorporated lifelong sequential modeling (LSM) have brought great success to recommendation systems in various social media platforms. While continuous improvements have been made in domain-specific LSM, limited work has been done in cross-domain LSM, which considers modeling of lifelong sequences of both target domain and source domain. In this paper, we propose Lifelong Cross Network (LCN) to incorporate cross-domain LSM to improve the click-through rate (CTR) prediction in the target domain. The proposed LCN contains a LifeLong Attention Pyramid (LAP) module that comprises of three levels of cascaded attentions to effectively extract interest representations with respect to the candidate item from lifelong sequences. We also propose Cross Representation Production (CRP) module to enforce additional supervision on the learning and alignment of cross-domain representations so that they can be better reused on learning of the CTR prediction in the target domain. We conducted extensive experiments on WeChat Channels industrial dataset as well as on benchmark dataset. Results have revealed that the proposed LCN outperforms existing work in terms of both prediction accuracy and online performance.
Temporal Calibrated Regularization for Robust Noisy Label Learning
Jul 01, 2020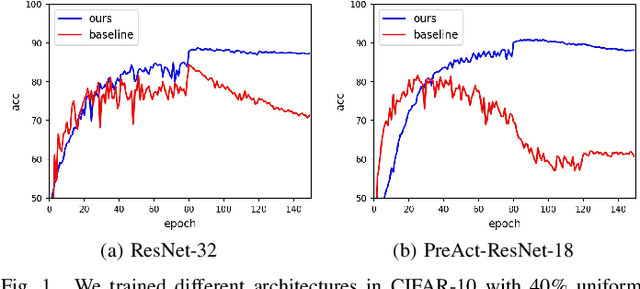
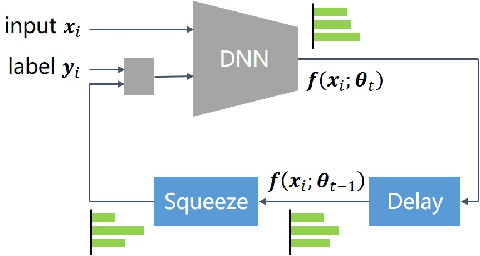
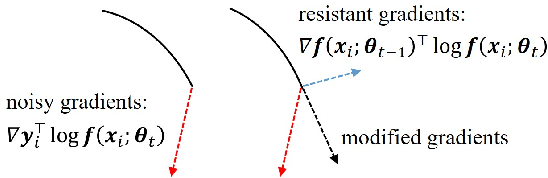
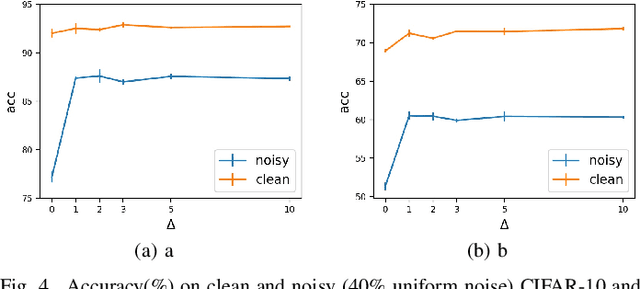
Deep neural networks (DNNs) exhibit great success on many tasks with the help of large-scale well annotated datasets. However, labeling large-scale data can be very costly and error-prone so that it is difficult to guarantee the annotation quality (i.e., having noisy labels). Training on these noisy labeled datasets may adversely deteriorate their generalization performance. Existing methods either rely on complex training stage division or bring too much computation for marginal performance improvement. In this paper, we propose a Temporal Calibrated Regularization (TCR), in which we utilize the original labels and the predictions in the previous epoch together to make DNN inherit the simple pattern it has learned with little overhead. We conduct extensive experiments on various neural network architectures and datasets, and find that it consistently enhances the robustness of DNNs to label noise.
Arena: a toolkit for Multi-Agent Reinforcement Learning
Jul 20, 2019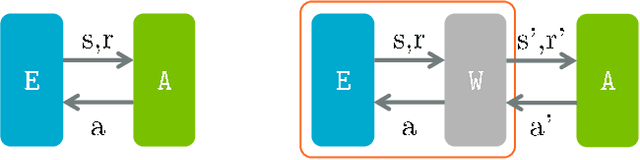
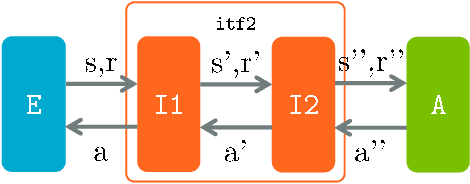
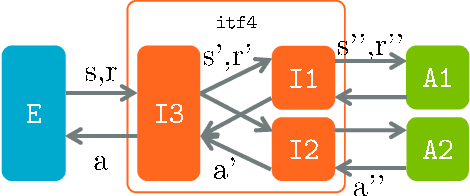

We introduce Arena, a toolkit for multi-agent reinforcement learning (MARL) research. In MARL, it usually requires customizing observations, rewards and actions for each agent, changing cooperative-competitive agent-interaction, and playing with/against a third-party agent, etc. We provide a novel modular design, called Interface, for manipulating such routines in essentially two ways: 1) Different interfaces can be concatenated and combined, which extends the OpenAI Gym Wrappers concept to MARL scenarios. 2) During MARL training or testing, interfaces can be embedded in either wrapped OpenAI Gym compatible Environments or raw environment compatible Agents. We offer off-the-shelf interfaces for several popular MARL platforms, including StarCraft II, Pommerman, ViZDoom, Soccer, etc. The interfaces effectively support self-play RL and cooperative-competitive hybrid MARL. Also, Arena can be conveniently extended to your own favorite MARL platform.
Learning to Run challenge solutions: Adapting reinforcement learning methods for neuromusculoskeletal environments
Apr 02, 2018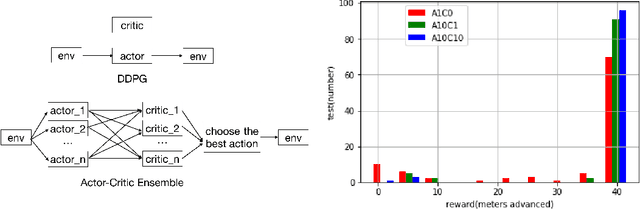

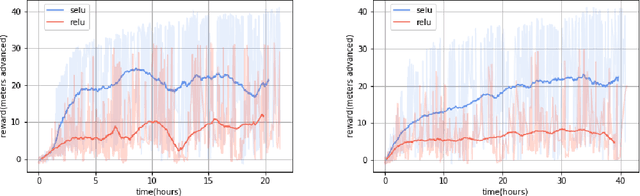
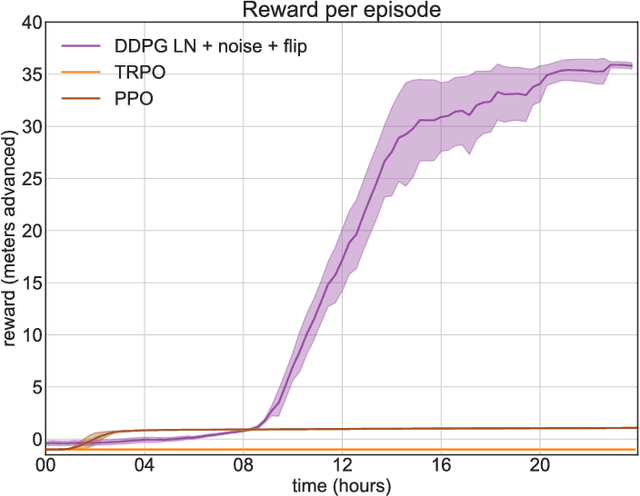
In the NIPS 2017 Learning to Run challenge, participants were tasked with building a controller for a musculoskeletal model to make it run as fast as possible through an obstacle course. Top participants were invited to describe their algorithms. In this work, we present eight solutions that used deep reinforcement learning approaches, based on algorithms such as Deep Deterministic Policy Gradient, Proximal Policy Optimization, and Trust Region Policy Optimization. Many solutions use similar relaxations and heuristics, such as reward shaping, frame skipping, discretization of the action space, symmetry, and policy blending. However, each of the eight teams implemented different modifications of the known algorithms.