 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArena: a toolkit for Multi-Agent Reinforcement Learning
Paper and Code
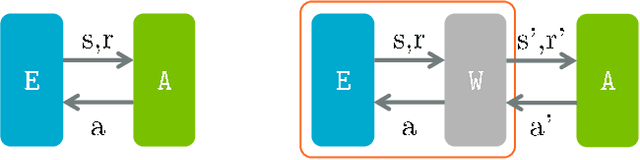
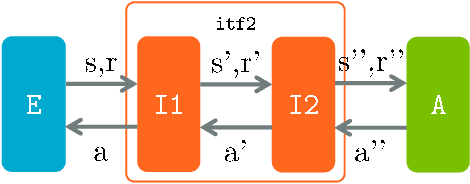
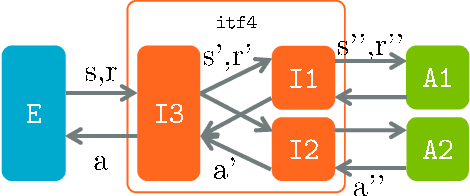

We introduce Arena, a toolkit for multi-agent reinforcement learning (MARL) research. In MARL, it usually requires customizing observations, rewards and actions for each agent, changing cooperative-competitive agent-interaction, and playing with/against a third-party agent, etc. We provide a novel modular design, called Interface, for manipulating such routines in essentially two ways: 1) Different interfaces can be concatenated and combined, which extends the OpenAI Gym Wrappers concept to MARL scenarios. 2) During MARL training or testing, interfaces can be embedded in either wrapped OpenAI Gym compatible Environments or raw environment compatible Agents. We offer off-the-shelf interfaces for several popular MARL platforms, including StarCraft II, Pommerman, ViZDoom, Soccer, etc. The interfaces effectively support self-play RL and cooperative-competitive hybrid MARL. Also, Arena can be conveniently extended to your own favorite MARL platform.