 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Transformers: SwiftKey's Differential Privacy Implementation
May 08, 2025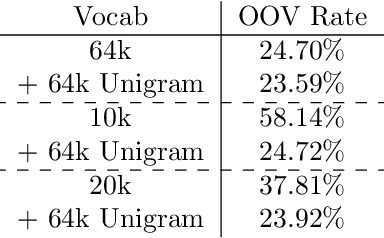
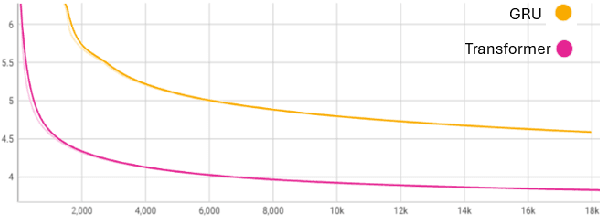
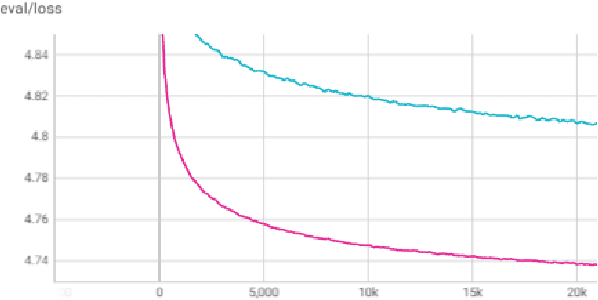
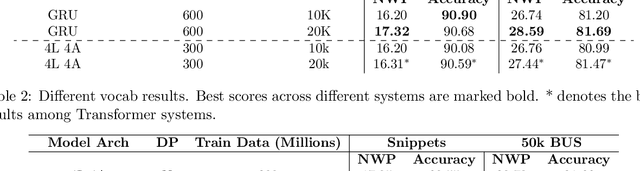
In this paper we train a transformer using differential privacy (DP) for language modeling in SwiftKey. We run multiple experiments to balance the trade-off between the model size, run-time speed and accuracy. We show that we get small and consistent gains in the next-word-prediction and accuracy with graceful increase in memory and speed compared to the production GRU. This is obtained by scaling down a GPT2 architecture to fit the required size and a two stage training process that builds a seed model on general data and DP finetunes it on typing data. The transformer is integrated using ONNX offering both flexibility and efficiency.
Mixture of Quantized Experts (MoQE): Complementary Effect of Low-bit Quantization and Robustness
Oct 03, 2023

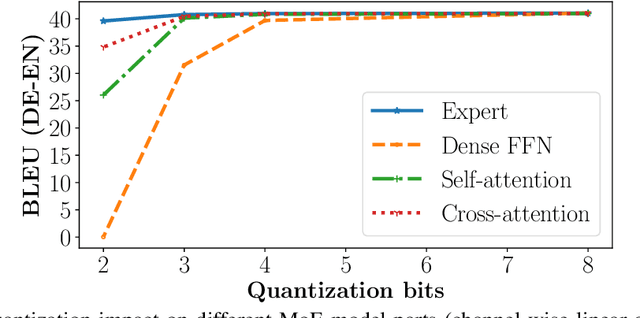

Large Mixture of Experts (MoE) models could achieve state-of-the-art quality on various language tasks, including machine translation task, thanks to the efficient model scaling capability with expert parallelism. However, it has brought a fundamental issue of larger memory consumption and increased memory bandwidth bottleneck at deployment time. In this paper, we propose Mixture of Quantized Experts (MoQE) which is a simple weight-only quantization method applying ultra low-bit down to 2-bit quantizations only to expert weights for mitigating the increased memory and latency issues of MoE models. We show that low-bit quantization together with the MoE architecture delivers a reliable model performance while reducing the memory size significantly even without any additional training in most cases. In particular, expert layers in MoE models are much more robust to the quantization than conventional feedforward networks (FFN) layers. In our comprehensive analysis, we show that MoE models with 2-bit expert weights can deliver better model performance than the dense model trained on the same dataset. As a result of low-bit quantization, we show the model size can be reduced by 79.6% of the original half precision floating point (fp16) MoE model. Combined with an optimized GPU runtime implementation, it also achieves 1.24X speed-up on A100 GPUs.
FineQuant: Unlocking Efficiency with Fine-Grained Weight-Only Quantization for LLMs
Aug 16, 2023Large Language Models (LLMs) have achieved state-of-the-art performance across various language tasks but pose challenges for practical deployment due to their substantial memory requirements. Furthermore, the latest generative models suffer from high inference costs caused by the memory bandwidth bottleneck in the auto-regressive decoding process. To address these issues, we propose an efficient weight-only quantization method that reduces memory consumption and accelerates inference for LLMs. To ensure minimal quality degradation, we introduce a simple and effective heuristic approach that utilizes only the model weights of a pre-trained model. This approach is applicable to both Mixture-of-Experts (MoE) and dense models without requiring additional fine-tuning. To demonstrate the effectiveness of our proposed method, we first analyze the challenges and issues associated with LLM quantization. Subsequently, we present our heuristic approach, which adaptively finds the granularity of quantization, effectively addressing these problems. Furthermore, we implement highly efficient GPU GEMMs that perform on-the-fly matrix multiplication and dequantization, supporting the multiplication of fp16 or bf16 activations with int8 or int4 weights. We evaluate our approach on large-scale open source models such as OPT-175B and internal MoE models, showcasing minimal accuracy loss while achieving up to 3.65 times higher throughput on the same number of GPUs.
Who Says Elephants Can't Run: Bringing Large Scale MoE Models into Cloud Scale Production
Nov 18, 2022



Mixture of Experts (MoE) models with conditional execution of sparsely activated layers have enabled training models with a much larger number of parameters. As a result, these models have achieved significantly better quality on various natural language processing tasks including machine translation. However, it remains challenging to deploy such models in real-life scenarios due to the large memory requirements and inefficient inference. In this work, we introduce a highly efficient inference framework with several optimization approaches to accelerate the computation of sparse models and cut down the memory consumption significantly. While we achieve up to 26x speed-up in terms of throughput, we also reduce the model size almost to one eighth of the original 32-bit float model by quantizing expert weights into 4-bit integers. As a result, we are able to deploy 136x larger models with 27% less cost and significantly better quality compared to the existing solutions. This enables a paradigm shift in deploying large scale multilingual MoE transformers models replacing the traditional practice of distilling teacher models into dozens of smaller models per language or task.