Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting MARBERT for Improved Arabic Dialect Identification: Submission to the NADI 2021 Shared Task
Paper and Code
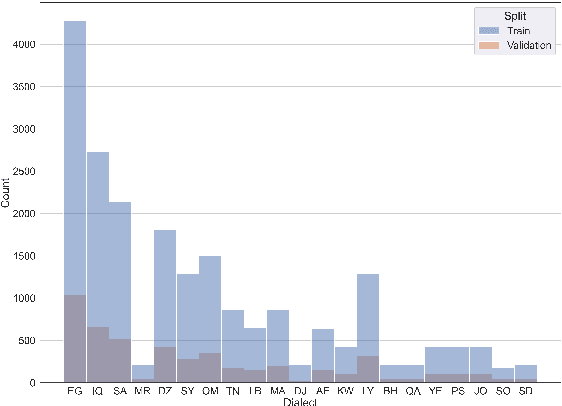

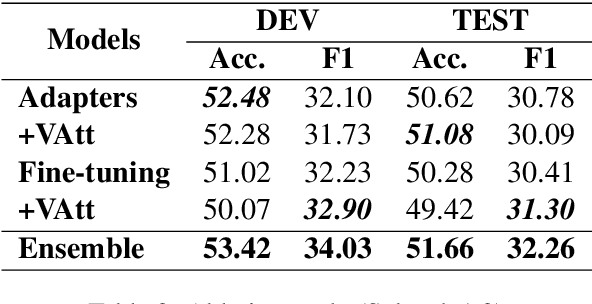
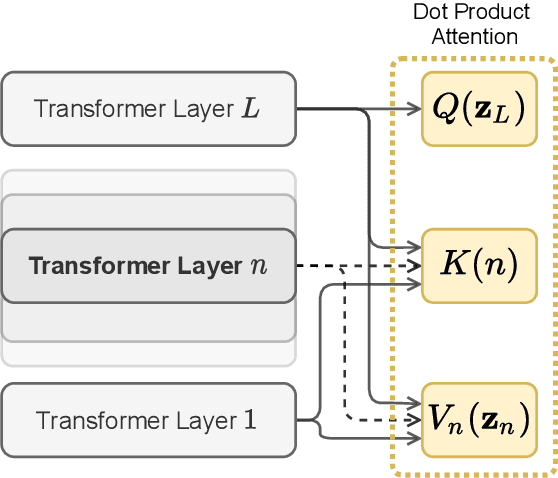
In this paper, we tackle the Nuanced Arabic Dialect Identification (NADI) shared task (Abdul-Mageed et al., 2021) and demonstrate state-of-the-art results on all of its four subtasks. Tasks are to identify the geographic origin of short Dialectal (DA) and Modern Standard Arabic (MSA) utterances at the levels of both country and province. Our final model is an ensemble of variants built on top of MARBERT that achieves an F1-score of 34.03% for DA at the country-level development set -- an improvement of 7.63% from previous work.
* This work was accepted at the Sixth Arabic Natural Language
Processing Workshop (EACL/WANLP 2021)
View paper on