 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSPT: Long-term Spatial Prompt Tuning for Visual Representation Learning
Paper and Code
Feb 27, 2024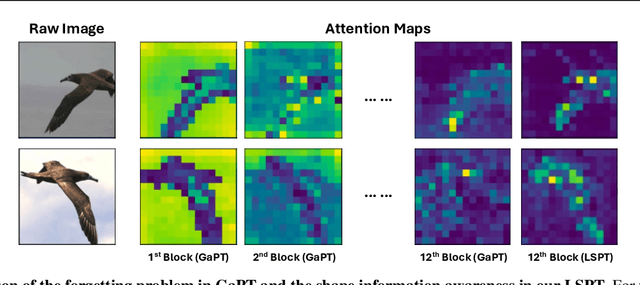
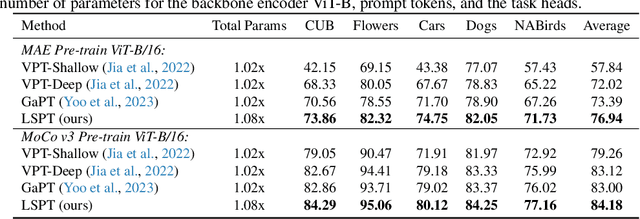
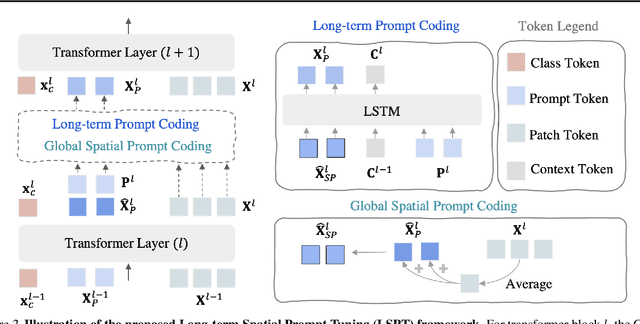
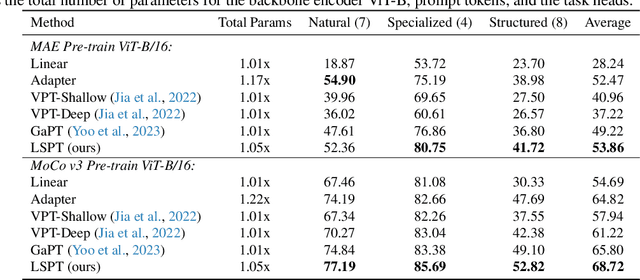
Visual Prompt Tuning (VPT) techniques have gained prominence for their capacity to adapt pre-trained Vision Transformers (ViTs) to downstream visual tasks using specialized learnable tokens termed as prompts. Contemporary VPT methodologies, especially when employed with self-supervised vision transformers, often default to the introduction of new learnable prompts or gated prompt tokens predominantly sourced from the model's previous block. A pivotal oversight in such approaches is their failure to harness the potential of long-range previous blocks as sources of prompts within each self-supervised ViT. To bridge this crucial gap, we introduce Long-term Spatial Prompt Tuning (LSPT) - a revolutionary approach to visual representation learning. Drawing inspiration from the intricacies of the human brain, LSPT ingeniously incorporates long-term gated prompts. This feature serves as temporal coding, curbing the risk of forgetting parameters acquired from earlier blocks. Further enhancing its prowess, LSPT brings into play patch tokens, serving as spatial coding. This is strategically designed to perpetually amass class-conscious features, thereby fortifying the model's prowess in distinguishing and identifying visual categories. To validate the efficacy of our proposed method, we engaged in rigorous experimentation across 5 FGVC and 19 VTAB-1K benchmarks. Our empirical findings underscore the superiority of LSPT, showcasing its ability to set new benchmarks in visual prompt tuning performance.