 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCore Challenges in Embodied Vision-Language Planning
Apr 05, 2023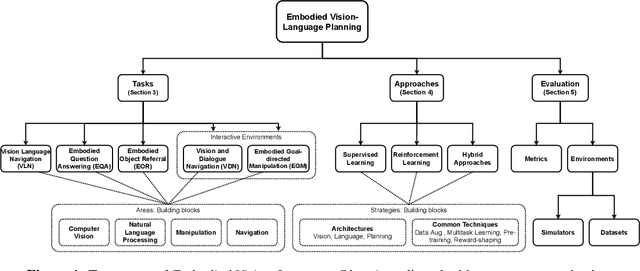
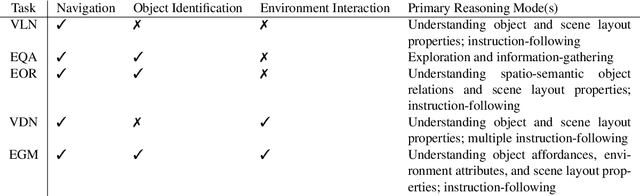
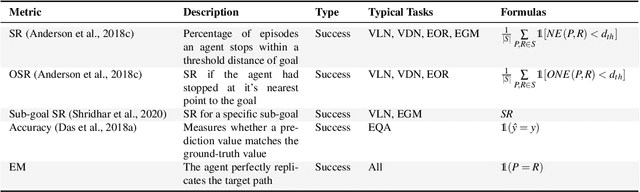

Recent advances in the areas of Multimodal Machine Learning and Artificial Intelligence (AI) have led to the development of challenging tasks at the intersection of Computer Vision, Natural Language Processing, and Robotics. Whereas many approaches and previous survey pursuits have characterised one or two of these dimensions, there has not been a holistic analysis at the center of all three. Moreover, even when combinations of these topics are considered, more focus is placed on describing, e.g., current architectural methods, as opposed to also illustrating high-level challenges and opportunities for the field. In this survey paper, we discuss Embodied Vision-Language Planning (EVLP) tasks, a family of prominent embodied navigation and manipulation problems that jointly leverage computer vision and natural language for interaction in physical environments. We propose a taxonomy to unify these tasks and provide an in-depth analysis and comparison of the current and new algorithmic approaches, metrics, simulators, and datasets used for EVLP tasks. Finally, we present the core challenges that we believe new EVLP works should seek to address, and we advocate for task construction that enables model generalisability and furthers real-world deployment.