 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIt Takes Two to Negotiate: Modeling Social Exchange in Online Multiplayer Games
Nov 15, 2023
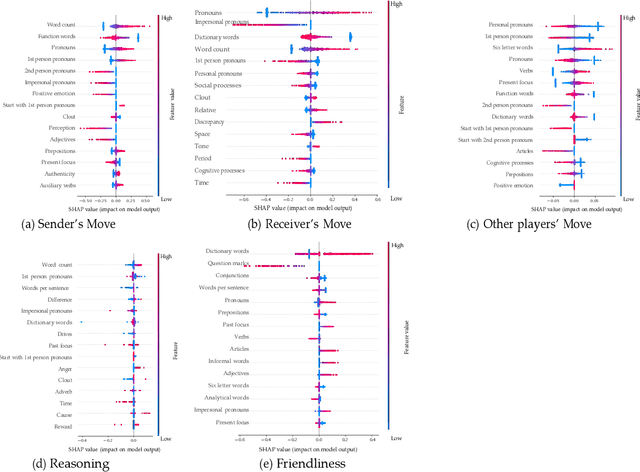


Online games are dynamic environments where players interact with each other, which offers a rich setting for understanding how players negotiate their way through the game to an ultimate victory. This work studies online player interactions during the turn-based strategy game, Diplomacy. We annotated a dataset of over 10,000 chat messages for different negotiation strategies and empirically examined their importance in predicting long- and short-term game outcomes. Although negotiation strategies can be predicted reasonably accurately through the linguistic modeling of the chat messages, more is needed for predicting short-term outcomes such as trustworthiness. On the other hand, they are essential in graph-aware reinforcement learning approaches to predict long-term outcomes, such as a player's success, based on their prior negotiation history. We close with a discussion of the implications and impact of our work. The dataset is available at https://github.com/kj2013/claff-diplomacy.
CIGLI: Conditional Image Generation from Language & Image
Aug 20, 2021
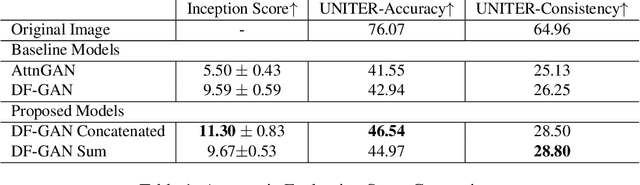


Multi-modal generation has been widely explored in recent years. Current research directions involve generating text based on an image or vice versa. In this paper, we propose a new task called CIGLI: Conditional Image Generation from Language and Image. Instead of generating an image based on text as in text-image generation, this task requires the generation of an image from a textual description and an image prompt. We designed a new dataset to ensure that the text description describes information from both images, and that solely analyzing the description is insufficient to generate an image. We then propose a novel language-image fusion model which improves the performance over two established baseline methods, as evaluated by quantitative (automatic) and qualitative (human) evaluations. The code and dataset is available at https://github.com/vincentlux/CIGLI.
Audio Adversarial Examples: Attacks Using Vocal Masks
Feb 06, 2021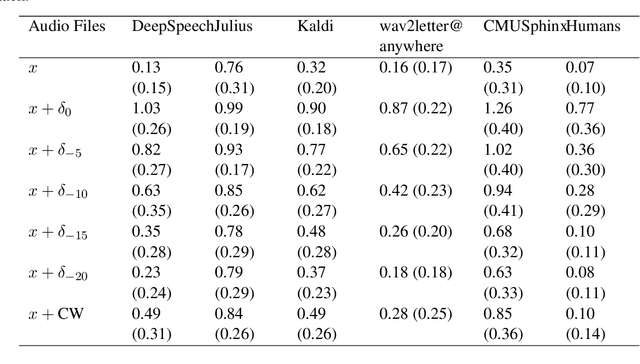
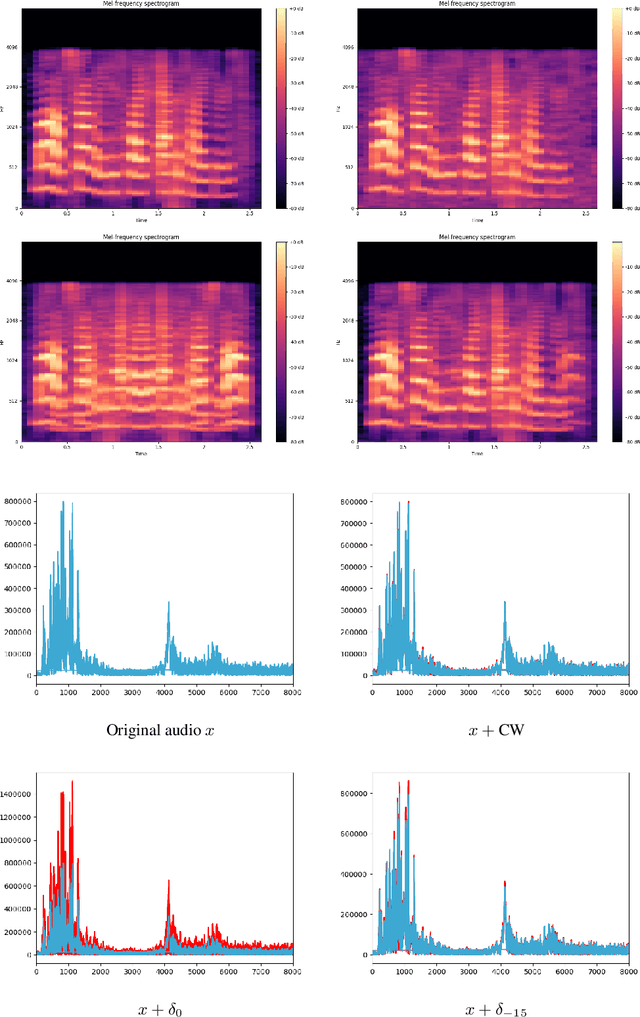
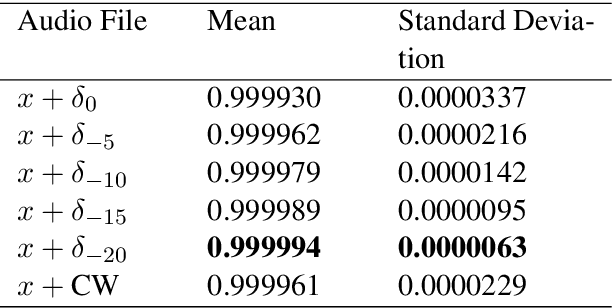
We construct audio adversarial examples on automatic Speech-To-Text systems . Given any audio waveform, we produce an another by overlaying an audio vocal mask generated from the original audio. We apply our audio adversarial attack to five SOTA STT systems: DeepSpeech, Julius, Kaldi, wav2letter@anywhere and CMUSphinx. In addition, we engaged human annotators to transcribe the adversarial audio. Our experiments show that these adversarial examples fool State-Of-The-Art Speech-To-Text systems, yet humans are able to consistently pick out the speech. The feasibility of this attack introduces a new domain to study machine and human perception of speech.