Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Adversarial Examples: Attacks Using Vocal Masks
Feb 06, 2021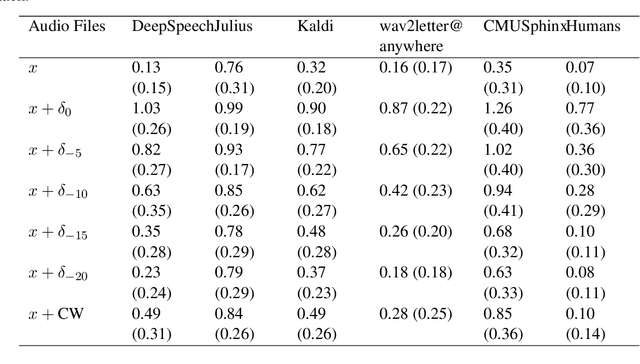
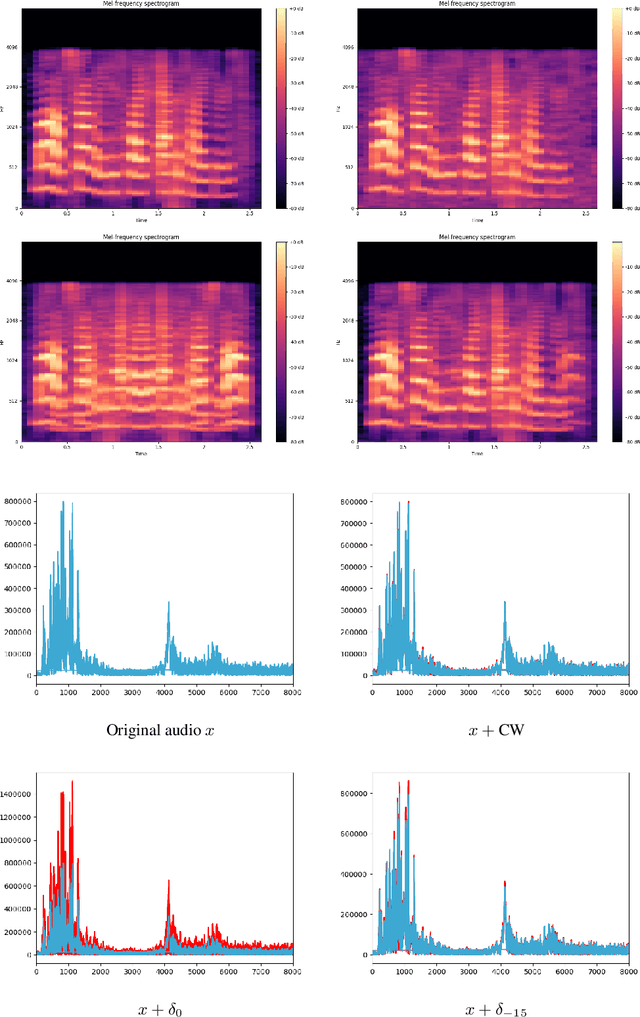
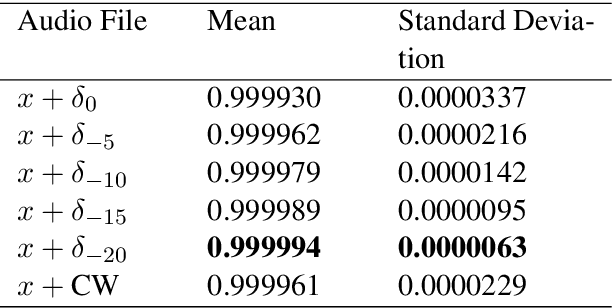
We construct audio adversarial examples on automatic Speech-To-Text systems . Given any audio waveform, we produce an another by overlaying an audio vocal mask generated from the original audio. We apply our audio adversarial attack to five SOTA STT systems: DeepSpeech, Julius, Kaldi, wav2letter@anywhere and CMUSphinx. In addition, we engaged human annotators to transcribe the adversarial audio. Our experiments show that these adversarial examples fool State-Of-The-Art Speech-To-Text systems, yet humans are able to consistently pick out the speech. The feasibility of this attack introduces a new domain to study machine and human perception of speech.
* 9 pages, 1 figure, 2 tables. Submitted to COLING2020
Via