 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIGLI: Conditional Image Generation from Language & Image
Paper and Code

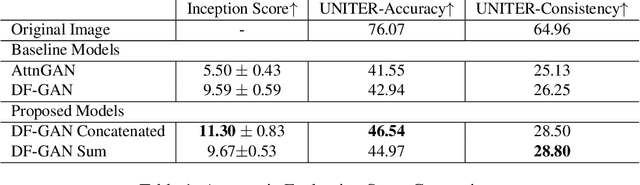


Multi-modal generation has been widely explored in recent years. Current research directions involve generating text based on an image or vice versa. In this paper, we propose a new task called CIGLI: Conditional Image Generation from Language and Image. Instead of generating an image based on text as in text-image generation, this task requires the generation of an image from a textual description and an image prompt. We designed a new dataset to ensure that the text description describes information from both images, and that solely analyzing the description is insufficient to generate an image. We then propose a novel language-image fusion model which improves the performance over two established baseline methods, as evaluated by quantitative (automatic) and qualitative (human) evaluations. The code and dataset is available at https://github.com/vincentlux/CIGLI.