 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVL-CheckList: Evaluating Pre-trained Vision-Language Models with Objects, Attributes and Relations
Paper and Code
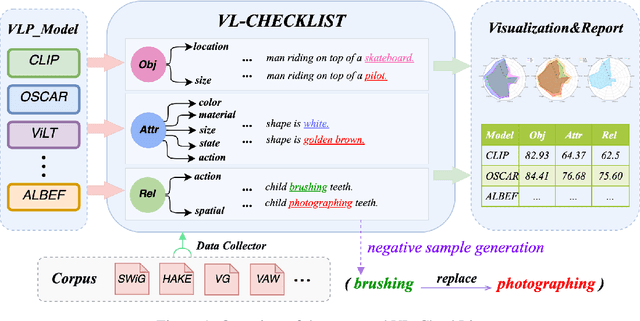
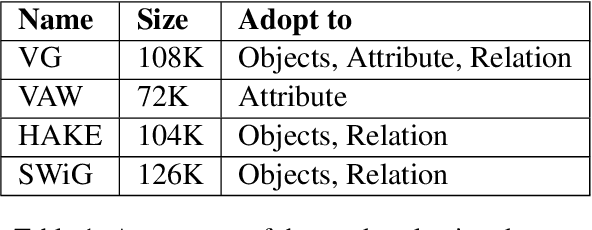
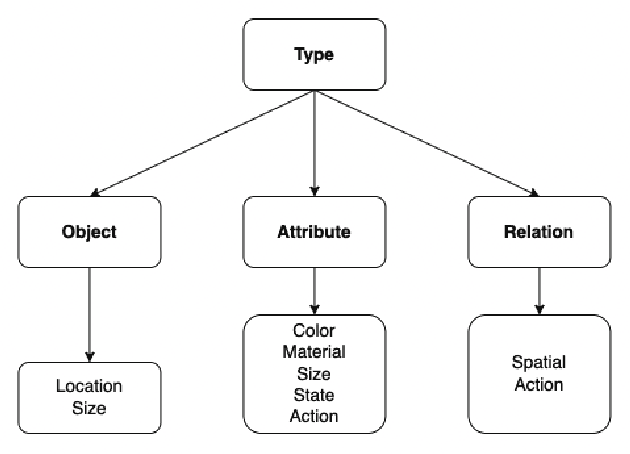
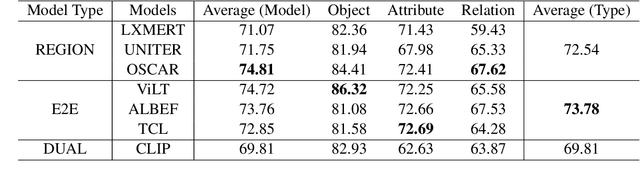
Vision-Language Pretraining (VLP) models have recently successfully facilitated many cross-modal downstream tasks. Most existing works evaluated their systems by comparing the fine-tuned downstream task performance. However, only average downstream task accuracy provides little information about the pros and cons of each VLP method, let alone provides insights on how the community can improve the systems in the future. Inspired by the CheckList for testing natural language processing, we introduce VL-CheckList, a novel framework to understand the capabilities of VLP models. The proposed method divides the image-texting ability of a VLP model into three categories: objects, attributes, and relations, and uses a novel taxonomy to further break down these three aspects. We conduct comprehensive studies to analyze seven recently popular VLP models via the proposed framework. Results confirm the effectiveness of the proposed method by revealing fine-grained differences among the compared models that were not visible from downstream task-only evaluation. Further results show promising research direction in building better VLP models. Data and Code: https://github.com/om-ai-lab/VL-CheckList