 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
GUI Testing Arena: A Unified Benchmark for Advancing Autonomous GUI Testing Agent
Dec 24, 2024



Nowadays, research on GUI agents is a hot topic in the AI community. However, current research focuses on GUI task automation, limiting the scope of applications in various GUI scenarios. In this paper, we propose a formalized and comprehensive environment to evaluate the entire process of automated GUI Testing (GTArena), offering a fair, standardized environment for consistent operation of diverse multimodal large language models. We divide the testing process into three key subtasks: test intention generation, test task execution, and GUI defect detection, and construct a benchmark dataset based on these to conduct a comprehensive evaluation. It evaluates the performance of different models using three data types: real mobile applications, mobile applications with artificially injected defects, and synthetic data, thoroughly assessing their capabilities in this relevant task. Additionally, we propose a method that helps researchers explore the correlation between the performance of multimodal language large models in specific scenarios and their general capabilities in standard benchmark tests. Experimental results indicate that even the most advanced models struggle to perform well across all sub-tasks of automated GUI Testing, highlighting a significant gap between the current capabilities of Autonomous GUI Testing and its practical, real-world applicability. This gap provides guidance for the future direction of GUI Agent development. Our code is available at https://github.com/ZJU-ACES-ISE/ChatUITest.
Preserving Knowledge in Large Language Model: A Model-Agnostic Self-Decompression Approach
Jun 17, 2024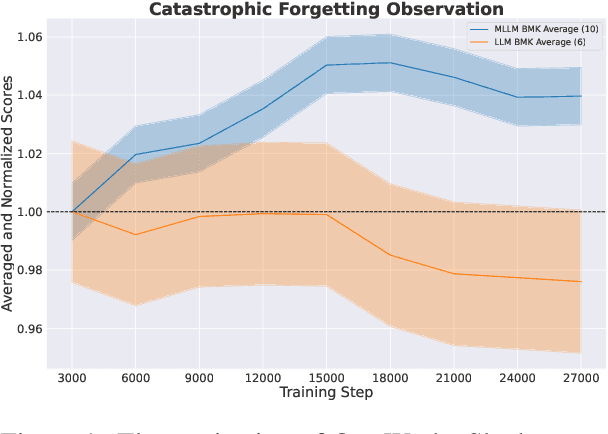
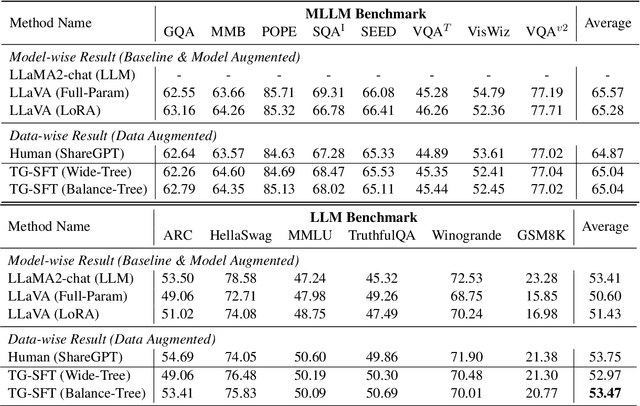
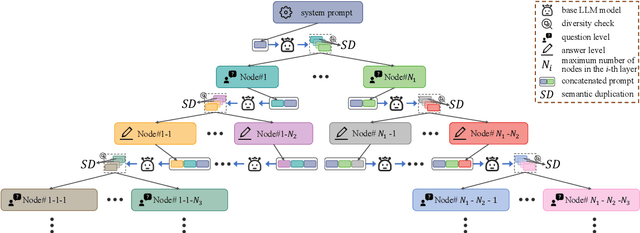

Humans can retain old knowledge while learning new information, but Large Language Models (LLMs) often suffer from catastrophic forgetting when post-pretrained or supervised fine-tuned (SFT) on domain-specific data. Moreover, for Multimodal Large Language Models (MLLMs) which are composed of the LLM base and visual projector (e.g. LLaVA), a significant decline in performance on language benchmarks was observed compared to their single-modality counterparts. To address these challenges, we introduce a novel model-agnostic self-decompression method, Tree Generation (TG), that decompresses knowledge within LLMs into the training corpus. This paper focuses on TG-SFT, which can synthetically generate SFT data for the instruction tuning steps. By incorporating the dumped corpus during SFT for MLLMs, we significantly reduce the forgetting problem.
Benchmarking Sequential Visual Input Reasoning and Prediction in Multimodal Large Language Models
Oct 20, 2023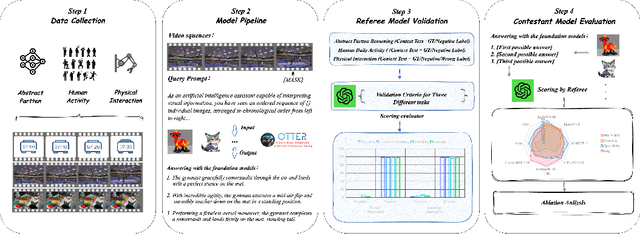
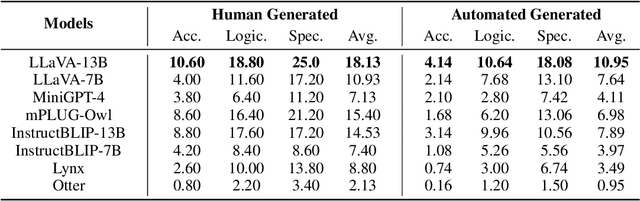

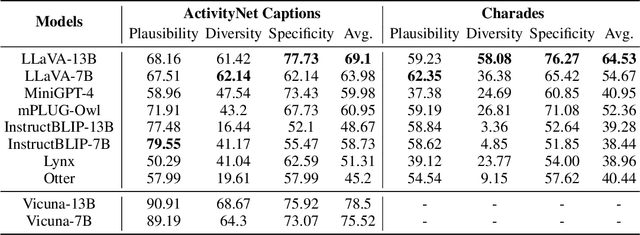
Multimodal large language models (MLLMs) have shown great potential in perception and interpretation tasks, but their capabilities in predictive reasoning remain under-explored. To address this gap, we introduce a novel benchmark that assesses the predictive reasoning capabilities of MLLMs across diverse scenarios. Our benchmark targets three important domains: abstract pattern reasoning, human activity prediction, and physical interaction prediction. We further develop three evaluation methods powered by large language model to robustly quantify a model's performance in predicting and reasoning the future based on multi-visual context. Empirical experiments confirm the soundness of the proposed benchmark and evaluation methods via rigorous testing and reveal pros and cons of current popular MLLMs in the task of predictive reasoning. Lastly, our proposed benchmark provides a standardized evaluation framework for MLLMs and can facilitate the development of more advanced models that can reason and predict over complex long sequence of multimodal input.