 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreserving Knowledge in Large Language Model: A Model-Agnostic Self-Decompression Approach
Paper and Code
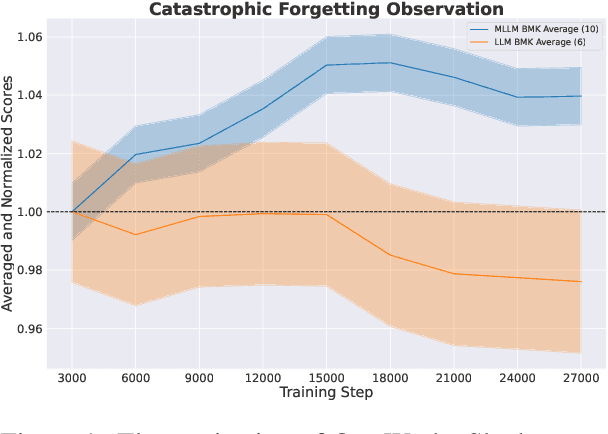
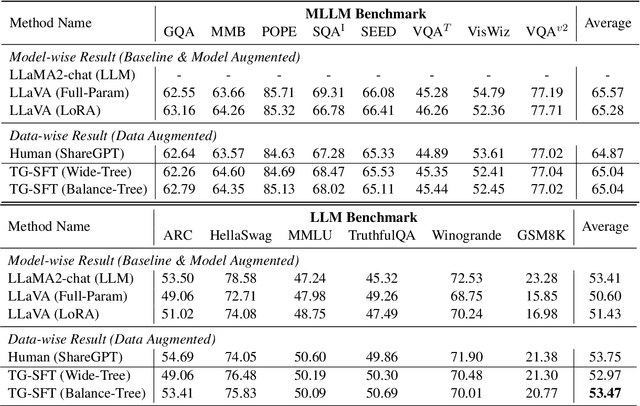
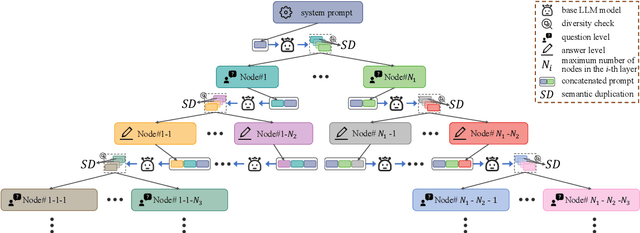

Humans can retain old knowledge while learning new information, but Large Language Models (LLMs) often suffer from catastrophic forgetting when post-pretrained or supervised fine-tuned (SFT) on domain-specific data. Moreover, for Multimodal Large Language Models (MLLMs) which are composed of the LLM base and visual projector (e.g. LLaVA), a significant decline in performance on language benchmarks was observed compared to their single-modality counterparts. To address these challenges, we introduce a novel model-agnostic self-decompression method, Tree Generation (TG), that decompresses knowledge within LLMs into the training corpus. This paper focuses on TG-SFT, which can synthetically generate SFT data for the instruction tuning steps. By incorporating the dumped corpus during SFT for MLLMs, we significantly reduce the forgetting problem.