 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycle-resolved Cephalopod-Inspired Pulsed-Jet Robot With High-Volume Expulsion and Drag-Reduced Gliding
May 07, 2026Cephalopod pulsed-jet locomotion is not a single isolated expulsion event, but a coordinated cycle involving jet expulsion, passive gliding, and mantle refilling. Inspired by this cycle-resolved biological strategy, this paper presents a cephalopod-inspired pulsed-jet robot with a rigid-soft hybrid origami mantle that enables large, actively driven, and geometry-guided body deformation. The proposed mantle integrates rigid folding panels with a compliant silicone framework, allowing a 75% effective cavity-volume reduction during expulsion and reducing the projected cross-sectional drag area by approximately 75.7% in the contracted gliding configuration. Using this platform, we formulate a cycle-resolved framework to separately investigate how expelled volume, glide duration, and refill pathway influence whole-cycle locomotion performance. Experiments show that the robot reaches a peak speed of approximately 0.5 m/s (3.8 BL/s) and an average speed exceeding 0.2 m/s (1.5 BL/s) within the first jetting cycle. The results further demonstrate the roles of high expelled-volume-ratio contraction in speed generation, reduced-drag-area gliding under different glide durations, and mantle-aperture-inspired passive inlet valves in assisting refill. This work provides both a robotic implementation of actively deformable cephalopod-like jet propulsion and a unified experimental platform for studying expulsion-gliding-refilling dynamics in pulsed-jet locomotion.
Unified Structural-Hydrodynamic Modeling of Underwater Underactuated Mechanisms and Soft Robots
Mar 09, 2026Underwater robots are widely deployed for ocean exploration and manipulation. Underactuated mechanisms are particularly advantageous in aquatic environments, as reducing actuator count lowers the risk of motor leakage while introducing inherent mechanical compliance. However, accurate modeling of underwater underactuated and soft robotic systems remains challenging because it requires identifying a high-dimensional set of internal structural and external hydrodynamic parameters. In this work, we propose a trajectory-driven global optimization framework for unified structural-hydrodynamic modeling of underwater multibody systems. Inspired by the Covariance Matrix Adaptation Evolution Strategy (CMA-ES), the proposed approach simultaneously identifies coupled internal elastic, damping, and distributed hydrodynamic parameters through trajectory-level matching between simulation and experimental motion. This enables high-fidelity reproduction of both underactuated mechanisms and compliant soft robotic systems in underwater environments. We first validate the framework on a link-by-link underactuated multibody mechanism, demonstrating accurate identification of distributed hydrodynamic coefficients, with a normalized end effector position error below 5% across multiple trajectories, varying initial conditions, and both active-passive and fully passive configurations. The identified modeling strategy is then transferred to a single octopus-inspired soft arm, showing strong real-to-sim consistency without manual retuning. Finally, eight identified arms are assembled into a swimming octopus robot, where the unified parameter set enables realistic whole body behavior without additional parameter calibration. These results demonstrate the scalability and transferability of the proposed structural-hydrodynamic modeling framework across underwater underactuated and soft robotic systems.
Physical Human-Robot Interaction for Grasping in Augmented Reality via Rigid-Soft Robot Synergy
Feb 19, 2026Hybrid rigid-soft robots combine the precision of rigid manipulators with the compliance and adaptability of soft arms, offering a promising approach for versatile grasping in unstructured environments. However, coordinating hybrid robots remains challenging, due to difficulties in modeling, perception, and cross-domain kinematics. In this work, we present a novel augmented reality (AR)-based physical human-robot interaction framework that enables direct teleoperation of a hybrid rigid-soft robot for simple reaching and grasping tasks. Using an AR headset, users can interact with a simulated model of the robotic system integrated into a general-purpose physics engine, which is superimposed on the real system, allowing simulated execution prior to real-world deployment. To ensure consistent behavior between the virtual and physical robots, we introduce a real-to-simulation parameter identification pipeline that leverages the inherent geometric properties of the soft robot, enabling accurate modeling of its static and dynamic behavior as well as the control system's response.
From Shallow Waters to Mariana Trench: A Survey of Bio-inspired Underwater Soft Robots
Jan 18, 2026Sample Exploring the ocean environment holds profound significance in areas such as resource exploration and ecological protection. Underwater robots struggle with extreme water pressure and often cause noise and damage to the underwater ecosystem, while bio-inspired soft robots draw inspiration from aquatic creatures to address these challenges. These bio-inspired approaches enable robots to withstand high water pressure, minimize drag, operate with efficient manipulation and sensing systems, and interact with the environment in an eco-friendly manner. Consequently, bio-inspired soft robots have emerged as a promising field for ocean exploration. This paper reviews recent advancements in underwater bio-inspired soft robots, analyses their design considerations when facing different desired functions, bio-inspirations, ambient pressure, temperature, light, and biodiversity , and finally explores the progression from bio-inspired principles to practical applications in the field and suggests potential directions for developing the next generation of underwater soft robots.
Soft Responsive Materials Enhance Humanoid Safety
Jan 06, 2026Humanoid robots are envisioned as general-purpose platforms in human-centered environments, yet their deployment is limited by vulnerability to falls and the risks posed by rigid metal-plastic structures to people and surroundings. We introduce a soft-rigid co-design framework that leverages non-Newtonian fluid-based soft responsive materials to enhance humanoid safety. The material remains compliant during normal interaction but rapidly stiffens under impact, absorbing and dissipating fall-induced forces. Physics-based simulations guide protector placement and thickness and enable learning of active fall policies. Applied to a 42 kg life-size humanoid, the protector markedly reduces peak impact and allows repeated falls without hardware damage, including drops from 3 m and tumbles down long staircases. Across diverse scenarios, the approach improves robot robustness and environmental safety. By uniting responsive materials, structural co-design, and learning-based control, this work advances interact-safe, industry-ready humanoid robots.
Transition Models: Rethinking the Generative Learning Objective
Sep 04, 2025

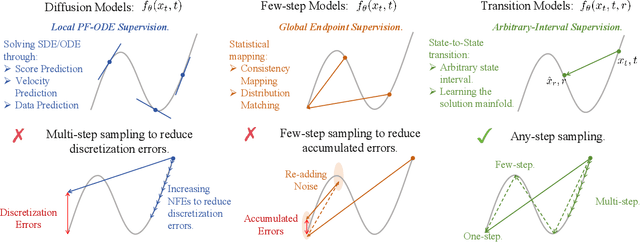

A fundamental dilemma in generative modeling persists: iterative diffusion models achieve outstanding fidelity, but at a significant computational cost, while efficient few-step alternatives are constrained by a hard quality ceiling. This conflict between generation steps and output quality arises from restrictive training objectives that focus exclusively on either infinitesimal dynamics (PF-ODEs) or direct endpoint prediction. We address this challenge by introducing an exact, continuous-time dynamics equation that analytically defines state transitions across any finite time interval. This leads to a novel generative paradigm, Transition Models (TiM), which adapt to arbitrary-step transitions, seamlessly traversing the generative trajectory from single leaps to fine-grained refinement with more steps. Despite having only 865M parameters, TiM achieves state-of-the-art performance, surpassing leading models such as SD3.5 (8B parameters) and FLUX.1 (12B parameters) across all evaluated step counts. Importantly, unlike previous few-step generators, TiM demonstrates monotonic quality improvement as the sampling budget increases. Additionally, when employing our native-resolution strategy, TiM delivers exceptional fidelity at resolutions up to 4096x4096.
MUG: Pseudo Labeling Augmented Audio-Visual Mamba Network for Audio-Visual Video Parsing
Jul 02, 2025The weakly-supervised audio-visual video parsing (AVVP) aims to predict all modality-specific events and locate their temporal boundaries. Despite significant progress, due to the limitations of the weakly-supervised and the deficiencies of the model architecture, existing methods are lacking in simultaneously improving both the segment-level prediction and the event-level prediction. In this work, we propose a audio-visual Mamba network with pseudo labeling aUGmentation (MUG) for emphasising the uniqueness of each segment and excluding the noise interference from the alternate modalities. Specifically, we annotate some of the pseudo-labels based on previous work. Using unimodal pseudo-labels, we perform cross-modal random combinations to generate new data, which can enhance the model's ability to parse various segment-level event combinations. For feature processing and interaction, we employ a audio-visual mamba network. The AV-Mamba enhances the ability to perceive different segments and excludes additional modal noise while sharing similar modal information. Our extensive experiments demonstrate that MUG improves state-of-the-art results on LLP dataset in all metrics (e.g,, gains of 2.1% and 1.2% in terms of visual Segment-level and audio Segment-level metrics). Our code is available at https://github.com/WangLY136/MUG.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
Multimodal Long Video Modeling Based on Temporal Dynamic Context
Apr 14, 2025Recent advances in Large Language Models (LLMs) have led to significant breakthroughs in video understanding. However, existing models still struggle with long video processing due to the context length constraint of LLMs and the vast amount of information within the video. Although some recent methods are designed for long video understanding, they often lose crucial information during token compression and struggle with additional modality like audio. In this work, we propose a dynamic long video encoding method utilizing the temporal relationship between frames, named Temporal Dynamic Context (TDC). Firstly, we segment the video into semantically consistent scenes based on inter-frame similarities, then encode each frame into tokens using visual-audio encoders. Secondly, we propose a novel temporal context compressor to reduce the number of tokens within each segment. Specifically, we employ a query-based Transformer to aggregate video, audio, and instruction text tokens into a limited set of temporal context tokens. Finally, we feed the static frame tokens and the temporal context tokens into the LLM for video understanding. Furthermore, to handle extremely long videos, we propose a training-free chain-of-thought strategy that progressively extracts answers from multiple video segments. These intermediate answers serve as part of the reasoning process and contribute to the final answer. We conduct extensive experiments on general video understanding and audio-video understanding benchmarks, where our method demonstrates strong performance. The code and models are available at https://github.com/Hoar012/TDC-Video.
Grasping by Spiraling: Reproducing Elephant Movements with Rigid-Soft Robot Synergy
Apr 02, 2025The logarithmic spiral is observed as a common pattern in several living beings across kingdoms and species. Some examples include fern shoots, prehensile tails, and soft limbs like octopus arms and elephant trunks. In the latter cases, spiraling is also used for grasping. Motivated by how this strategy simplifies behavior into kinematic primitives and combines them to develop smart grasping movements, this work focuses on the elephant trunk, which is more deeply investigated in the literature. We present a soft arm combined with a rigid robotic system to replicate elephant grasping capabilities based on the combination of a soft trunk with a solid body. In our system, the rigid arm ensures positioning and orientation, mimicking the role of the elephant's head, while the soft manipulator reproduces trunk motion primitives of bending and twisting under proper actuation patterns. This synergy replicates 9 distinct elephant grasping strategies reported in the literature, accommodating objects of varying shapes and sizes. The synergistic interaction between the rigid and soft components of the system minimizes the control complexity while maintaining a high degree of adaptability.