 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Long Video Modeling Based on Temporal Dynamic Context
Apr 14, 2025Recent advances in Large Language Models (LLMs) have led to significant breakthroughs in video understanding. However, existing models still struggle with long video processing due to the context length constraint of LLMs and the vast amount of information within the video. Although some recent methods are designed for long video understanding, they often lose crucial information during token compression and struggle with additional modality like audio. In this work, we propose a dynamic long video encoding method utilizing the temporal relationship between frames, named Temporal Dynamic Context (TDC). Firstly, we segment the video into semantically consistent scenes based on inter-frame similarities, then encode each frame into tokens using visual-audio encoders. Secondly, we propose a novel temporal context compressor to reduce the number of tokens within each segment. Specifically, we employ a query-based Transformer to aggregate video, audio, and instruction text tokens into a limited set of temporal context tokens. Finally, we feed the static frame tokens and the temporal context tokens into the LLM for video understanding. Furthermore, to handle extremely long videos, we propose a training-free chain-of-thought strategy that progressively extracts answers from multiple video segments. These intermediate answers serve as part of the reasoning process and contribute to the final answer. We conduct extensive experiments on general video understanding and audio-video understanding benchmarks, where our method demonstrates strong performance. The code and models are available at https://github.com/Hoar012/TDC-Video.
Remember, Retrieve and Generate: Understanding Infinite Visual Concepts as Your Personalized Assistant
Oct 17, 2024
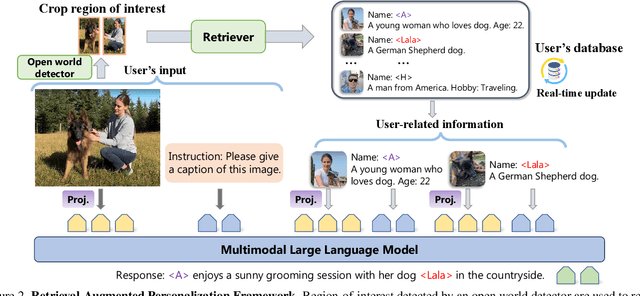


The development of large language models (LLMs) has significantly enhanced the capabilities of multimodal LLMs (MLLMs) as general assistants. However, lack of user-specific knowledge still restricts their application in human's daily life. In this paper, we introduce the Retrieval Augmented Personalization (RAP) framework for MLLMs' personalization. Starting from a general MLLM, we turn it into a personalized assistant in three steps. (a) Remember: We design a key-value database to store user-related information, e.g., user's name, avatar and other attributes. (b) Retrieve: When the user initiates a conversation, RAP will retrieve relevant information from the database using a multimodal retriever. (c) Generate: The input query and retrieved concepts' information are fed into MLLMs to generate personalized, knowledge-augmented responses. Unlike previous methods, RAP allows real-time concept editing via updating the external database. To further improve generation quality and alignment with user-specific information, we design a pipeline for data collection and create a specialized dataset for personalized training of MLLMs. Based on the dataset, we train a series of MLLMs as personalized multimodal assistants. By pretraining on large-scale dataset, RAP-MLLMs can generalize to infinite visual concepts without additional finetuning. Our models demonstrate outstanding flexibility and generation quality across a variety of tasks, such as personalized image captioning, question answering and visual recognition. The code, data and models are available at https://github.com/Hoar012/RAP-MLLM.