 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Sampling and Optimisation for Inverse Rendering
Sep 27, 2023
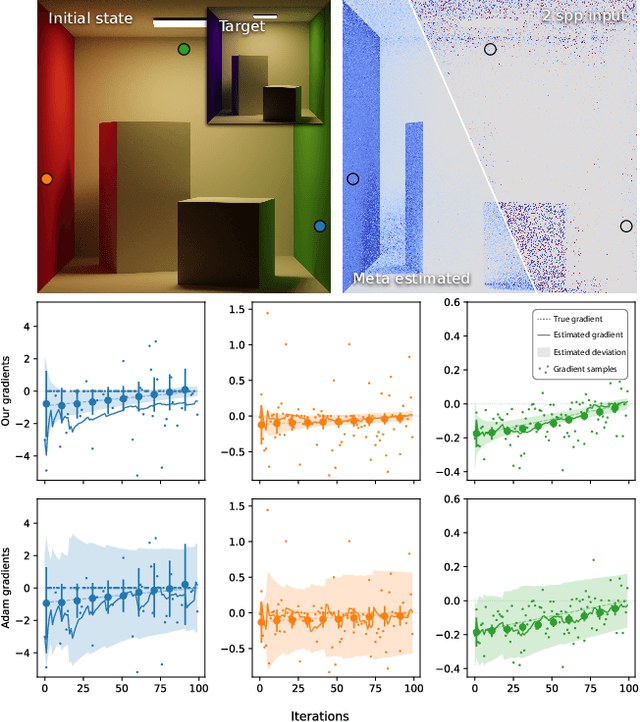
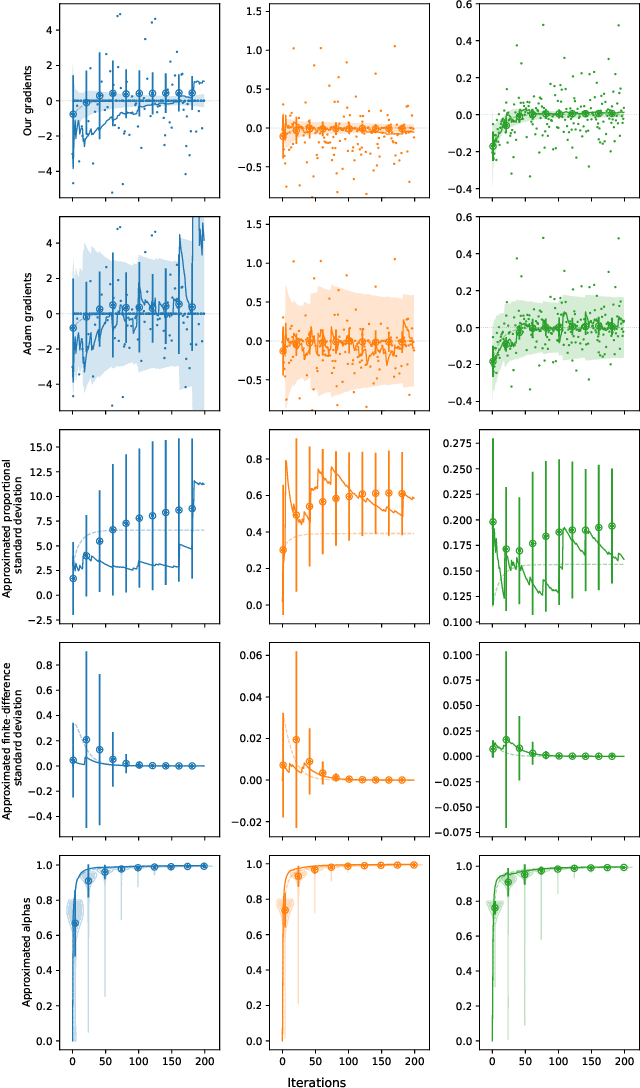

When dealing with difficult inverse problems such as inverse rendering, using Monte Carlo estimated gradients to optimise parameters can slow down convergence due to variance. Averaging many gradient samples in each iteration reduces this variance trivially. However, for problems that require thousands of optimisation iterations, the computational cost of this approach rises quickly. We derive a theoretical framework for interleaving sampling and optimisation. We update and reuse past samples with low-variance finite-difference estimators that describe the change in the estimated gradients between each iteration. By combining proportional and finite-difference samples, we continuously reduce the variance of our novel gradient meta-estimators throughout the optimisation process. We investigate how our estimator interlinks with Adam and derive a stable combination. We implement our method for inverse path tracing and demonstrate how our estimator speeds up convergence on difficult optimisation tasks.