 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuzzyLogic.jl: a Flexible Library for Efficient and Productive Fuzzy Inference
Jun 17, 2023

This paper introduces \textsc{FuzzyLogic.jl}, a Julia library to perform fuzzy inference. The library is fully open-source and released under a permissive license. The core design principles of the library are: user-friendliness, flexibility, efficiency and interoperability. Particularly, our library is easy to use, allows to specify fuzzy systems in an expressive yet concise domain specific language, has several visualization tools, supports popular inference systems like Mamdani, Sugeno and Type-2 systems, can be easily expanded with custom user settings or algorithms and can perform fuzzy inference efficiently. It also allows reading fuzzy models from other formats such as Matlab .fis, FCL or FML. In this paper, we describe the library main features and benchmark it with a few examples, showing it achieves significant speedup compared to the Matlab fuzzy toolbox.
TBPos: Dataset for Large-Scale Precision Visual Localization
Feb 20, 2023



Image based localization is a classical computer vision challenge, with several well-known datasets. Generally, datasets consist of a visual 3D database that captures the modeled scenery, as well as query images whose 3D pose is to be discovered. Usually the query images have been acquired with a camera that differs from the imaging hardware used to collect the 3D database; consequently, it is hard to acquire accurate ground truth poses between query images and the 3D database. As the accuracy of visual localization algorithms constantly improves, precise ground truth becomes increasingly important. This paper proposes TBPos, a novel large-scale visual dataset for image based positioning, which provides query images with fully accurate ground truth poses: both the database images and the query images have been derived from the same laser scanner data. In the experimental part of the paper, the proposed dataset is evaluated by means of an image-based localization pipeline.
SADT: Combining Sharpness-Aware Minimization with Self-Distillation for Improved Model Generalization
Nov 01, 2022Methods for improving deep neural network training times and model generalizability consist of various data augmentation, regularization, and optimization approaches, which tend to be sensitive to hyperparameter settings and make reproducibility more challenging. This work jointly considers two recent training strategies that address model generalizability: sharpness-aware minimization, and self-distillation, and proposes the novel training strategy of Sharpness-Aware Distilled Teachers (SADT). The experimental section of this work shows that SADT consistently outperforms previously published training strategies in model convergence time, test-time performance, and model generalizability over various neural architectures, datasets, and hyperparameter settings.
Fault-Tolerant Collaborative Inference through the Edge-PRUNE Framework
Jun 16, 2022


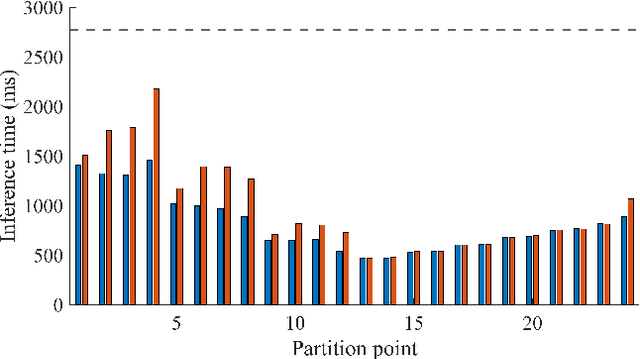
Collaborative inference has received significant research interest in machine learning as a vehicle for distributing computation load, reducing latency, as well as addressing privacy preservation in communications. Recent collaborative inference frameworks have adopted dynamic inference methodologies such as early-exit and run-time partitioning of neural networks. However, as machine learning frameworks scale in the number of inference inputs, e.g., in surveillance applications, fault tolerance related to device failure needs to be considered. This paper presents the Edge-PRUNE distributed computing framework, built on a formally defined model of computation, which provides a flexible infrastructure for fault tolerant collaborative inference. The experimental section of this work shows results on achievable inference time savings by collaborative inference, presents fault tolerant system topologies and analyzes their cost in terms of execution time overhead.
Multiple Offsets Multilateration: a new paradigm for sensor network calibration with unsynchronized reference nodes
May 23, 2022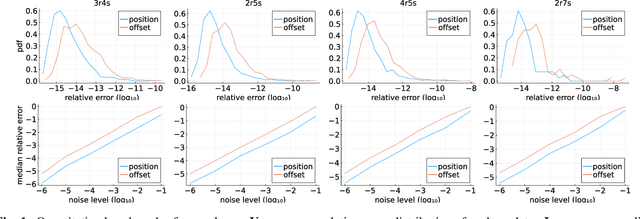
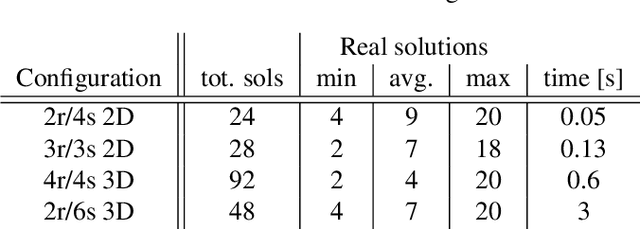
Positioning using wave signal measurements is used in several applications, such as GPS systems, structure from sound and Wifi based positioning. Mathematically, such problems require the computation of the positions of receivers and/or transmitters as well as time offsets if the devices are unsynchronized. In this paper, we expand the previous state-of-the-art on positioning formulations by introducing Multiple Offsets Multilateration (MOM), a new mathematical framework to compute the receivers positions with pseudoranges from unsynchronized reference transmitters at known positions. This could be applied in several scenarios, for example structure from sound and positioning with LEO satellites. We mathematically describe MOM, determining how many receivers and transmitters are needed for the network to be solvable, a study on the number of possible distinct solutions is presented and stable solvers based on homotopy continuation are derived. The solvers are shown to be efficient and robust to noise both for synthetic and real audio data.
Convolutional Neural Network-based Efficient Dense Point Cloud Generation using Unsigned Distance Fields
Mar 22, 2022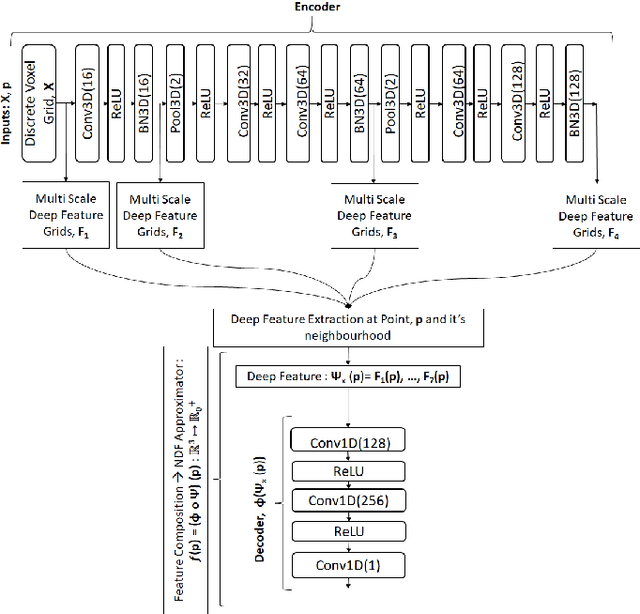



Dense point cloud generation from a sparse or incomplete point cloud is a crucial and challenging problem in 3D computer vision and computer graphics. So far, the existing methods are either computationally too expensive, suffer from limited resolution, or both. In addition, some methods are strictly limited to watertight surfaces -- another major obstacle for a number of applications. To address these issues, we propose a lightweight Convolutional Neural Network that learns and predicts the unsigned distance field for arbitrary 3D shapes for dense point cloud generation using the recently emerged concept of implicit function learning. Experiments demonstrate that the proposed architecture achieves slightly better quality results than the state of the art with 87% less model parameters and 40% less GPU memory usage.
LightSAL: Lightweight Sign Agnostic Learning for Implicit Surface Representation
Mar 26, 2021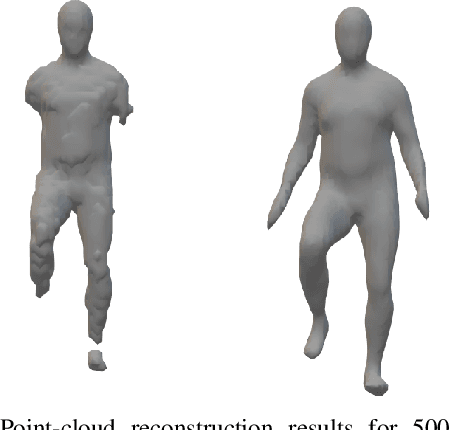

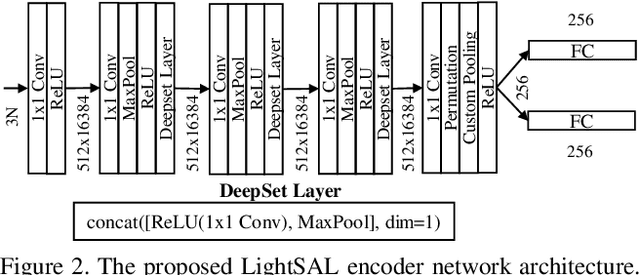

Recently, several works have addressed modeling of 3D shapes using deep neural networks to learn implicit surface representations. Up to now, the majority of works have concentrated on reconstruction quality, paying little or no attention to model size or training time. This work proposes LightSAL, a novel deep convolutional architecture for learning 3D shapes; the proposed work concentrates on efficiency both in network training time and resulting model size. We build on the recent concept of Sign Agnostic Learning for training the proposed network, relying on signed distance fields, with unsigned distance as ground truth. In the experimental section of the paper, we demonstrate that the proposed architecture outperforms previous work in model size and number of required training iterations, while achieving equivalent accuracy. Experiments are based on the D-Faust dataset that contains 41k 3D scans of human shapes. The proposed model has been implemented in PyTorch.
Can You Trust Your Pose? Confidence Estimation in Visual Localization
Oct 01, 2020
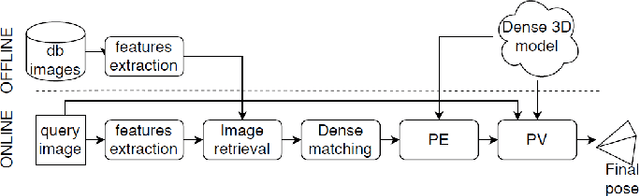
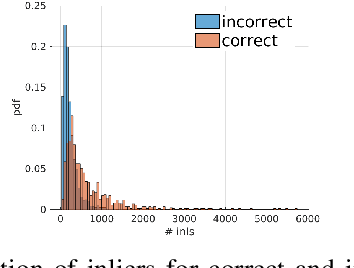

Camera pose estimation in large-scale environments is still an open question and, despite recent promising results, it may still fail in some situations. The research so far has focused on improving subcomponents of estimation pipelines, to achieve more accurate poses. However, there is no guarantee for the result to be correct, even though the correctness of pose estimation is critically important in several visual localization applications,such as in autonomous navigation. In this paper we bring to attention a novel research question, pose confidence estimation,where we aim at quantifying how reliable the visually estimated pose is. We develop a novel confidence measure to fulfil this task and show that it can be flexibly applied to different datasets,indoor or outdoor, and for various visual localization pipelines.We also show that the proposed techniques can be used to accomplish a secondary goal: improving the accuracy of existing pose estimation pipelines. Finally, the proposed approach is computationally light-weight and adds only a negligible increase to the computational effort of pose estimation.
Binarized Convolutional Neural Networks for Efficient Inference on GPUs
Aug 01, 2018

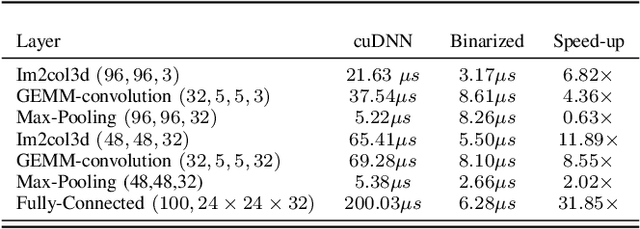

Convolutional neural networks have recently achieved significant breakthroughs in various image classification tasks. However, they are computationally expensive,which can make their feasible mplementation on embedded and low-power devices difficult. In this paper convolutional neural network binarization is implemented on GPU-based platforms for real-time inference on resource constrained devices. In binarized networks, all weights and intermediate computations between layers are quantized to +1 and -1, allowing multiplications and additions to be replaced with bit-wise operations between 32-bit words. This representation completely eliminates the need for floating point multiplications and additions and decreases both the computational load and the memory footprint compared to a full-precision network implemented in floating point, making it well-suited for resource-constrained environments. We compare the performance of our implementation with an equivalent floating point implementation on one desktop and two embedded GPU platforms. Our implementation achieves a maximum speed up of 7. 4X with only 4.4% loss in accuracy compared to a reference implementation.
Embedded Implementation of a Deep Learning Smile Detector
Jul 10, 2018
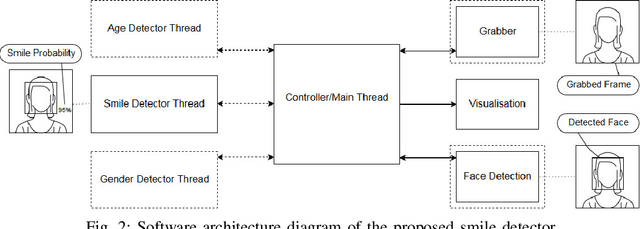

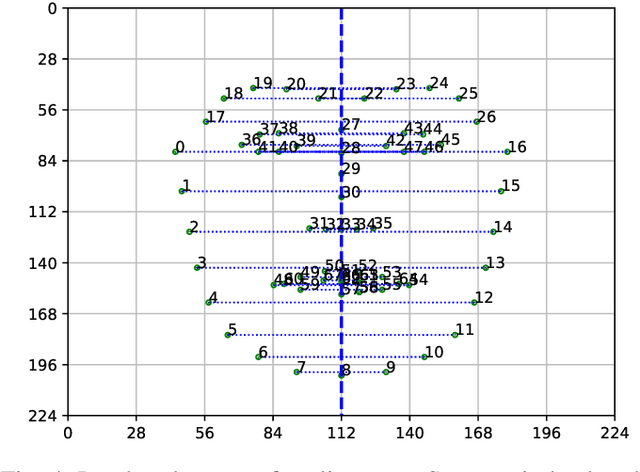
In this paper we study the real time deployment of deep learning algorithms in low resource computational environments. As the use case, we compare the accuracy and speed of neural networks for smile detection using different neural network architectures and their system level implementation on NVidia Jetson embedded platform. We also propose an asynchronous multithreading scheme for parallelizing the pipeline. Within this framework, we experimentally compare thirteen widely used network topologies. The experiments show that low complexity architectures can achieve almost equal performance as larger ones, with a fraction of computation required.