 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSONNET: Enhancing Time Delay Estimation by Leveraging Simulated Audio
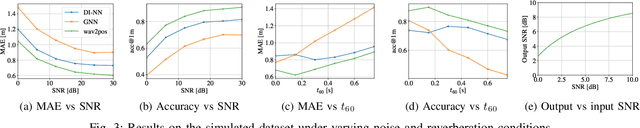
Nov 20, 2024Time delay estimation or Time-Difference-Of-Arrival estimates is a critical component for multiple localization applications such as multilateration, direction of arrival, and self-calibration. The task is to estimate the time difference between a signal arriving at two different sensors. For the audio sensor modality, most current systems are based on classical methods such as the Generalized Cross-Correlation Phase Transform (GCC-PHAT) method. In this paper we demonstrate that learning based methods can, even based on synthetic data, significantly outperform GCC-PHAT on novel real world data. To overcome the lack of data with ground truth for the task, we train our model on a simulated dataset which is sufficiently large and varied, and that captures the relevant characteristics of the real world problem. We provide our trained model, SONNET (Simulation Optimized Neural Network Estimator of Timeshifts), which is runnable in real-time and works on novel data out of the box for many real data applications, i.e. without re-training. We further demonstrate greatly improved performance on the downstream task of self-calibration when using our model compared to classical methods.
The Impact of Semi-Supervised Learning on Line Segment Detection
Nov 07, 2024



In this paper we present a method for line segment detection in images, based on a semi-supervised framework. Leveraging the use of a consistency loss based on differently augmented and perturbed unlabeled images with a small amount of labeled data, we show comparable results to fully supervised methods. This opens up application scenarios where annotation is difficult or expensive, and for domain specific adaptation of models. We are specifically interested in real-time and online applications, and investigate small and efficient learning backbones. Our method is to our knowledge the first to target line detection using modern state-of-the-art methodologies for semi-supervised learning. We test the method on both standard benchmarks and domain specific scenarios for forestry applications, showing the tractability of the proposed method.
Learning Multi-Target TDOA Features for Sound Event Localization and Detection
Aug 30, 2024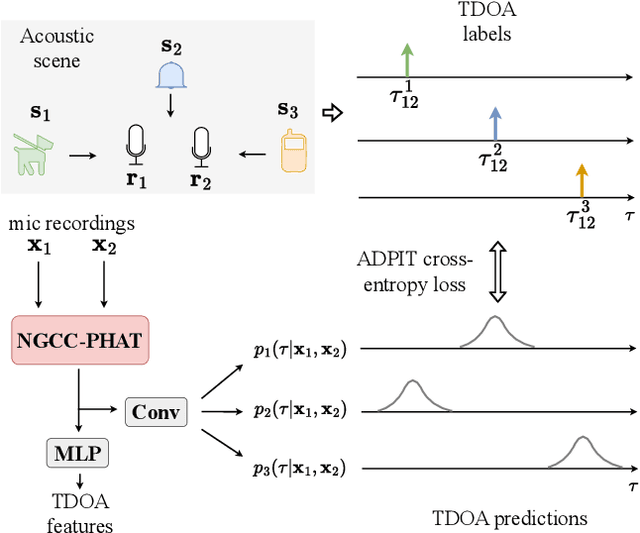
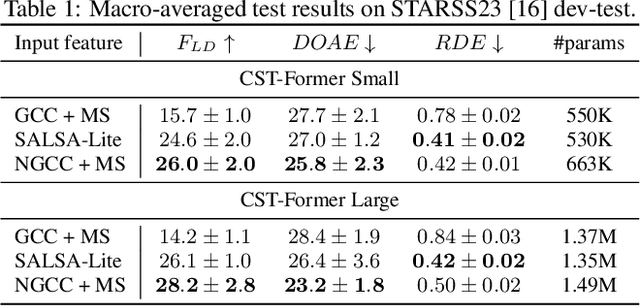
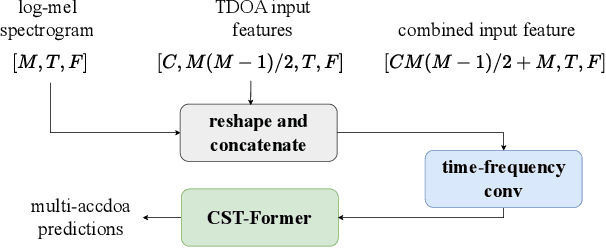

Sound event localization and detection (SELD) systems using audio recordings from a microphone array rely on spatial cues for determining the location of sound events. As a consequence, the localization performance of such systems is to a large extent determined by the quality of the audio features that are used as inputs to the system. We propose a new feature, based on neural generalized cross-correlations with phase-transform (NGCC-PHAT), that learns audio representations suitable for localization. Using permutation invariant training for the time-difference of arrival (TDOA) estimation problem enables NGCC-PHAT to learn TDOA features for multiple overlapping sound events. These features can be used as a drop-in replacement for GCC-PHAT inputs to a SELD-network. We test our method on the STARSS23 dataset and demonstrate improved localization performance compared to using standard GCC-PHAT or SALSA-Lite input features.
wav2pos: Sound Source Localization using Masked Autoencoders
Aug 28, 2024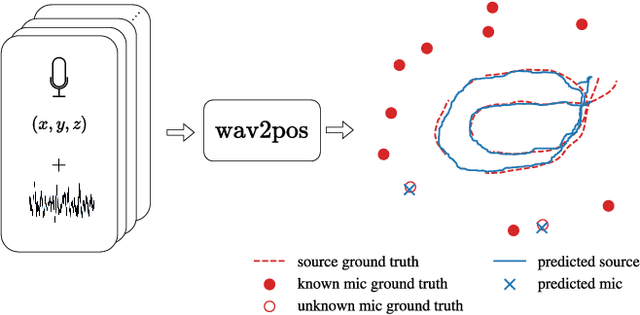
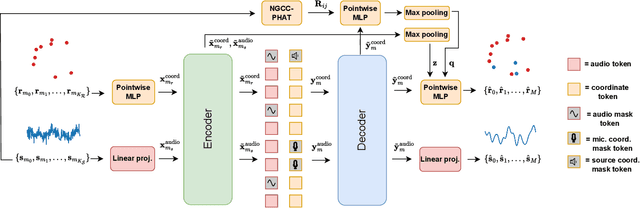

We present a novel approach to the 3D sound source localization task for distributed ad-hoc microphone arrays by formulating it as a set-to-set regression problem. By training a multi-modal masked autoencoder model that operates on audio recordings and microphone coordinates, we show that such a formulation allows for accurate localization of the sound source, by reconstructing coordinates masked in the input. Our approach is flexible in the sense that a single model can be used with an arbitrary number of microphones, even when a subset of audio recordings and microphone coordinates are missing. We test our method on simulated and real-world recordings of music and speech in indoor environments, and demonstrate competitive performance compared to both classical and other learning based localization methods.
Robust and Accurate Cylinder Triangulation
Dec 05, 2022



In this paper we present methods for triangulation of infinite cylinders from image line silhouettes. We show numerically that linear estimation of a general quadric surface is inherently a badly posed problem. Instead we propose to constrain the conic section to a circle, and give algebraic constraints on the dual conic, that models this manifold. Using these constraints we derive a fast minimal solver based on three image silhouette lines, that can be used to bootstrap robust estimation schemes such as RANSAC. We also present a constrained least squares solver that can incorporate all available image lines for accurate estimation. The algorithms are tested on both synthetic and real data, where they are shown to give accurate results, compared to previous methods.
Extending GCC-PHAT using Shift Equivariant Neural Networks
Aug 09, 2022

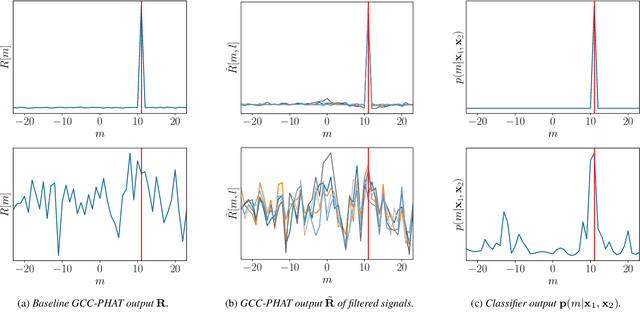

Speaker localization using microphone arrays depends on accurate time delay estimation techniques. For decades, methods based on the generalized cross correlation with phase transform (GCC-PHAT) have been widely adopted for this purpose. Recently, the GCC-PHAT has also been used to provide input features to neural networks in order to remove the effects of noise and reverberation, but at the cost of losing theoretical guarantees in noise-free conditions. We propose a novel approach to extending the GCC-PHAT, where the received signals are filtered using a shift equivariant neural network that preserves the timing information contained in the signals. By extensive experiments we show that our model consistently reduces the error of the GCC-PHAT in adverse environments, with guarantees of exact time delay recovery in ideal conditions.
Multiple Offsets Multilateration: a new paradigm for sensor network calibration with unsynchronized reference nodes
May 23, 2022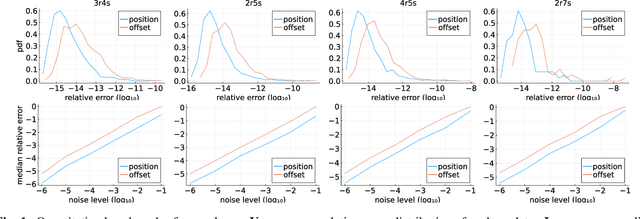
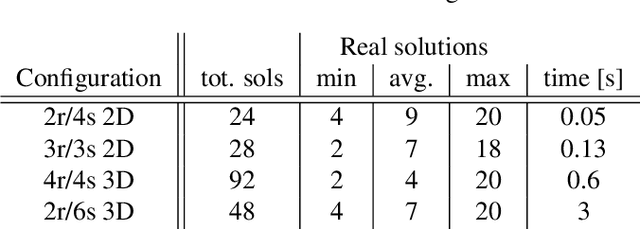
Positioning using wave signal measurements is used in several applications, such as GPS systems, structure from sound and Wifi based positioning. Mathematically, such problems require the computation of the positions of receivers and/or transmitters as well as time offsets if the devices are unsynchronized. In this paper, we expand the previous state-of-the-art on positioning formulations by introducing Multiple Offsets Multilateration (MOM), a new mathematical framework to compute the receivers positions with pseudoranges from unsynchronized reference transmitters at known positions. This could be applied in several scenarios, for example structure from sound and positioning with LEO satellites. We mathematically describe MOM, determining how many receivers and transmitters are needed for the network to be solvable, a study on the number of possible distinct solutions is presented and stable solvers based on homotopy continuation are derived. The solvers are shown to be efficient and robust to noise both for synthetic and real audio data.
Points to Patches: Enabling the Use of Self-Attention for 3D Shape Recognition
Apr 08, 2022
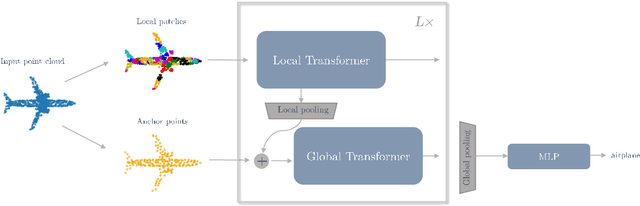

While the Transformer architecture has become ubiquitous in the machine learning field, its adaptation to 3D shape recognition is non-trivial. Due to its quadratic computational complexity, the self-attention operator quickly becomes inefficient as the set of input points grows larger. Furthermore, we find that the attention mechanism struggles to find useful connections between individual points on a global scale. In order to alleviate these problems, we propose a two-stage Point Transformer-in-Transformer (Point-TnT) approach which combines local and global attention mechanisms, enabling both individual points and patches of points to attend to each other effectively. Experiments on shape classification show that such an approach provides more useful features for downstream tasks than the baseline Transformer, while also being more computationally efficient. In addition, we also extend our method to feature matching for scene reconstruction, showing that it can be used in conjunction with existing scene reconstruction pipelines.
Detailed 3D Human Body Reconstruction from Multi-view Images Combining Voxel Super-Resolution and Learned Implicit Representation
Dec 11, 2020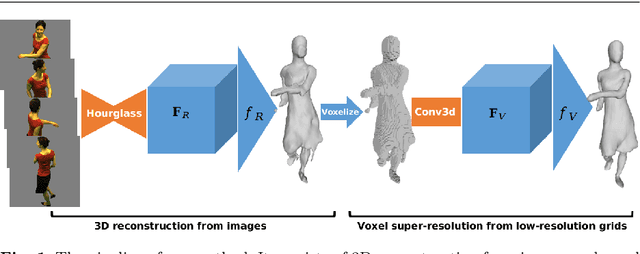



The task of reconstructing detailed 3D human body models from images is interesting but challenging in computer vision due to the high freedom of human bodies. In order to tackle the problem, we propose a coarse-to-fine method to reconstruct a detailed 3D human body from multi-view images combining voxel super-resolution based on learning the implicit representation. Firstly, the coarse 3D models are estimated by learning an implicit representation based on multi-scale features which are extracted by multi-stage hourglass networks from the multi-view images. Then, taking the low resolution voxel grids which are generated by the coarse 3D models as input, the voxel super-resolution based on an implicit representation is learned through a multi-stage 3D convolutional neural network. Finally, the refined detailed 3D human body models can be produced by the voxel super-resolution which can preserve the details and reduce the false reconstruction of the coarse 3D models. Benefiting from the implicit representation, the training process in our method is memory efficient and the detailed 3D human body produced by our method from multi-view images is the continuous decision boundary with high-resolution geometry. In addition, the coarse-to-fine method based on voxel super-resolution can remove false reconstructions and preserve the appearance details in the final reconstruction, simultaneously. In the experiments, our method quantitatively and qualitatively achieves the competitive 3D human body reconstructions from images with various poses and shapes on both the real and synthetic datasets.
A novel joint points and silhouette-based method to estimate 3D human pose and shape
Dec 11, 2020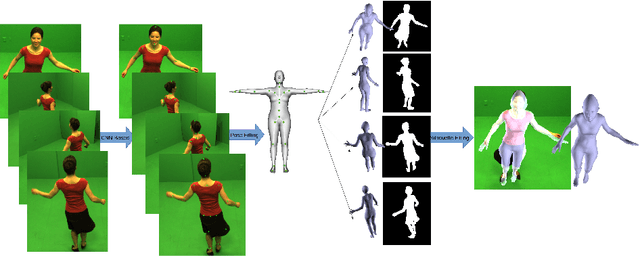
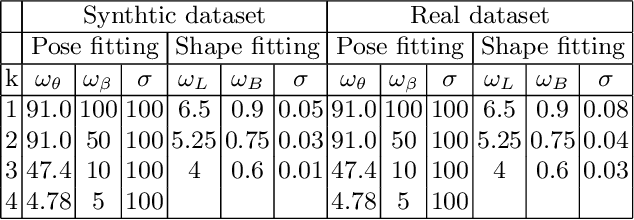
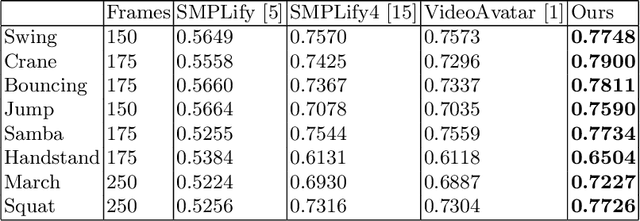
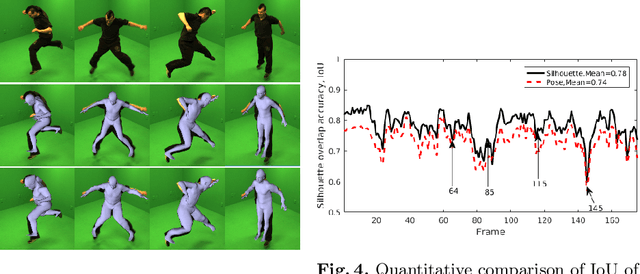
This paper presents a novel method for 3D human pose and shape estimation from images with sparse views, using joint points and silhouettes, based on a parametric model. Firstly, the parametric model is fitted to the joint points estimated by deep learning-based human pose estimation. Then, we extract the correspondence between the parametric model of pose fitting and silhouettes on 2D and 3D space. A novel energy function based on the correspondence is built and minimized to fit parametric model to the silhouettes. Our approach uses sufficient shape information because the energy function of silhouettes is built from both 2D and 3D space. This also means that our method only needs images from sparse views, which balances data used and the required prior information. Results on synthetic data and real data demonstrate the competitive performance of our approach on pose and shape estimation of the human body.