 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoints to Patches: Enabling the Use of Self-Attention for 3D Shape Recognition
Paper and Code

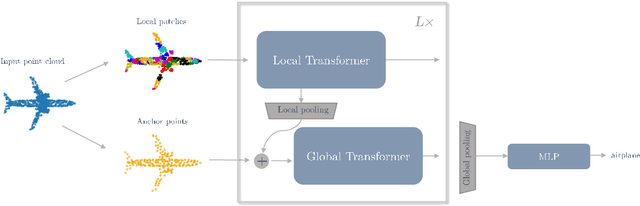

While the Transformer architecture has become ubiquitous in the machine learning field, its adaptation to 3D shape recognition is non-trivial. Due to its quadratic computational complexity, the self-attention operator quickly becomes inefficient as the set of input points grows larger. Furthermore, we find that the attention mechanism struggles to find useful connections between individual points on a global scale. In order to alleviate these problems, we propose a two-stage Point Transformer-in-Transformer (Point-TnT) approach which combines local and global attention mechanisms, enabling both individual points and patches of points to attend to each other effectively. Experiments on shape classification show that such an approach provides more useful features for downstream tasks than the baseline Transformer, while also being more computationally efficient. In addition, we also extend our method to feature matching for scene reconstruction, showing that it can be used in conjunction with existing scene reconstruction pipelines.