 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multi-Target TDOA Features for Sound Event Localization and Detection
Aug 30, 2024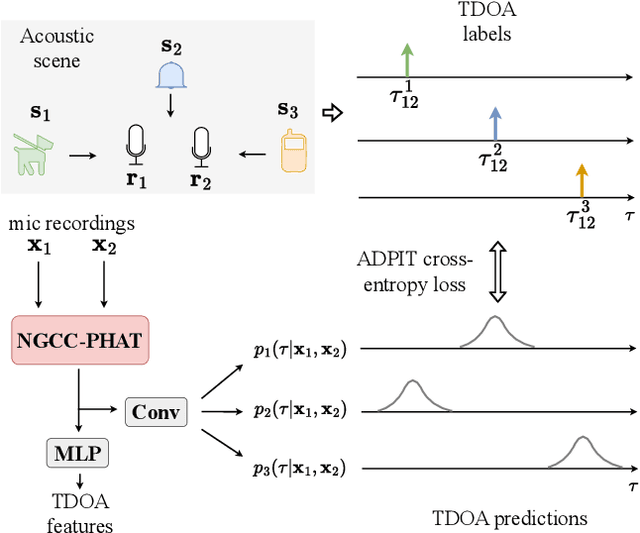
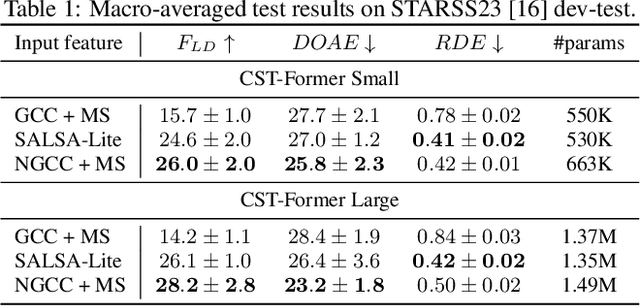
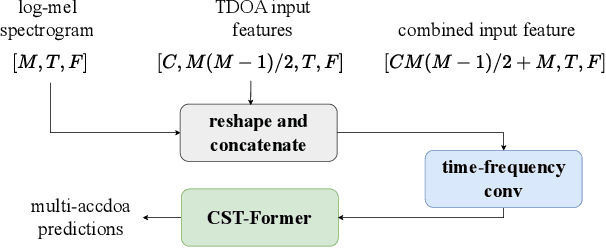

Sound event localization and detection (SELD) systems using audio recordings from a microphone array rely on spatial cues for determining the location of sound events. As a consequence, the localization performance of such systems is to a large extent determined by the quality of the audio features that are used as inputs to the system. We propose a new feature, based on neural generalized cross-correlations with phase-transform (NGCC-PHAT), that learns audio representations suitable for localization. Using permutation invariant training for the time-difference of arrival (TDOA) estimation problem enables NGCC-PHAT to learn TDOA features for multiple overlapping sound events. These features can be used as a drop-in replacement for GCC-PHAT inputs to a SELD-network. We test our method on the STARSS23 dataset and demonstrate improved localization performance compared to using standard GCC-PHAT or SALSA-Lite input features.
wav2pos: Sound Source Localization using Masked Autoencoders
Aug 28, 2024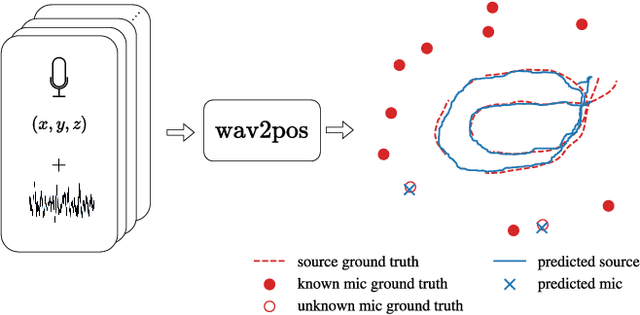
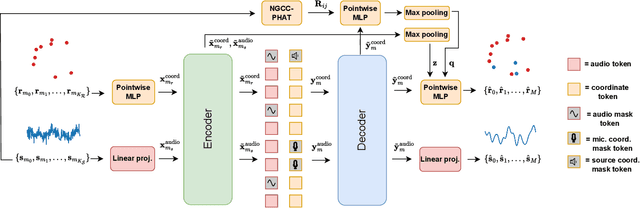
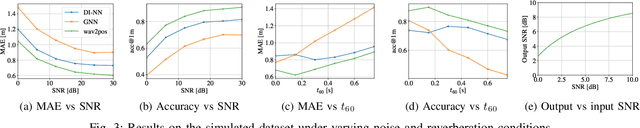

We present a novel approach to the 3D sound source localization task for distributed ad-hoc microphone arrays by formulating it as a set-to-set regression problem. By training a multi-modal masked autoencoder model that operates on audio recordings and microphone coordinates, we show that such a formulation allows for accurate localization of the sound source, by reconstructing coordinates masked in the input. Our approach is flexible in the sense that a single model can be used with an arbitrary number of microphones, even when a subset of audio recordings and microphone coordinates are missing. We test our method on simulated and real-world recordings of music and speech in indoor environments, and demonstrate competitive performance compared to both classical and other learning based localization methods.
Towards Federated Learning with On-device Training and Communication in 8-bit Floating Point
Jul 02, 2024Recent work has shown that 8-bit floating point (FP8) can be used for efficiently training neural networks with reduced computational overhead compared to training in FP32/FP16. In this work, we investigate the use of FP8 training in a federated learning context. This brings not only the usual benefits of FP8 which are desirable for on-device training at the edge, but also reduces client-server communication costs due to significant weight compression. We present a novel method for combining FP8 client training while maintaining a global FP32 server model and provide convergence analysis. Experiments with various machine learning models and datasets show that our method consistently yields communication reductions of at least 2.9x across a variety of tasks and models compared to an FP32 baseline.
Extending GCC-PHAT using Shift Equivariant Neural Networks
Aug 09, 2022

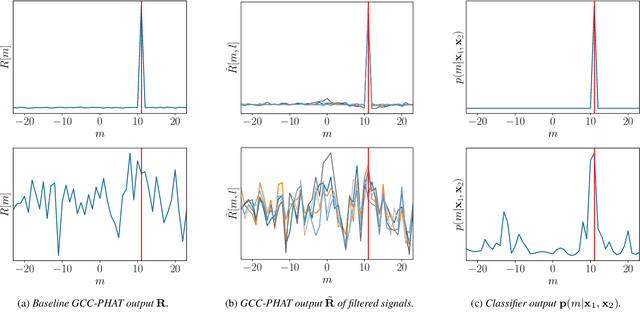

Speaker localization using microphone arrays depends on accurate time delay estimation techniques. For decades, methods based on the generalized cross correlation with phase transform (GCC-PHAT) have been widely adopted for this purpose. Recently, the GCC-PHAT has also been used to provide input features to neural networks in order to remove the effects of noise and reverberation, but at the cost of losing theoretical guarantees in noise-free conditions. We propose a novel approach to extending the GCC-PHAT, where the received signals are filtered using a shift equivariant neural network that preserves the timing information contained in the signals. By extensive experiments we show that our model consistently reduces the error of the GCC-PHAT in adverse environments, with guarantees of exact time delay recovery in ideal conditions.
Points to Patches: Enabling the Use of Self-Attention for 3D Shape Recognition
Apr 08, 2022
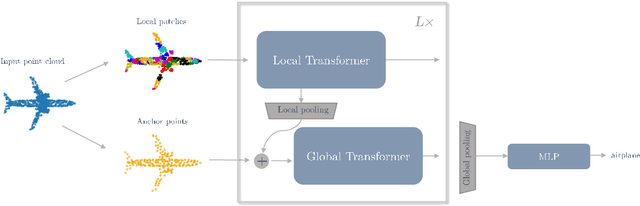
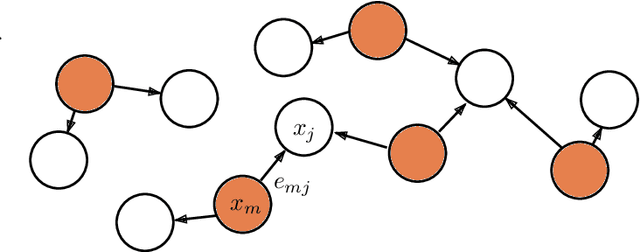

While the Transformer architecture has become ubiquitous in the machine learning field, its adaptation to 3D shape recognition is non-trivial. Due to its quadratic computational complexity, the self-attention operator quickly becomes inefficient as the set of input points grows larger. Furthermore, we find that the attention mechanism struggles to find useful connections between individual points on a global scale. In order to alleviate these problems, we propose a two-stage Point Transformer-in-Transformer (Point-TnT) approach which combines local and global attention mechanisms, enabling both individual points and patches of points to attend to each other effectively. Experiments on shape classification show that such an approach provides more useful features for downstream tasks than the baseline Transformer, while also being more computationally efficient. In addition, we also extend our method to feature matching for scene reconstruction, showing that it can be used in conjunction with existing scene reconstruction pipelines.
Keyword Transformer: A Self-Attention Model for Keyword Spotting
Apr 15, 2021

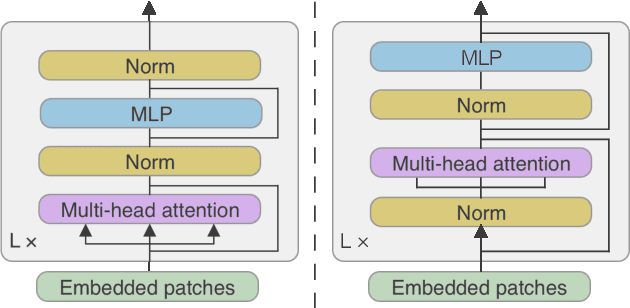

The Transformer architecture has been successful across many domains, including natural language processing, computer vision and speech recognition. In keyword spotting, self-attention has primarily been used on top of convolutional or recurrent encoders. We investigate a range of ways to adapt the Transformer architecture to keyword spotting and introduce the Keyword Transformer (KWT), a fully self-attentional architecture that exceeds state-of-the-art performance across multiple tasks without any pre-training or additional data. Surprisingly, this simple architecture outperforms more complex models that mix convolutional, recurrent and attentive layers. KWT can be used as a drop-in replacement for these models, setting two new benchmark records on the Google Speech Commands dataset with 98.6% and 97.7% accuracy on the 12 and 35-command tasks respectively.
Deep Ordinal Regression with Label Diversity
Jun 29, 2020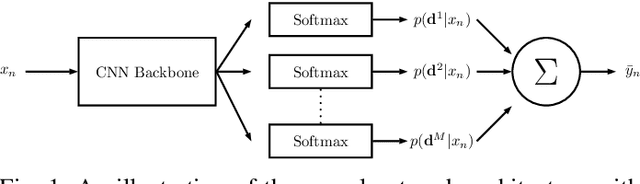
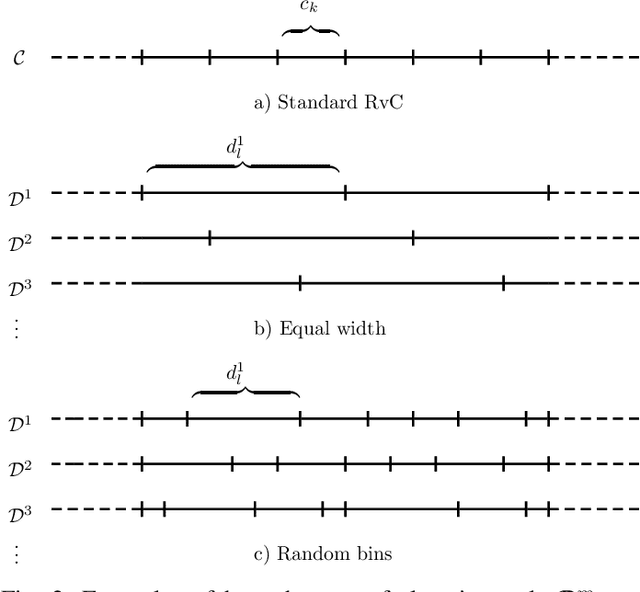


Regression via classification (RvC) is a common method used for regression problems in deep learning, where the target variable belongs to a set of continuous values. By discretizing the target into a set of non-overlapping classes, it has been shown that training a classifier can improve neural network accuracy compared to using a standard regression approach. However, it is not clear how the set of discrete classes should be chosen and how it affects the overall solution. In this work, we propose that using several discrete data representations simultaneously can improve neural network learning compared to a single representation. Our approach is end-to-end differentiable and can be added as a simple extension to conventional learning methods, such as deep neural networks. We test our method on three challenging tasks and show that our method reduces the prediction error compared to a baseline RvC approach while maintaining a similar model complexity.