 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Multiview Open-Vocabulary 3D Detection
Sep 19, 2025
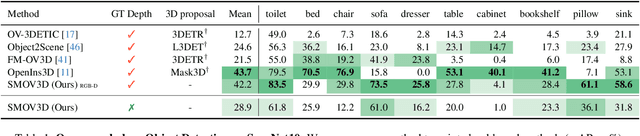

The ability to interpret and comprehend a 3D scene is essential for many vision and robotics systems. In numerous applications, this involves 3D object detection, i.e.~identifying the location and dimensions of objects belonging to a specific category, typically represented as bounding boxes. This has traditionally been solved by training to detect a fixed set of categories, which limits its use. In this work, we investigate open-vocabulary 3D object detection in the challenging yet practical sparse-view setting, where only a limited number of posed RGB images are available as input. Our approach is training-free, relying on pre-trained, off-the-shelf 2D foundation models instead of employing computationally expensive 3D feature fusion or requiring 3D-specific learning. By lifting 2D detections and directly optimizing 3D proposals for featuremetric consistency across views, we fully leverage the extensive training data available in 2D compared to 3D. Through standard benchmarks, we demonstrate that this simple pipeline establishes a powerful baseline, performing competitively with state-of-the-art techniques in densely sampled scenarios while significantly outperforming them in the sparse-view setting.
PixCuboid: Room Layout Estimation from Multi-view Featuremetric Alignment
Aug 06, 2025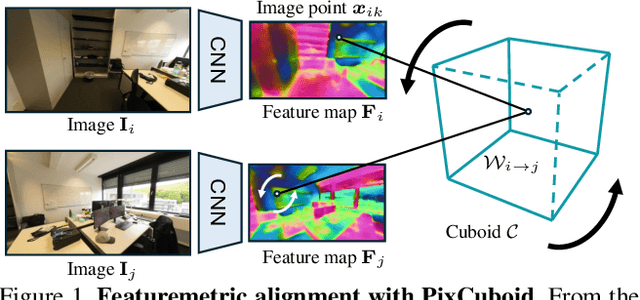
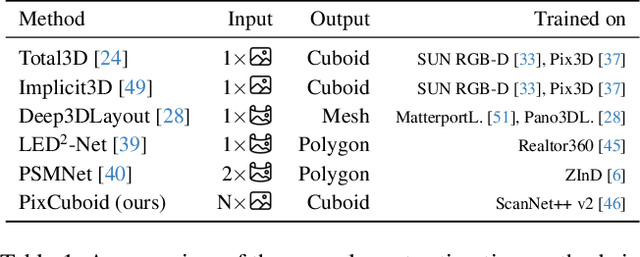
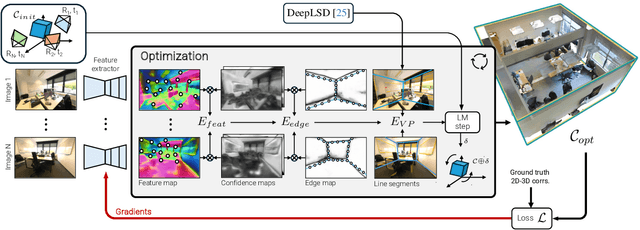
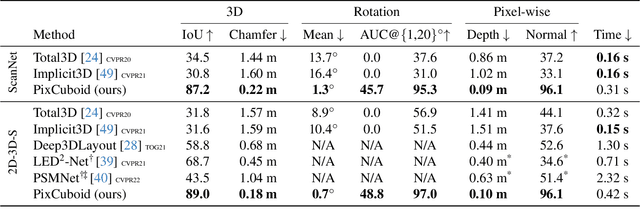
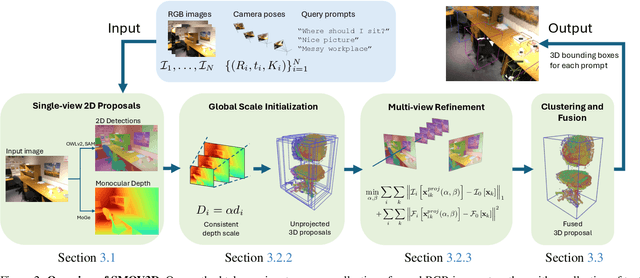
Coarse room layout estimation provides important geometric cues for many downstream tasks. Current state-of-the-art methods are predominantly based on single views and often assume panoramic images. We introduce PixCuboid, an optimization-based approach for cuboid-shaped room layout estimation, which is based on multi-view alignment of dense deep features. By training with the optimization end-to-end, we learn feature maps that yield large convergence basins and smooth loss landscapes in the alignment. This allows us to initialize the room layout using simple heuristics. For the evaluation we propose two new benchmarks based on ScanNet++ and 2D-3D-Semantics, with manually verified ground truth 3D cuboids. In thorough experiments we validate our approach and significantly outperform the competition. Finally, while our network is trained with single cuboids, the flexibility of the optimization-based approach allow us to easily extend to multi-room estimation, e.g. larger apartments or offices. Code and model weights are available at https://github.com/ghanning/PixCuboid.
SONNET: Enhancing Time Delay Estimation by Leveraging Simulated Audio
Nov 20, 2024Time delay estimation or Time-Difference-Of-Arrival estimates is a critical component for multiple localization applications such as multilateration, direction of arrival, and self-calibration. The task is to estimate the time difference between a signal arriving at two different sensors. For the audio sensor modality, most current systems are based on classical methods such as the Generalized Cross-Correlation Phase Transform (GCC-PHAT) method. In this paper we demonstrate that learning based methods can, even based on synthetic data, significantly outperform GCC-PHAT on novel real world data. To overcome the lack of data with ground truth for the task, we train our model on a simulated dataset which is sufficiently large and varied, and that captures the relevant characteristics of the real world problem. We provide our trained model, SONNET (Simulation Optimized Neural Network Estimator of Timeshifts), which is runnable in real-time and works on novel data out of the box for many real data applications, i.e. without re-training. We further demonstrate greatly improved performance on the downstream task of self-calibration when using our model compared to classical methods.
NeuroNCAP: Photorealistic Closed-loop Safety Testing for Autonomous Driving
Apr 12, 2024



We present a versatile NeRF-based simulator for testing autonomous driving (AD) software systems, designed with a focus on sensor-realistic closed-loop evaluation and the creation of safety-critical scenarios. The simulator learns from sequences of real-world driving sensor data and enables reconfigurations and renderings of new, unseen scenarios. In this work, we use our simulator to test the responses of AD models to safety-critical scenarios inspired by the European New Car Assessment Programme (Euro NCAP). Our evaluation reveals that, while state-of-the-art end-to-end planners excel in nominal driving scenarios in an open-loop setting, they exhibit critical flaws when navigating our safety-critical scenarios in a closed-loop setting. This highlights the need for advancements in the safety and real-world usability of end-to-end planners. By publicly releasing our simulator and scenarios as an easy-to-run evaluation suite, we invite the research community to explore, refine, and validate their AD models in controlled, yet highly configurable and challenging sensor-realistic environments. Code and instructions can be found at https://github.com/wljungbergh/NeuroNCAP
Geometry-Biased Transformer for Robust Multi-View 3D Human Pose Reconstruction
Dec 28, 2023

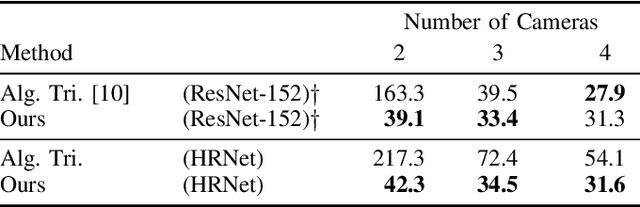

We address the challenges in estimating 3D human poses from multiple views under occlusion and with limited overlapping views. We approach multi-view, single-person 3D human pose reconstruction as a regression problem and propose a novel encoder-decoder Transformer architecture to estimate 3D poses from multi-view 2D pose sequences. The encoder refines 2D skeleton joints detected across different views and times, fusing multi-view and temporal information through global self-attention. We enhance the encoder by incorporating a geometry-biased attention mechanism, effectively leveraging geometric relationships between views. Additionally, we use detection scores provided by the 2D pose detector to further guide the encoder's attention based on the reliability of the 2D detections. The decoder subsequently regresses the 3D pose sequence from these refined tokens, using pre-defined queries for each joint. To enhance the generalization of our method to unseen scenes and improve resilience to missing joints, we implement strategies including scene centering, synthetic views, and token dropout. We conduct extensive experiments on three benchmark public datasets, Human3.6M, CMU Panoptic and Occlusion-Persons. Our results demonstrate the efficacy of our approach, particularly in occluded scenes and when few views are available, which are traditionally challenging scenarios for triangulation-based methods.
Polygon Detection for Room Layout Estimation using Heterogeneous Graphs and Wireframes
Jun 21, 2023



This paper presents a neural network based semantic plane detection method utilizing polygon representations. The method can for example be used to solve room layout estimations tasks. The method is built on, combines and further develops several different modules from previous research. The network takes an RGB image and estimates a wireframe as well as a feature space using an hourglass backbone. From these, line and junction features are sampled. The lines and junctions are then represented as an undirected graph, from which polygon representations of the sought planes are obtained. Two different methods for this last step are investigated, where the most promising method is built on a heterogeneous graph transformer. The final output is in all cases a projection of the semantic planes in 2D. The methods are evaluated on the Structured 3D dataset and we investigate the performance both using sampled and estimated wireframes. The experiments show the potential of the graph-based method by outperforming state of the art methods in Room Layout estimation in the 2D metrics using synthetic wireframe detections.
The LuViRA Dataset: Measurement Description
Feb 10, 2023



We present a dataset to evaluate localization algorithms, which utilizes vision, audio, and radio sensors: the Lund University Vision, Radio, and Audio (LuViRA) Dataset. The dataset includes RGB images, corresponding depth maps, IMU readings, channel response between a massive MIMO channel sounder and a user equipment, audio recorded by 12 microphones, and 0.5 mm accurate 6DoF pose ground truth. We synchronize these sensors to make sure that all data are recorded simultaneously. A camera, speaker, and transmit antenna are placed on top of a slowly moving service robot and 88 trajectories are recorded. Each trajectory includes 20 to 50 seconds of recorded sensor data and ground truth labels. The data from different sensors can be used separately or jointly to conduct localization tasks and a motion capture system is used to verify the results obtained by the localization algorithms. The main aim of this dataset is to enable research on fusing the most commonly used sensors for localization tasks. However, the full dataset or some parts of it can also be used for other research areas such as channel estimation, image classification, etc. Fusing sensor data can lead to increased localization accuracy and reliability, as well as decreased latency and power consumption. The created dataset will be made public at a later date.
LidarCLIP or: How I Learned to Talk to Point Clouds
Dec 13, 2022



Research connecting text and images has recently seen several breakthroughs, with models like CLIP, DALL-E 2, and Stable Diffusion. However, the connection between text and other visual modalities, such as lidar data, has received less attention, prohibited by the lack of text-lidar datasets. In this work, we propose LidarCLIP, a mapping from automotive point clouds to a pre-existing CLIP embedding space. Using image-lidar pairs, we supervise a point cloud encoder with the image CLIP embeddings, effectively relating text and lidar data with the image domain as an intermediary. We show the effectiveness of LidarCLIP by demonstrating that lidar-based retrieval is generally on par with image-based retrieval, but with complementary strengths and weaknesses. By combining image and lidar features, we improve upon both single-modality methods and enable a targeted search for challenging detection scenarios under adverse sensor conditions. We also use LidarCLIP as a tool to investigate fundamental lidar capabilities through natural language. Finally, we leverage our compatibility with CLIP to explore a range of applications, such as point cloud captioning and lidar-to-image generation, without any additional training. We hope LidarCLIP can inspire future work to dive deeper into connections between text and point cloud understanding. Code and trained models available at https://github.com/atonderski/lidarclip.
Aerial View Goal Localization with Reinforcement Learning
Sep 08, 2022
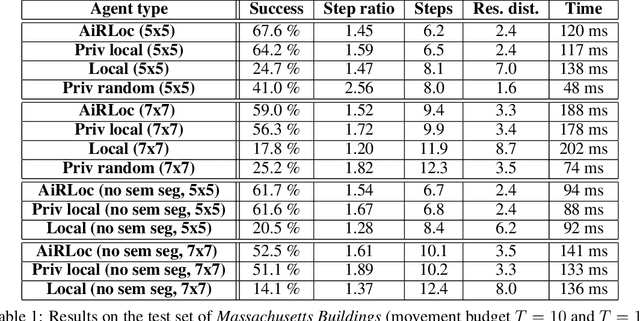
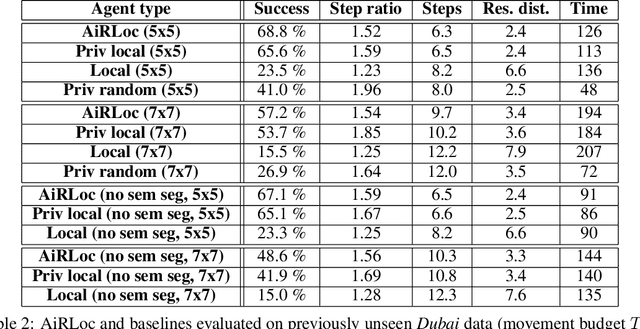
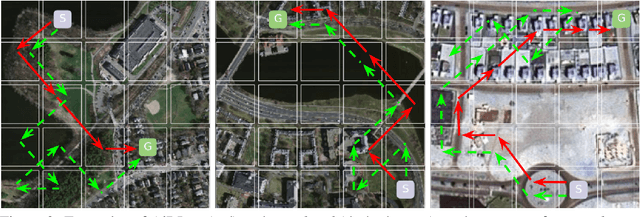
With an increased amount and availability of unmanned aerial vehicles (UAVs) and other remote sensing devices (e.g. satellites), we have recently seen a vast increase in computer vision methods for aerial view data. One application of such technologies is within search-and-rescue (SAR), where the task is to localize and assist one or several people who are missing, for example after a natural disaster. In many cases the rough location may be known and a UAV can be deployed to explore a given, confined area to precisely localize the missing people. Due to time and battery constraints it is often critical that localization is performed as efficiently as possible. In this work, we approach this type of problem by abstracting it as an aerial view goal localization task in a framework that emulates a SAR-like setup without requiring access to actual UAVs. In this framework, an agent operates on top of an aerial image (proxy for a search area) and is tasked with localizing a goal that is described in terms of visual cues. To further mimic the situation on an actual UAV, the agent is not able to observe the search area in its entirety, not even at low resolution, and thus it has to operate solely based on partial glimpses when navigating towards the goal. To tackle this task, we propose AiRLoc, a reinforcement learning (RL)-based model that decouples exploration (searching for distant goals) and exploitation (localizing nearby goals). Extensive evaluations show that AiRLoc outperforms heuristic search methods as well as alternative learnable approaches. We also conduct a proof-of-concept study which indicates that the learnable methods outperform humans on average. Code has been made publicly available: https://github.com/aleksispi/airloc.
Extending GCC-PHAT using Shift Equivariant Neural Networks
Aug 09, 2022

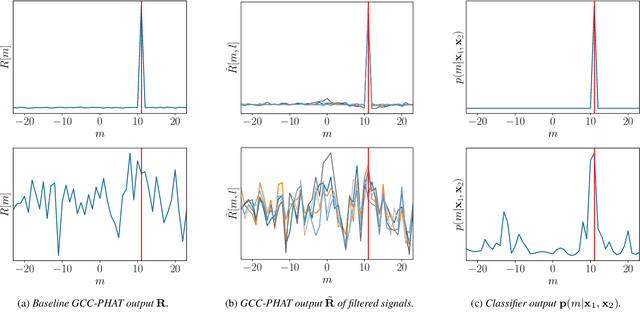

Speaker localization using microphone arrays depends on accurate time delay estimation techniques. For decades, methods based on the generalized cross correlation with phase transform (GCC-PHAT) have been widely adopted for this purpose. Recently, the GCC-PHAT has also been used to provide input features to neural networks in order to remove the effects of noise and reverberation, but at the cost of losing theoretical guarantees in noise-free conditions. We propose a novel approach to extending the GCC-PHAT, where the received signals are filtered using a shift equivariant neural network that preserves the timing information contained in the signals. By extensive experiments we show that our model consistently reduces the error of the GCC-PHAT in adverse environments, with guarantees of exact time delay recovery in ideal conditions.