 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Biased Transformer for Robust Multi-View 3D Human Pose Reconstruction
Dec 28, 2023

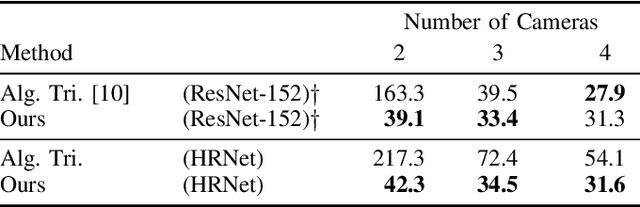

We address the challenges in estimating 3D human poses from multiple views under occlusion and with limited overlapping views. We approach multi-view, single-person 3D human pose reconstruction as a regression problem and propose a novel encoder-decoder Transformer architecture to estimate 3D poses from multi-view 2D pose sequences. The encoder refines 2D skeleton joints detected across different views and times, fusing multi-view and temporal information through global self-attention. We enhance the encoder by incorporating a geometry-biased attention mechanism, effectively leveraging geometric relationships between views. Additionally, we use detection scores provided by the 2D pose detector to further guide the encoder's attention based on the reliability of the 2D detections. The decoder subsequently regresses the 3D pose sequence from these refined tokens, using pre-defined queries for each joint. To enhance the generalization of our method to unseen scenes and improve resilience to missing joints, we implement strategies including scene centering, synthetic views, and token dropout. We conduct extensive experiments on three benchmark public datasets, Human3.6M, CMU Panoptic and Occlusion-Persons. Our results demonstrate the efficacy of our approach, particularly in occluded scenes and when few views are available, which are traditionally challenging scenarios for triangulation-based methods.
Bootstrapped Representation Learning for Skeleton-Based Action Recognition
Feb 04, 2022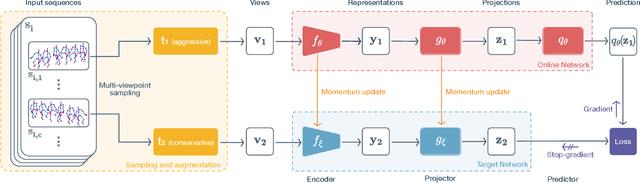
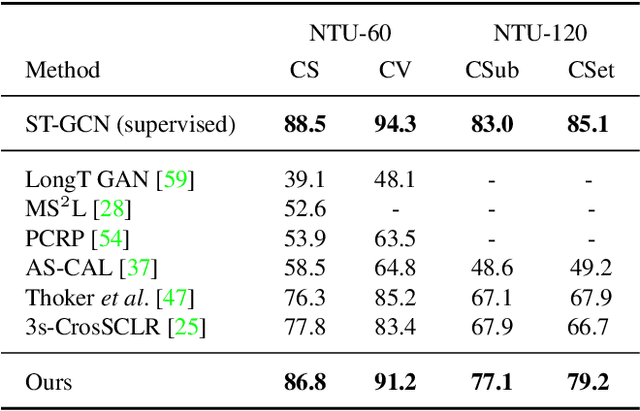
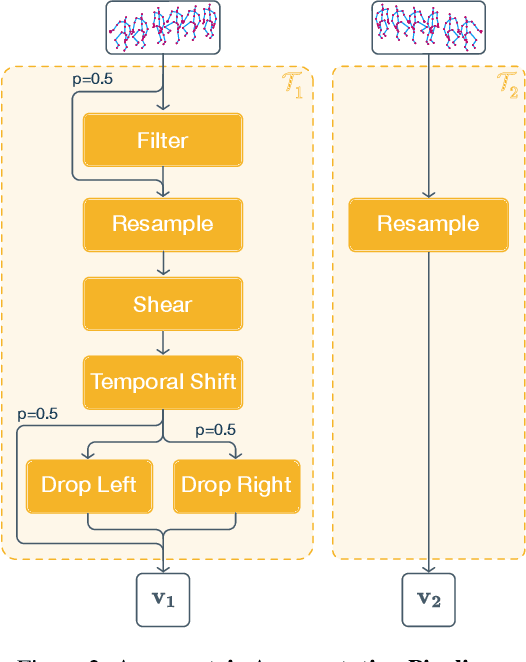
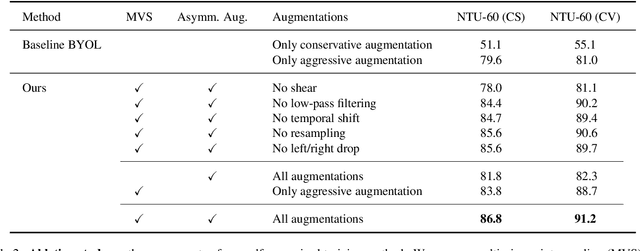
In this work, we study self-supervised representation learning for 3D skeleton-based action recognition. We extend Bootstrap Your Own Latent (BYOL) for representation learning on skeleton sequence data and propose a new data augmentation strategy including two asymmetric transformation pipelines. We also introduce a multi-viewpoint sampling method that leverages multiple viewing angles of the same action captured by different cameras. In the semi-supervised setting, we show that the performance can be further improved by knowledge distillation from wider networks, leveraging once more the unlabeled samples. We conduct extensive experiments on the NTU-60 and NTU-120 datasets to demonstrate the performance of our proposed method. Our method consistently outperforms the current state of the art on both linear evaluation and semi-supervised benchmarks.
Adversarial Attacks and Defences Competition
Mar 31, 2018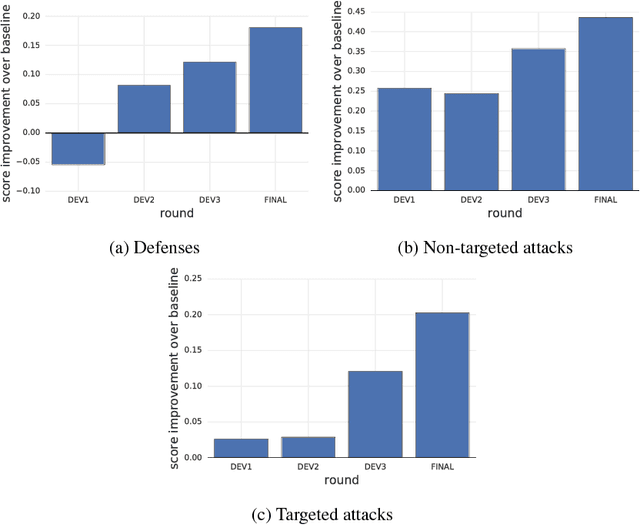
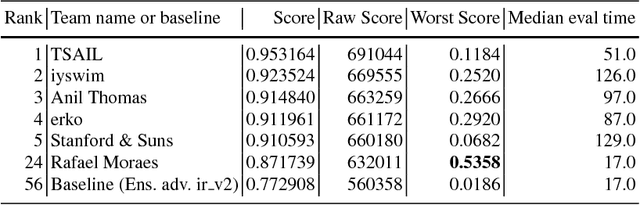
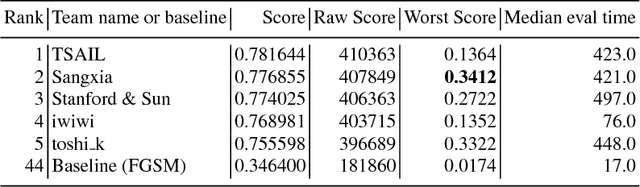
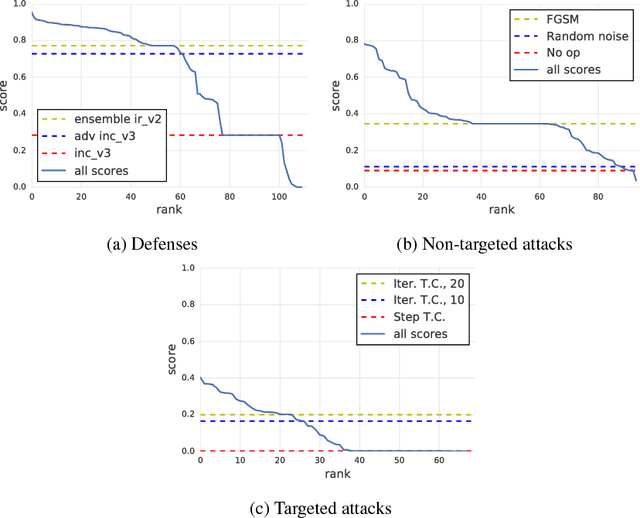
To accelerate research on adversarial examples and robustness of machine learning classifiers, Google Brain organized a NIPS 2017 competition that encouraged researchers to develop new methods to generate adversarial examples as well as to develop new ways to defend against them. In this chapter, we describe the structure and organization of the competition and the solutions developed by several of the top-placing teams.