 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Biased Transformer for Robust Multi-View 3D Human Pose Reconstruction
Paper and Code
Dec 28, 2023

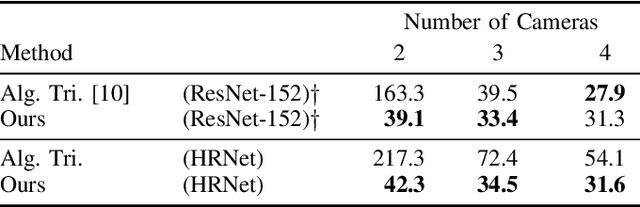

We address the challenges in estimating 3D human poses from multiple views under occlusion and with limited overlapping views. We approach multi-view, single-person 3D human pose reconstruction as a regression problem and propose a novel encoder-decoder Transformer architecture to estimate 3D poses from multi-view 2D pose sequences. The encoder refines 2D skeleton joints detected across different views and times, fusing multi-view and temporal information through global self-attention. We enhance the encoder by incorporating a geometry-biased attention mechanism, effectively leveraging geometric relationships between views. Additionally, we use detection scores provided by the 2D pose detector to further guide the encoder's attention based on the reliability of the 2D detections. The decoder subsequently regresses the 3D pose sequence from these refined tokens, using pre-defined queries for each joint. To enhance the generalization of our method to unseen scenes and improve resilience to missing joints, we implement strategies including scene centering, synthetic views, and token dropout. We conduct extensive experiments on three benchmark public datasets, Human3.6M, CMU Panoptic and Occlusion-Persons. Our results demonstrate the efficacy of our approach, particularly in occluded scenes and when few views are available, which are traditionally challenging scenarios for triangulation-based methods.