 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSONNET: Enhancing Time Delay Estimation by Leveraging Simulated Audio
Nov 20, 2024Time delay estimation or Time-Difference-Of-Arrival estimates is a critical component for multiple localization applications such as multilateration, direction of arrival, and self-calibration. The task is to estimate the time difference between a signal arriving at two different sensors. For the audio sensor modality, most current systems are based on classical methods such as the Generalized Cross-Correlation Phase Transform (GCC-PHAT) method. In this paper we demonstrate that learning based methods can, even based on synthetic data, significantly outperform GCC-PHAT on novel real world data. To overcome the lack of data with ground truth for the task, we train our model on a simulated dataset which is sufficiently large and varied, and that captures the relevant characteristics of the real world problem. We provide our trained model, SONNET (Simulation Optimized Neural Network Estimator of Timeshifts), which is runnable in real-time and works on novel data out of the box for many real data applications, i.e. without re-training. We further demonstrate greatly improved performance on the downstream task of self-calibration when using our model compared to classical methods.
Indoor Localization Using Radio, Vision and Audio Sensors: Real-Life Data Validation and Discussion
Sep 06, 2023
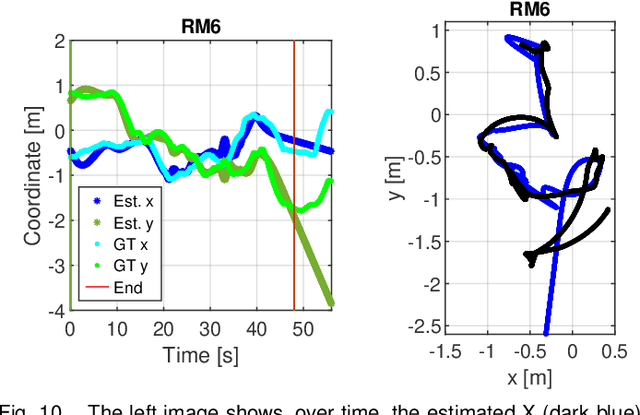
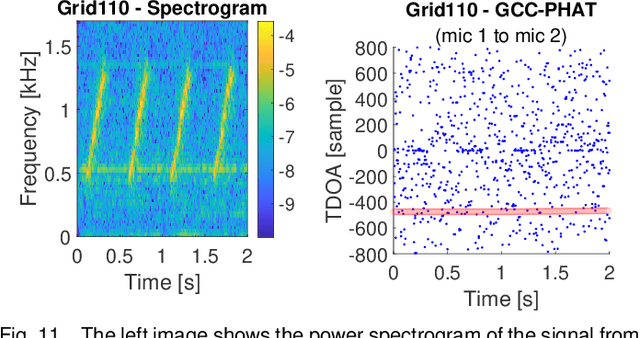

This paper investigates indoor localization methods using radio, vision, and audio sensors, respectively, in the same environment. The evaluation is based on state-of-the-art algorithms and uses a real-life dataset. More specifically, we evaluate a machine learning algorithm for radio-based localization with massive MIMO technology, an ORB-SLAM3 algorithm for vision-based localization with an RGB-D camera, and an SFS2 algorithm for audio-based localization with microphone arrays. Aspects including localization accuracy, reliability, calibration requirements, and potential system complexity are discussed to analyze the advantages and limitations of using different sensors for indoor localization tasks. The results can serve as a guideline and basis for further development of robust and high-precision multi-sensory localization systems, e.g., through sensor fusion and context and environment-aware adaptation.
The LuViRA Dataset: Measurement Description
Feb 10, 2023



We present a dataset to evaluate localization algorithms, which utilizes vision, audio, and radio sensors: the Lund University Vision, Radio, and Audio (LuViRA) Dataset. The dataset includes RGB images, corresponding depth maps, IMU readings, channel response between a massive MIMO channel sounder and a user equipment, audio recorded by 12 microphones, and 0.5 mm accurate 6DoF pose ground truth. We synchronize these sensors to make sure that all data are recorded simultaneously. A camera, speaker, and transmit antenna are placed on top of a slowly moving service robot and 88 trajectories are recorded. Each trajectory includes 20 to 50 seconds of recorded sensor data and ground truth labels. The data from different sensors can be used separately or jointly to conduct localization tasks and a motion capture system is used to verify the results obtained by the localization algorithms. The main aim of this dataset is to enable research on fusing the most commonly used sensors for localization tasks. However, the full dataset or some parts of it can also be used for other research areas such as channel estimation, image classification, etc. Fusing sensor data can lead to increased localization accuracy and reliability, as well as decreased latency and power consumption. The created dataset will be made public at a later date.