 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR3D2: Realistic 3D Asset Insertion via Diffusion for Autonomous Driving Simulation
Jun 09, 2025



Validating autonomous driving (AD) systems requires diverse and safety-critical testing, making photorealistic virtual environments essential. Traditional simulation platforms, while controllable, are resource-intensive to scale and often suffer from a domain gap with real-world data. In contrast, neural reconstruction methods like 3D Gaussian Splatting (3DGS) offer a scalable solution for creating photorealistic digital twins of real-world driving scenes. However, they struggle with dynamic object manipulation and reusability as their per-scene optimization-based methodology tends to result in incomplete object models with integrated illumination effects. This paper introduces R3D2, a lightweight, one-step diffusion model designed to overcome these limitations and enable realistic insertion of complete 3D assets into existing scenes by generating plausible rendering effects-such as shadows and consistent lighting-in real time. This is achieved by training R3D2 on a novel dataset: 3DGS object assets are generated from in-the-wild AD data using an image-conditioned 3D generative model, and then synthetically placed into neural rendering-based virtual environments, allowing R3D2 to learn realistic integration. Quantitative and qualitative evaluations demonstrate that R3D2 significantly enhances the realism of inserted assets, enabling use-cases like text-to-3D asset insertion and cross-scene/dataset object transfer, allowing for true scalability in AD validation. To promote further research in scalable and realistic AD simulation, we will release our dataset and code, see https://research.zenseact.com/publications/R3D2/.
NeuroNCAP: Photorealistic Closed-loop Safety Testing for Autonomous Driving
Apr 12, 2024



We present a versatile NeRF-based simulator for testing autonomous driving (AD) software systems, designed with a focus on sensor-realistic closed-loop evaluation and the creation of safety-critical scenarios. The simulator learns from sequences of real-world driving sensor data and enables reconfigurations and renderings of new, unseen scenarios. In this work, we use our simulator to test the responses of AD models to safety-critical scenarios inspired by the European New Car Assessment Programme (Euro NCAP). Our evaluation reveals that, while state-of-the-art end-to-end planners excel in nominal driving scenarios in an open-loop setting, they exhibit critical flaws when navigating our safety-critical scenarios in a closed-loop setting. This highlights the need for advancements in the safety and real-world usability of end-to-end planners. By publicly releasing our simulator and scenarios as an easy-to-run evaluation suite, we invite the research community to explore, refine, and validate their AD models in controlled, yet highly configurable and challenging sensor-realistic environments. Code and instructions can be found at https://github.com/wljungbergh/NeuroNCAP
TimePillars: Temporally-Recurrent 3D LiDAR Object Detection
Dec 22, 2023Object detection applied to LiDAR point clouds is a relevant task in robotics, and particularly in autonomous driving. Single frame methods, predominant in the field, exploit information from individual sensor scans. Recent approaches achieve good performance, at relatively low inference time. Nevertheless, given the inherent high sparsity of LiDAR data, these methods struggle in long-range detection (e.g. 200m) which we deem to be critical in achieving safe automation. Aggregating multiple scans not only leads to a denser point cloud representation, but it also brings time-awareness to the system, and provides information about how the environment is changing. Solutions of this kind, however, are often highly problem-specific, demand careful data processing, and tend not to fulfil runtime requirements. In this context we propose TimePillars, a temporally-recurrent object detection pipeline which leverages the pillar representation of LiDAR data across time, respecting hardware integration efficiency constraints, and exploiting the diversity and long-range information of the novel Zenseact Open Dataset (ZOD). Through experimentation, we prove the benefits of having recurrency, and show how basic building blocks are enough to achieve robust and efficient results.
NeuRAD: Neural Rendering for Autonomous Driving
Dec 05, 2023



Neural radiance fields (NeRFs) have gained popularity in the autonomous driving (AD) community. Recent methods show NeRFs' potential for closed-loop simulation, enabling testing of AD systems, and as an advanced training data augmentation technique. However, existing methods often require long training times, dense semantic supervision, or lack generalizability. This, in turn, hinders the application of NeRFs for AD at scale. In this paper, we propose NeuRAD, a robust novel view synthesis method tailored to dynamic AD data. Our method features simple network design, extensive sensor modeling for both camera and lidar -- including rolling shutter, beam divergence and ray dropping -- and is applicable to multiple datasets out of the box. We verify its performance on five popular AD datasets, achieving state-of-the-art performance across the board. To encourage further development, we will openly release the NeuRAD source code. See https://github.com/georghess/NeuRAD .
You can have your ensemble and run it too -- Deep Ensembles Spread Over Time
Sep 20, 2023Ensembles of independently trained deep neural networks yield uncertainty estimates that rival Bayesian networks in performance. They also offer sizable improvements in terms of predictive performance over single models. However, deep ensembles are not commonly used in environments with limited computational budget -- such as autonomous driving -- since the complexity grows linearly with the number of ensemble members. An important observation that can be made for robotics applications, such as autonomous driving, is that data is typically sequential. For instance, when an object is to be recognized, an autonomous vehicle typically observes a sequence of images, rather than a single image. This raises the question, could the deep ensemble be spread over time? In this work, we propose and analyze Deep Ensembles Spread Over Time (DESOT). The idea is to apply only a single ensemble member to each data point in the sequence, and fuse the predictions over a sequence of data points. We implement and experiment with DESOT for traffic sign classification, where sequences of tracked image patches are to be classified. We find that DESOT obtains the benefits of deep ensembles, in terms of predictive and uncertainty estimation performance, while avoiding the added computational cost. Moreover, DESOT is simple to implement and does not require sequences during training. Finally, we find that DESOT, like deep ensembles, outperform single models for out-of-distribution detection.
Zenseact Open Dataset: A large-scale and diverse multimodal dataset for autonomous driving
May 03, 2023



Existing datasets for autonomous driving (AD) often lack diversity and long-range capabilities, focusing instead on 360{\deg} perception and temporal reasoning. To address this gap, we introduce Zenseact Open Dataset (ZOD), a large-scale and diverse multimodal dataset collected over two years in various European countries, covering an area 9x that of existing datasets. ZOD boasts the highest range and resolution sensors among comparable datasets, coupled with detailed keyframe annotations for 2D and 3D objects (up to 245m), road instance/semantic segmentation, traffic sign recognition, and road classification. We believe that this unique combination will facilitate breakthroughs in long-range perception and multi-task learning. The dataset is composed of Frames, Sequences, and Drives, designed to encompass both data diversity and support for spatio-temporal learning, sensor fusion, localization, and mapping. Frames consist of 100k curated camera images with two seconds of other supporting sensor data, while the 1473 Sequences and 29 Drives include the entire sensor suite for 20 seconds and a few minutes, respectively. ZOD is the only large-scale AD dataset released under a permissive license, allowing for both research and commercial use. The dataset is accompanied by an extensive development kit. Data and more information are available online (https://zod.zenseact.com).
LidarCLIP or: How I Learned to Talk to Point Clouds
Dec 13, 2022



Research connecting text and images has recently seen several breakthroughs, with models like CLIP, DALL-E 2, and Stable Diffusion. However, the connection between text and other visual modalities, such as lidar data, has received less attention, prohibited by the lack of text-lidar datasets. In this work, we propose LidarCLIP, a mapping from automotive point clouds to a pre-existing CLIP embedding space. Using image-lidar pairs, we supervise a point cloud encoder with the image CLIP embeddings, effectively relating text and lidar data with the image domain as an intermediary. We show the effectiveness of LidarCLIP by demonstrating that lidar-based retrieval is generally on par with image-based retrieval, but with complementary strengths and weaknesses. By combining image and lidar features, we improve upon both single-modality methods and enable a targeted search for challenging detection scenarios under adverse sensor conditions. We also use LidarCLIP as a tool to investigate fundamental lidar capabilities through natural language. Finally, we leverage our compatibility with CLIP to explore a range of applications, such as point cloud captioning and lidar-to-image generation, without any additional training. We hope LidarCLIP can inspire future work to dive deeper into connections between text and point cloud understanding. Code and trained models available at https://github.com/atonderski/lidarclip.
Learning Future Object Prediction with a Spatiotemporal Detection Transformer
Apr 21, 2022
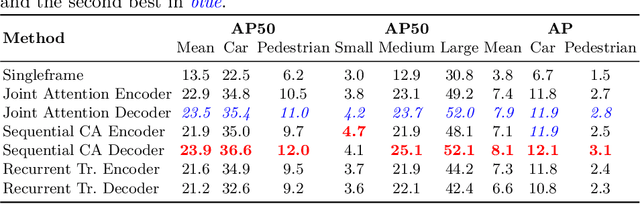
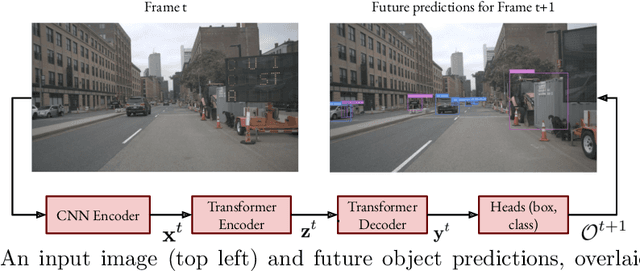
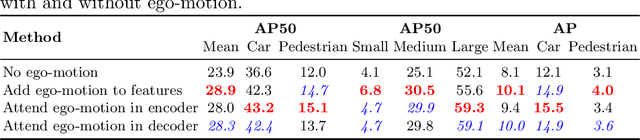
We explore future object prediction -- a challenging problem where all objects visible in a future video frame are to be predicted. We propose to tackle this problem end-to-end by training a detection transformer to directly output future objects. In order to make accurate predictions about the future, it is necessary to capture the dynamics in the scene, both of other objects and of the ego-camera. We extend existing detection transformers in two ways to capture the scene dynamics. First, we experiment with three different mechanisms that enable the model to spatiotemporally process multiple frames. Second, we feed ego-motion information to the model via cross-attention. We show that both of these cues substantially improve future object prediction performance. Our final approach learns to capture the dynamics and make predictions on par with an oracle for 100 ms prediction horizons, and outperform baselines for longer prediction horizons.