 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA unified FLAIR hyperintensity segmentation model for various CNS tumor types and acquisition time points
Dec 19, 2025T2-weighted fluid-attenuated inversion recovery (FLAIR) magnetic resonance imaging (MRI) scans are important for diagnosis, treatment planning and monitoring of brain tumors. Depending on the brain tumor type, the FLAIR hyperintensity volume is an important measure to asses the tumor volume or surrounding edema, and an automatic segmentation of this would be useful in the clinic. In this study, around 5000 FLAIR images of various tumors types and acquisition time points from different centers were used to train a unified FLAIR hyperintensity segmentation model using an Attention U-Net architecture. The performance was compared against dataset specific models, and was validated on different tumor types, acquisition time points and against BraTS. The unified model achieved an average Dice score of 88.65\% for pre-operative meningiomas, 80.08% for pre-operative metastasis, 90.92% for pre-operative and 84.60% for post-operative gliomas from BraTS, and 84.47% for pre-operative and 61.27\% for post-operative lower grade gliomas. In addition, the results showed that the unified model achieved comparable segmentation performance to the dataset specific models on their respective datasets, and enables generalization across tumor types and acquisition time points, which facilitates the deployment in a clinical setting. The model is integrated into Raidionics, an open-source software for CNS tumor analysis.
Automatic and standardized surgical reporting for central nervous system tumors
Aug 12, 2025Magnetic resonance (MR) imaging is essential for evaluating central nervous system (CNS) tumors, guiding surgical planning, treatment decisions, and assessing postoperative outcomes and complication risks. While recent work has advanced automated tumor segmentation and report generation, most efforts have focused on preoperative data, with limited attention to postoperative imaging analysis. This study introduces a comprehensive pipeline for standardized postsurtical reporting in CNS tumors. Using the Attention U-Net architecture, segmentation models were trained for the preoperative (non-enhancing) tumor core, postoperative contrast-enhancing residual tumor, and resection cavity. Additionally, MR sequence classification and tumor type identification for contrast-enhancing lesions were explored using the DenseNet architecture. The models were integrated into a reporting pipeline, following the RANO 2.0 guidelines. Training was conducted on multicentric datasets comprising 2000 to 7000 patients, using a 5-fold cross-validation. Evaluation included patient-, voxel-, and object-wise metrics, with benchmarking against the latest BraTS challenge results. The segmentation models achieved average voxel-wise Dice scores of 87%, 66%, 70%, and 77% for the tumor core, non-enhancing tumor core, contrast-enhancing residual tumor, and resection cavity, respectively. Classification models reached 99.5% balanced accuracy in MR sequence classification and 80% in tumor type classification. The pipeline presented in this study enables robust, automated segmentation, MR sequence classification, and standardized report generation aligned with RANO 2.0 guidelines, enhancing postoperative evaluation and clinical decision-making. The proposed models and methods were integrated into Raidionics, open-source software platform for CNS tumor analysis, now including a dedicated module for postsurgical analysis.
AeroPath: An airway segmentation benchmark dataset with challenging pathology
Nov 02, 2023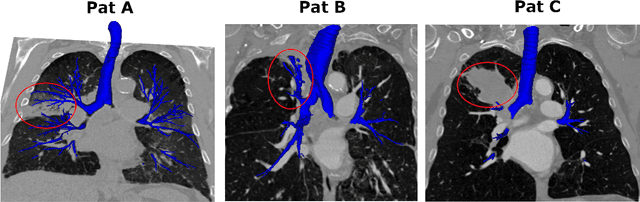

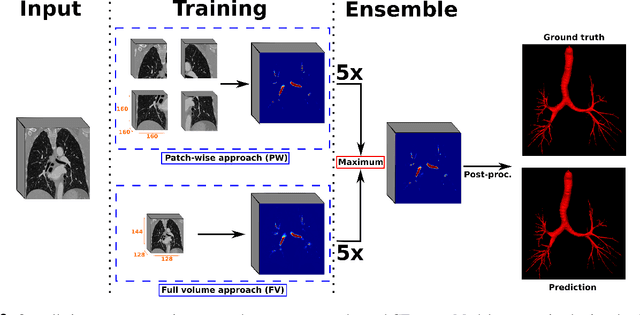
To improve the prognosis of patients suffering from pulmonary diseases, such as lung cancer, early diagnosis and treatment are crucial. The analysis of CT images is invaluable for diagnosis, whereas high quality segmentation of the airway tree are required for intervention planning and live guidance during bronchoscopy. Recently, the Multi-domain Airway Tree Modeling (ATM'22) challenge released a large dataset, both enabling training of deep-learning based models and bringing substantial improvement of the state-of-the-art for the airway segmentation task. However, the ATM'22 dataset includes few patients with severe pathologies affecting the airway tree anatomy. In this study, we introduce a new public benchmark dataset (AeroPath), consisting of 27 CT images from patients with pathologies ranging from emphysema to large tumors, with corresponding trachea and bronchi annotations. Second, we present a multiscale fusion design for automatic airway segmentation. Models were trained on the ATM'22 dataset, tested on the AeroPath dataset, and further evaluated against competitive open-source methods. The same performance metrics as used in the ATM'22 challenge were used to benchmark the different considered approaches. Lastly, an open web application is developed, to easily test the proposed model on new data. The results demonstrated that our proposed architecture predicted topologically correct segmentations for all the patients included in the AeroPath dataset. The proposed method is robust and able to handle various anomalies, down to at least the fifth airway generation. In addition, the AeroPath dataset, featuring patients with challenging pathologies, will contribute to development of new state-of-the-art methods. The AeroPath dataset and the web application are made openly available.
Segmentation of glioblastomas in early post-operative multi-modal MRI with deep neural networks
Apr 18, 2023Extent of resection after surgery is one of the main prognostic factors for patients diagnosed with glioblastoma. To achieve this, accurate segmentation and classification of residual tumor from post-operative MR images is essential. The current standard method for estimating it is subject to high inter- and intra-rater variability, and an automated method for segmentation of residual tumor in early post-operative MRI could lead to a more accurate estimation of extent of resection. In this study, two state-of-the-art neural network architectures for pre-operative segmentation were trained for the task. The models were extensively validated on a multicenter dataset with nearly 1000 patients, from 12 hospitals in Europe and the United States. The best performance achieved was a 61\% Dice score, and the best classification performance was about 80\% balanced accuracy, with a demonstrated ability to generalize across hospitals. In addition, the segmentation performance of the best models was on par with human expert raters. The predicted segmentations can be used to accurately classify the patients into those with residual tumor, and those with gross total resection.
Train smarter, not harder: learning deep abdominal CT registration on scarce data
Nov 30, 2022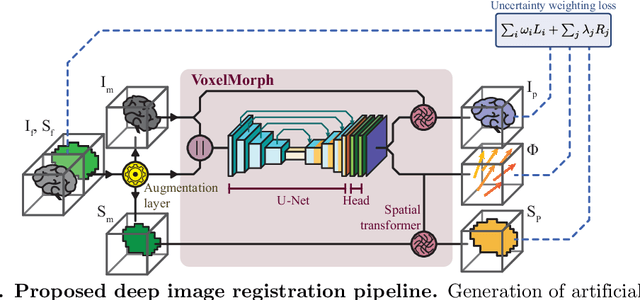
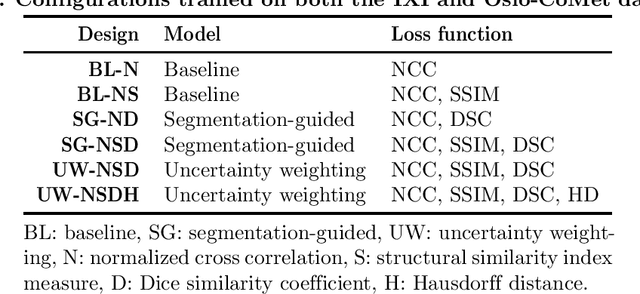
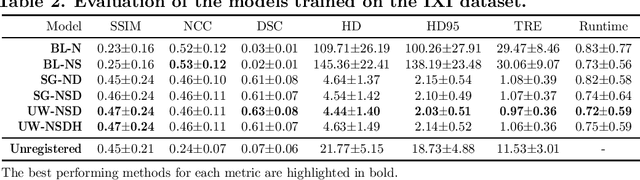
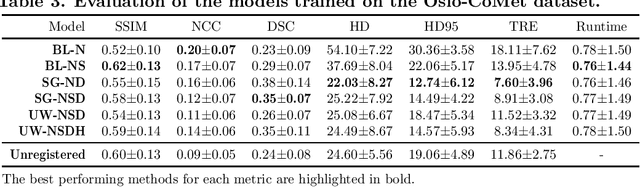
Purpose: This study aims to explore training strategies to improve convolutional neural network-based image-to-image registration for abdominal imaging. Methods: Different training strategies, loss functions, and transfer learning schemes were considered. Furthermore, an augmentation layer which generates artificial training image pairs on-the-fly was proposed, in addition to a loss layer that enables dynamic loss weighting. Results: Guiding registration using segmentations in the training step proved beneficial for deep-learning-based image registration. Finetuning the pretrained model from the brain MRI dataset to the abdominal CT dataset further improved performance on the latter application, removing the need for a large dataset to yield satisfactory performance. Dynamic loss weighting also marginally improved performance, all without impacting inference runtime. Conclusion: Using simple concepts, we improved the performance of a commonly used deep image registration architecture, VoxelMorph. In future work, our framework, DDMR, should be validated on different datasets to further assess its value.
Hybrid guiding: A multi-resolution refinement approach for semantic segmentation of gigapixel histopathological images
Dec 07, 2021
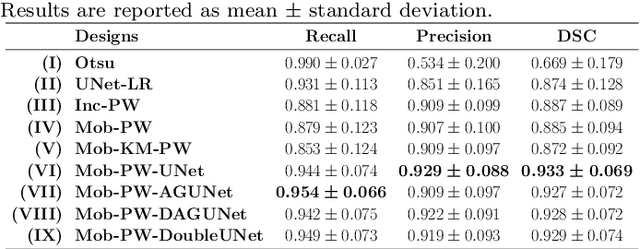
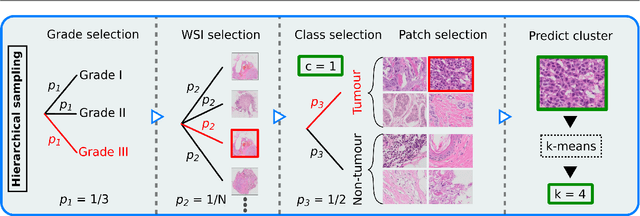
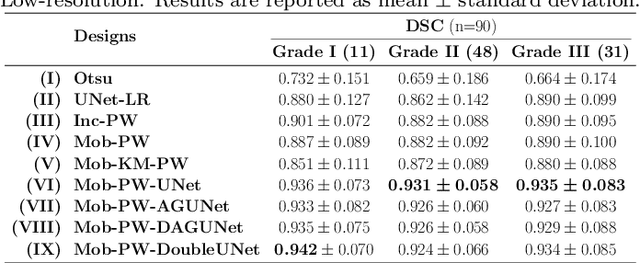
Histopathological cancer diagnostics has become more complex, and the increasing number of biopsies is a challenge for most pathology laboratories. Thus, development of automatic methods for evaluation of histopathological cancer sections would be of value. In this study, we used 624 whole slide images (WSIs) of breast cancer from a Norwegian cohort. We propose a cascaded convolutional neural network design, called H2G-Net, for semantic segmentation of gigapixel histopathological images. The design involves a detection stage using a patch-wise method, and a refinement stage using a convolutional autoencoder. To validate the design, we conducted an ablation study to assess the impact of selected components in the pipeline on tumour segmentation. Guiding segmentation, using hierarchical sampling and deep heatmap refinement, proved to be beneficial when segmenting the histopathological images. We found a significant improvement when using a refinement network for postprocessing the generated tumour segmentation heatmaps. The overall best design achieved a Dice score of 0.933 on an independent test set of 90 WSIs. The design outperformed single-resolution approaches, such as cluster-guided, patch-wise high-resolution classification using MobileNetV2 (0.872) and a low-resolution U-Net (0.874). In addition, segmentation on a representative x400 WSI took ~58 seconds, using only the CPU. The findings demonstrate the potential of utilizing a refinement network to improve patch-wise predictions. The solution is efficient and does not require overlapping patch inference or ensembling. Furthermore, we showed that deep neural networks can be trained using a random sampling scheme that balances on multiple different labels simultaneously, without the need of storing patches on disk. Future work should involve more efficient patch generation and sampling, as well as improved clustering.
Mediastinal lymph nodes segmentation using 3D convolutional neural network ensembles and anatomical priors guiding
Feb 11, 2021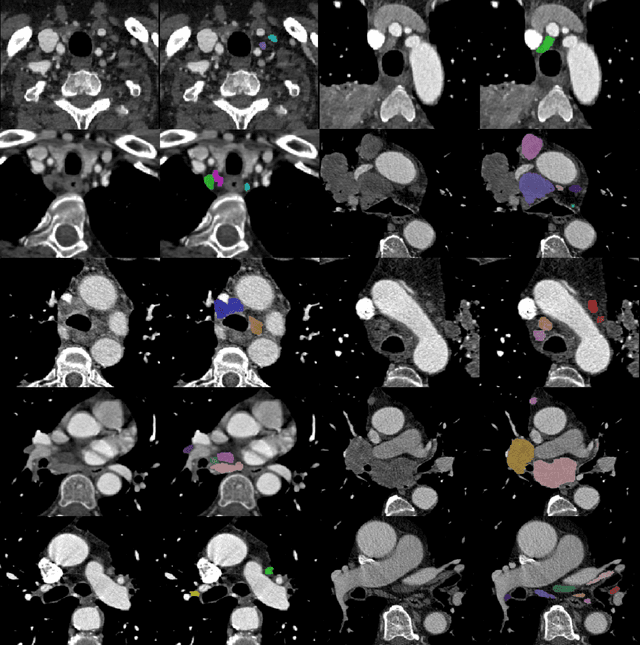
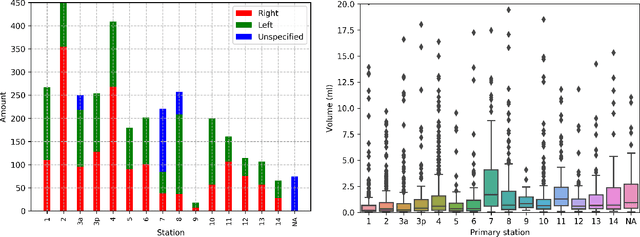

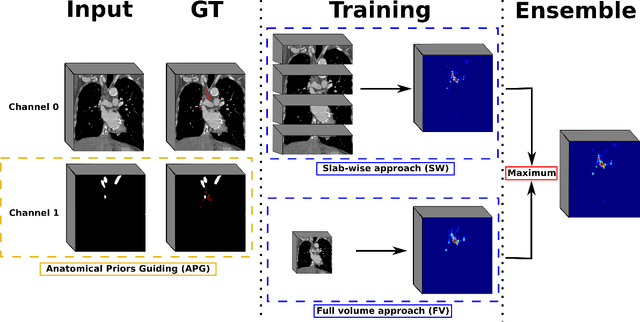
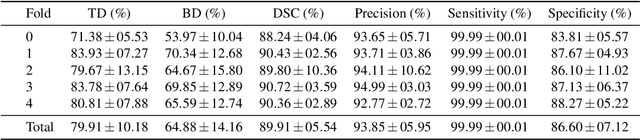
As lung cancer evolves, the presence of enlarged and potentially malignant lymph nodes must be assessed to properly estimate disease progression and select the best treatment strategy. Following the clinical guidelines, estimation of short-axis diameter and mediastinum station are paramount for correct diagnosis. A method for accurate and automatic segmentation is hence decisive for quantitatively describing lymph nodes. In this study, the use of 3D convolutional neural networks, either through slab-wise schemes or the leveraging of downsampled entire volumes, is investigated. Furthermore, the potential impact from simple ensemble strategies is considered. As lymph nodes have similar attenuation values to nearby anatomical structures, we suggest using the knowledge of other organs as prior information to guide the segmentation task. To assess the segmentation and instance detection performances, a 5-fold cross-validation strategy was followed over a dataset of 120 contrast-enhanced CT volumes. For the 1178 lymph nodes with a short-axis diameter $\geq10$ mm, our best performing approach reached a patient-wise recall of 92%, a false positive per patient ratio of 5, and a segmentation overlap of 80.5%. The method performs similarly well across all stations. Fusing a slab-wise and a full volume approach within an ensemble scheme generated the best performances. The anatomical priors guiding strategy is promising, yet a larger set than four organs appears needed to generate an optimal benefit. A larger dataset is also mandatory, given the wide range of expressions a lymph node can exhibit (i.e., shape, location, and attenuation), and contrast uptake variations.
Meningioma segmentation in T1-weighted MRI leveraging global context and attention mechanisms
Jan 19, 2021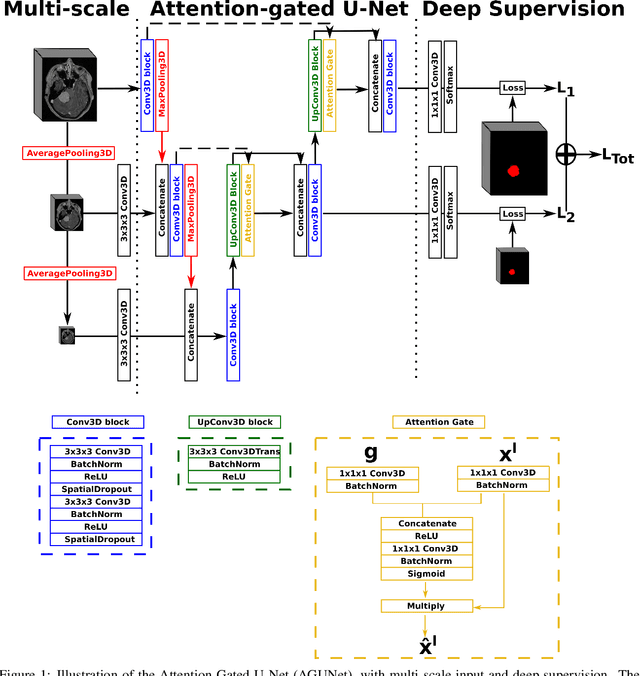
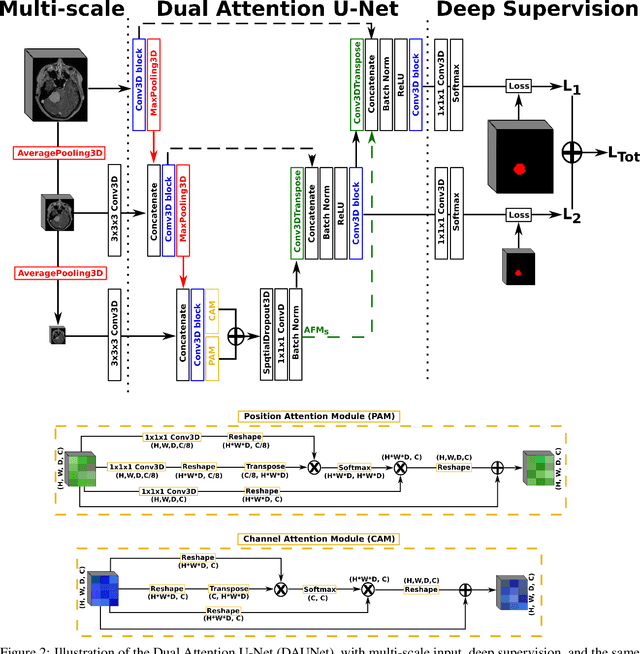
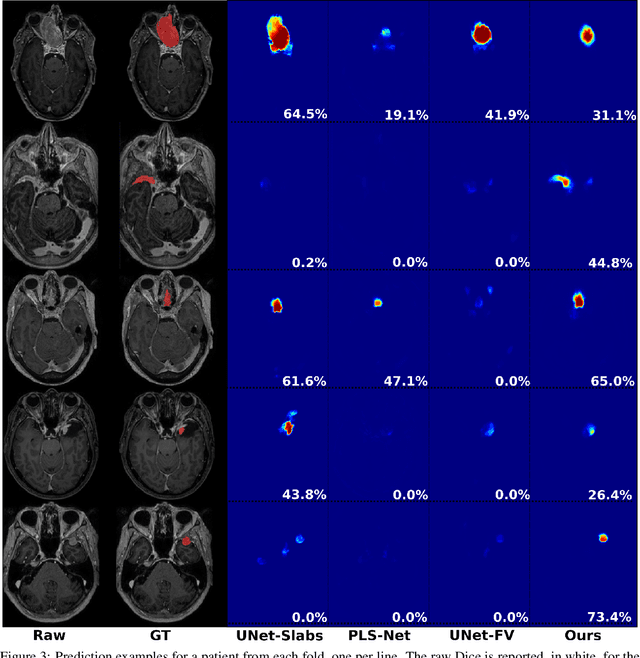

Meningiomas are the most common type of primary brain tumor, accounting for approximately 30% of all brain tumors. A substantial number of these tumors are never surgically removed but rather monitored over time. Automatic and precise meningioma segmentation is therefore beneficial to enable reliable growth estimation and patient-specific treatment planning. In this study, we propose the inclusion of attention mechanisms over a U-Net architecture: (i) Attention-gated U-Net (AGUNet) and (ii) Dual Attention U-Net (DAUNet), using a 3D MRI volume as input. Attention has the potential to leverage the global context and identify features' relationships across the entire volume. To limit spatial resolution degradation and loss of detail inherent to encoder-decoder architectures, we studied the impact of multi-scale input and deep supervision components. The proposed architectures are trainable end-to-end and each concept can be seamlessly disabled for ablation studies. The validation studies were performed using a 5-fold cross validation over 600 T1-weighted MRI volumes from St. Olavs University Hospital, Trondheim, Norway. For the best performing architecture, an average Dice score of 81.6% was reached for an F1-score of 95.6%. With an almost perfect precision of 98%, meningiomas smaller than 3ml were occasionally missed hence reaching an overall recall of 93%. Leveraging global context from a 3D MRI volume provided the best performances, even if the native volume resolution could not be processed directly. Overall, near-perfect detection was achieved for meningiomas larger than 3ml which is relevant for clinical use. In the future, the use of multi-scale designs and refinement networks should be further investigated to improve the performance. A larger number of cases with meningiomas below 3ml might also be needed to improve the performance for the smallest tumors.
Fast meningioma segmentation in T1-weighted MRI volumes using a lightweight 3D deep learning architecture
Oct 14, 2020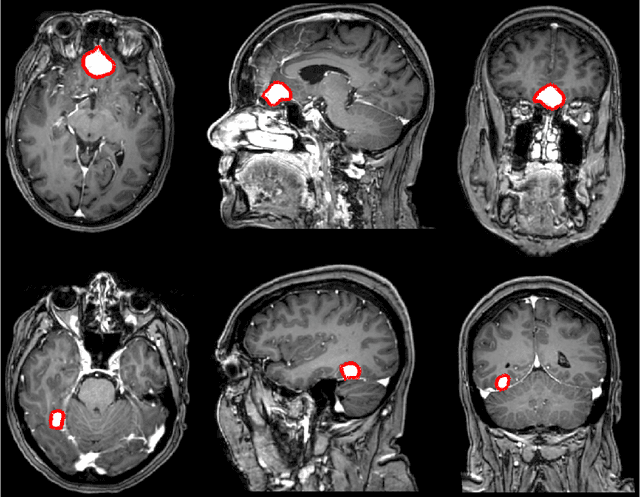
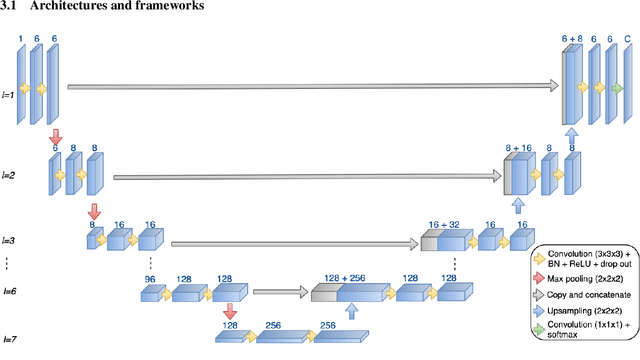
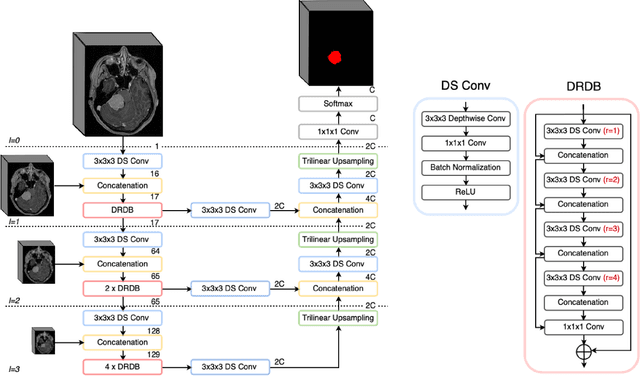
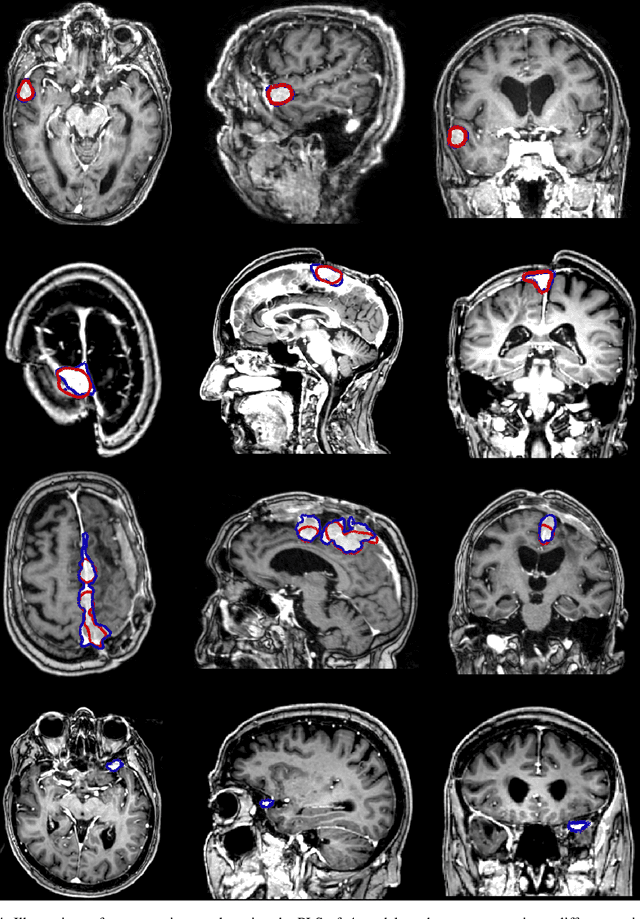
Automatic and consistent meningioma segmentation in T1-weighted MRI volumes and corresponding volumetric assessment is of use for diagnosis, treatment planning, and tumor growth evaluation. In this paper, we optimized the segmentation and processing speed performances using a large number of both surgically treated meningiomas and untreated meningiomas followed at the outpatient clinic. We studied two different 3D neural network architectures: (i) a simple encoder-decoder similar to a 3D U-Net, and (ii) a lightweight multi-scale architecture (PLS-Net). In addition, we studied the impact of different training schemes. For the validation studies, we used 698 T1-weighted MR volumes from St. Olav University Hospital, Trondheim, Norway. The models were evaluated in terms of detection accuracy, segmentation accuracy and training/inference speed. While both architectures reached a similar Dice score of 70% on average, the PLS-Net was more accurate with an F1-score of up to 88%. The highest accuracy was achieved for the largest meningiomas. Speed-wise, the PLS-Net architecture tended to converge in about 50 hours while 130 hours were necessary for U-Net. Inference with PLS-Net takes less than a second on GPU and about 15 seconds on CPU. Overall, with the use of mixed precision training, it was possible to train competitive segmentation models in a relatively short amount of time using the lightweight PLS-Net architecture. In the future, the focus should be brought toward the segmentation of small meningiomas (less than 2ml) to improve clinical relevance for automatic and early diagnosis as well as speed of growth estimates.