 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Deep Learning-Based Monocular Spacecraft Pose Estimation: Current State, Limitations and Prospects
May 17, 2023



Estimating the pose of an uncooperative spacecraft is an important computer vision problem for enabling the deployment of automatic vision-based systems in orbit, with applications ranging from on-orbit servicing to space debris removal. Following the general trend in computer vision, more and more works have been focusing on leveraging Deep Learning (DL) methods to address this problem. However and despite promising research-stage results, major challenges preventing the use of such methods in real-life missions still stand in the way. In particular, the deployment of such computation-intensive algorithms is still under-investigated, while the performance drop when training on synthetic and testing on real images remains to mitigate. The primary goal of this survey is to describe the current DL-based methods for spacecraft pose estimation in a comprehensive manner. The secondary goal is to help define the limitations towards the effective deployment of DL-based spacecraft pose estimation solutions for reliable autonomous vision-based applications. To this end, the survey first summarises the existing algorithms according to two approaches: hybrid modular pipelines and direct end-to-end regression methods. A comparison of algorithms is presented not only in terms of pose accuracy but also with a focus on network architectures and models' sizes keeping potential deployment in mind. Then, current monocular spacecraft pose estimation datasets used to train and test these methods are discussed. The data generation methods: simulators and testbeds, the domain gap and the performance drop between synthetically generated and lab/space collected images and the potential solutions are also discussed. Finally, the paper presents open research questions and future directions in the field, drawing parallels with other computer vision applications.
Lessons from a Space Lab -- An Image Acquisition Perspective
Aug 18, 2022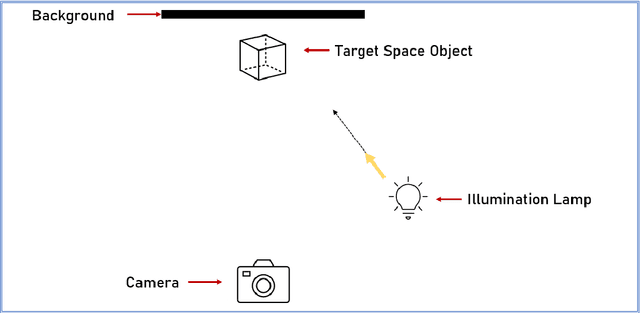
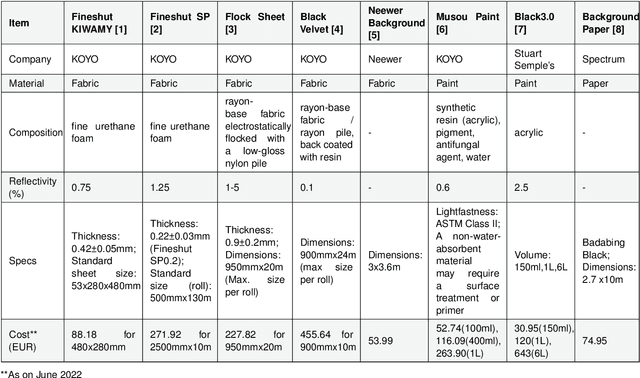
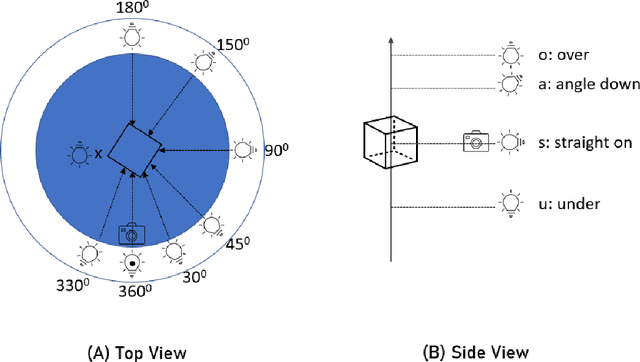
The use of Deep Learning (DL) algorithms has improved the performance of vision-based space applications in recent years. However, generating large amounts of annotated data for training these DL algorithms has proven challenging. While synthetically generated images can be used, the DL models trained on synthetic data are often susceptible to performance degradation, when tested in real-world environments. In this context, the Interdisciplinary Center of Security, Reliability and Trust (SnT) at the University of Luxembourg has developed the 'SnT Zero-G Lab', for training and validating vision-based space algorithms in conditions emulating real-world space environments. An important aspect of the SnT Zero-G Lab development was the equipment selection. From the lessons learned during the lab development, this article presents a systematic approach combining market survey and experimental analyses for equipment selection. In particular, the article focus on the image acquisition equipment in a space lab: background materials, cameras and illumination lamps. The results from the experiment analyses show that the market survey complimented by experimental analyses is required for effective equipment selection in a space lab development project.
Leveraging Equivariant Features for Absolute Pose Regression
Apr 05, 2022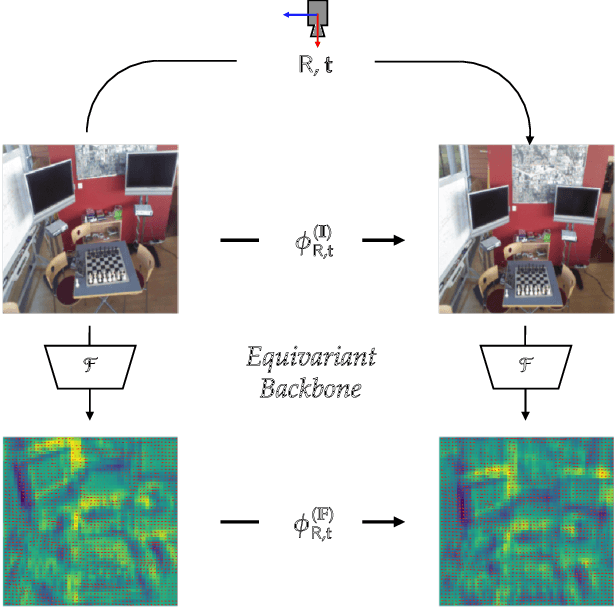
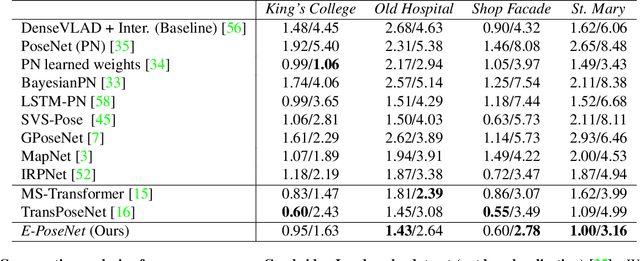
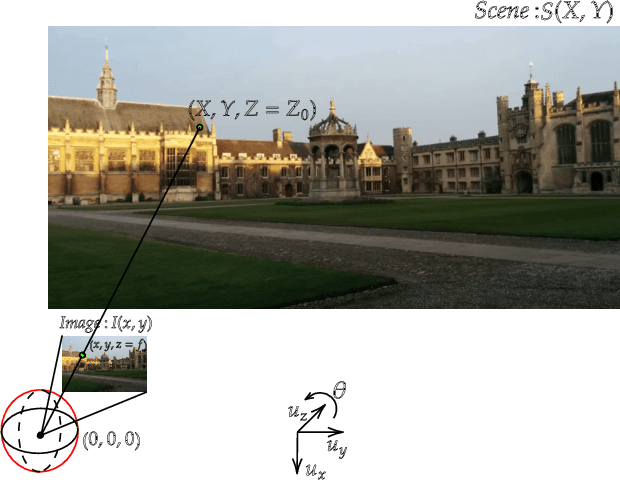
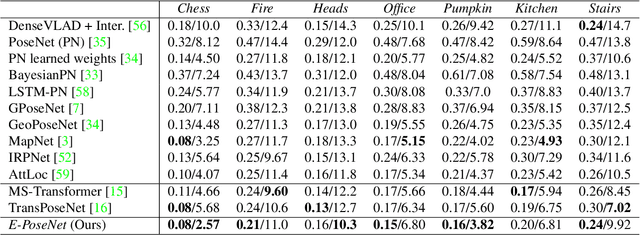
While end-to-end approaches have achieved state-of-the-art performance in many perception tasks, they are not yet able to compete with 3D geometry-based methods in pose estimation. Moreover, absolute pose regression has been shown to be more related to image retrieval. As a result, we hypothesize that the statistical features learned by classical Convolutional Neural Networks do not carry enough geometric information to reliably solve this inherently geometric task. In this paper, we demonstrate how a translation and rotation equivariant Convolutional Neural Network directly induces representations of camera motions into the feature space. We then show that this geometric property allows for implicitly augmenting the training data under a whole group of image plane-preserving transformations. Therefore, we argue that directly learning equivariant features is preferable than learning data-intensive intermediate representations. Comprehensive experimental validation demonstrates that our lightweight model outperforms existing ones on standard datasets.
LSPnet: A 2D Localization-oriented Spacecraft Pose Estimation Neural Network
Apr 19, 2021
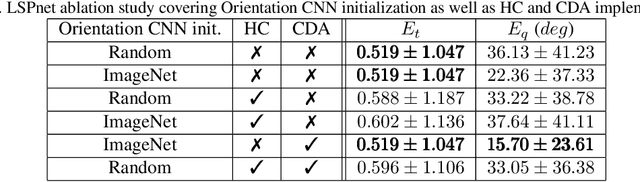
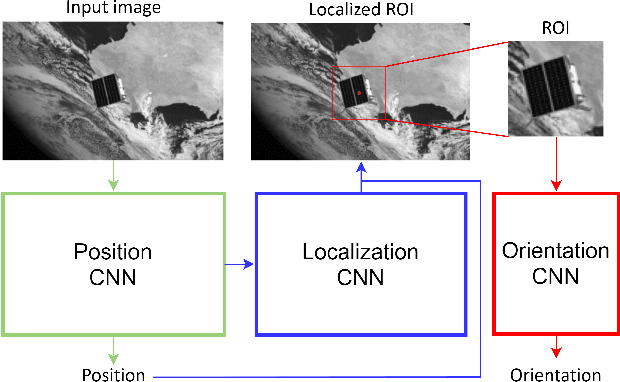
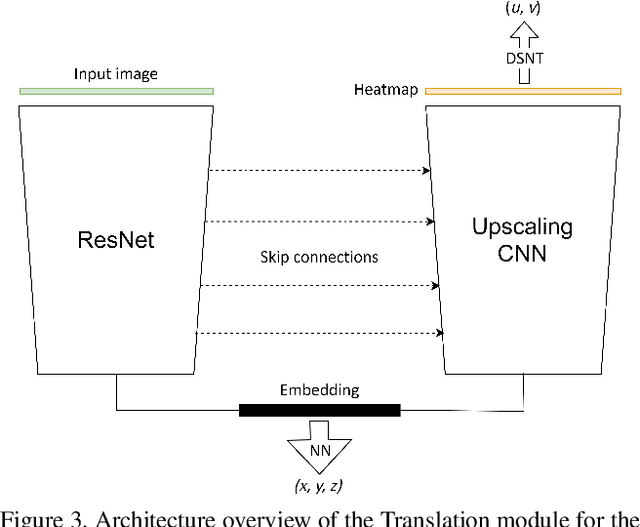
Being capable of estimating the pose of uncooperative objects in space has been proposed as a key asset for enabling safe close-proximity operations such as space rendezvous, in-orbit servicing and active debris removal. Usual approaches for pose estimation involve classical computer vision-based solutions or the application of Deep Learning (DL) techniques. This work explores a novel DL-based methodology, using Convolutional Neural Networks (CNNs), for estimating the pose of uncooperative spacecrafts. Contrary to other approaches, the proposed CNN directly regresses poses without needing any prior 3D information. Moreover, bounding boxes of the spacecraft in the image are predicted in a simple, yet efficient manner. The performed experiments show how this work competes with the state-of-the-art in uncooperative spacecraft pose estimation, including works which require 3D information as well as works which predict bounding boxes through sophisticated CNNs.