 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Equivariant Features for Absolute Pose Regression
Apr 05, 2022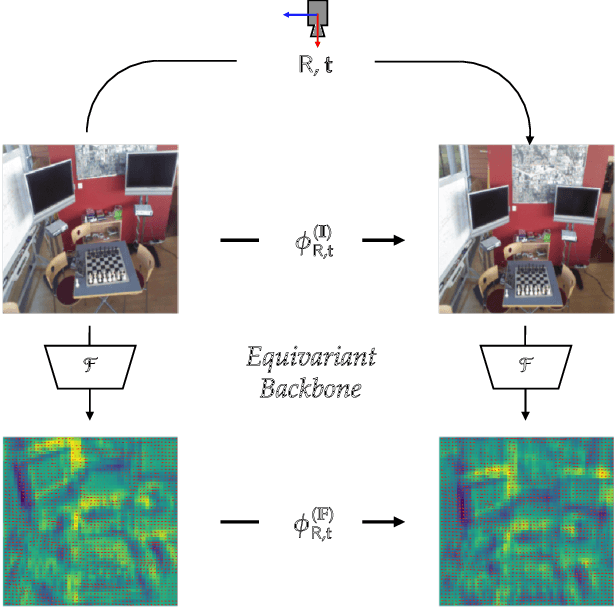
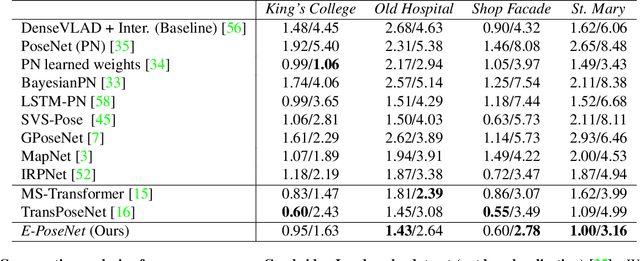
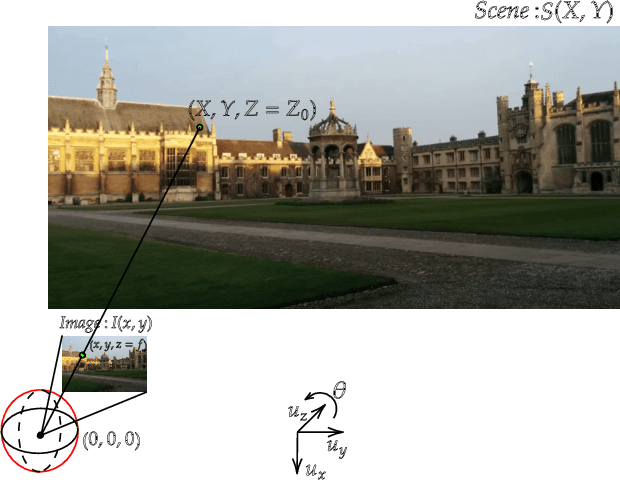
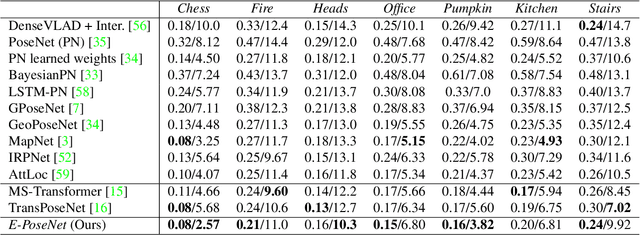
While end-to-end approaches have achieved state-of-the-art performance in many perception tasks, they are not yet able to compete with 3D geometry-based methods in pose estimation. Moreover, absolute pose regression has been shown to be more related to image retrieval. As a result, we hypothesize that the statistical features learned by classical Convolutional Neural Networks do not carry enough geometric information to reliably solve this inherently geometric task. In this paper, we demonstrate how a translation and rotation equivariant Convolutional Neural Network directly induces representations of camera motions into the feature space. We then show that this geometric property allows for implicitly augmenting the training data under a whole group of image plane-preserving transformations. Therefore, we argue that directly learning equivariant features is preferable than learning data-intensive intermediate representations. Comprehensive experimental validation demonstrates that our lightweight model outperforms existing ones on standard datasets.
LSPnet: A 2D Localization-oriented Spacecraft Pose Estimation Neural Network
Apr 19, 2021
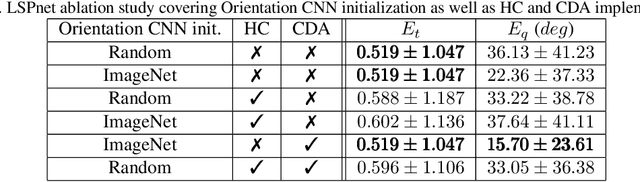
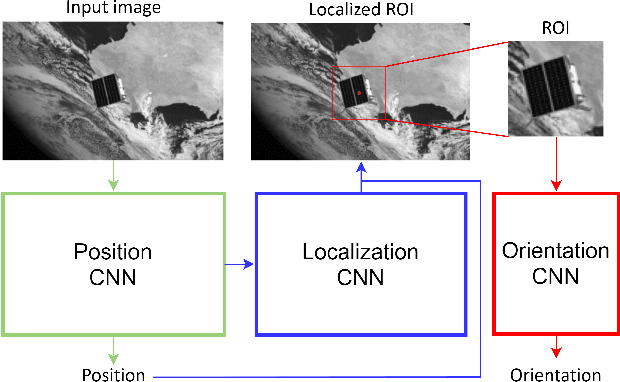
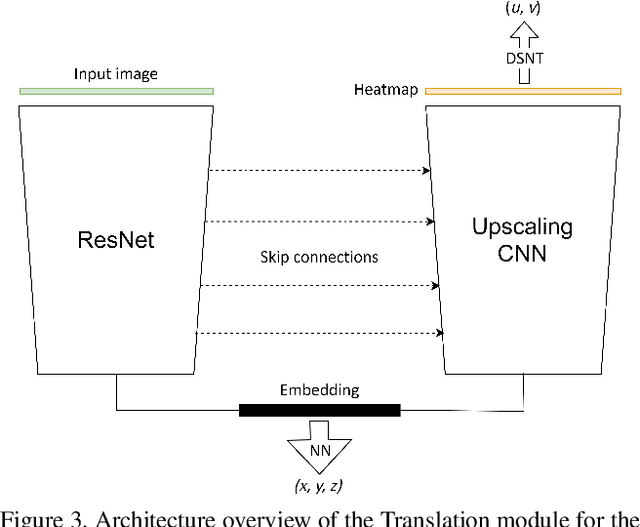
Being capable of estimating the pose of uncooperative objects in space has been proposed as a key asset for enabling safe close-proximity operations such as space rendezvous, in-orbit servicing and active debris removal. Usual approaches for pose estimation involve classical computer vision-based solutions or the application of Deep Learning (DL) techniques. This work explores a novel DL-based methodology, using Convolutional Neural Networks (CNNs), for estimating the pose of uncooperative spacecrafts. Contrary to other approaches, the proposed CNN directly regresses poses without needing any prior 3D information. Moreover, bounding boxes of the spacecraft in the image are predicted in a simple, yet efficient manner. The performed experiments show how this work competes with the state-of-the-art in uncooperative spacecraft pose estimation, including works which require 3D information as well as works which predict bounding boxes through sophisticated CNNs.
SPARK: SPAcecraft Recognition leveraging Knowledge of Space Environment
Apr 14, 2021
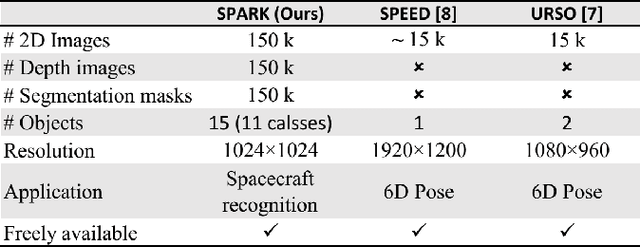
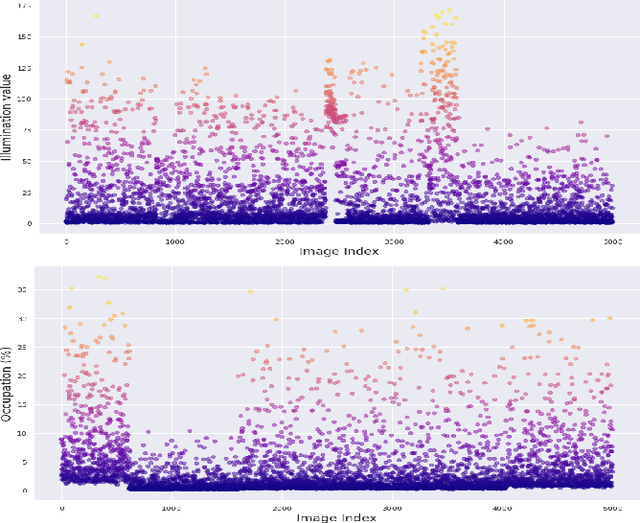
This paper proposes the SPARK dataset as a new unique space object multi-modal image dataset. Image-based object recognition is an important component of Space Situational Awareness, especially for applications such as on-orbit servicing, active debris removal, and satellite formation. However, the lack of sufficient annotated space data has limited research efforts in developing data-driven spacecraft recognition approaches. The SPARK dataset has been generated under a realistic space simulation environment, with a large diversity in sensing conditions for different orbital scenarios. It provides about 150k images per modality, RGB and depth, and 11 classes for spacecrafts and debris. This dataset offers an opportunity to benchmark and further develop object recognition, classification and detection algorithms, as well as multi-modal RGB-Depth approaches under space sensing conditions. Preliminary experimental evaluation validates the relevance of the data, and highlights interesting challenging scenarios specific to the space environment.
Towards Generalization of 3D Human Pose Estimation In The Wild
Apr 21, 2020

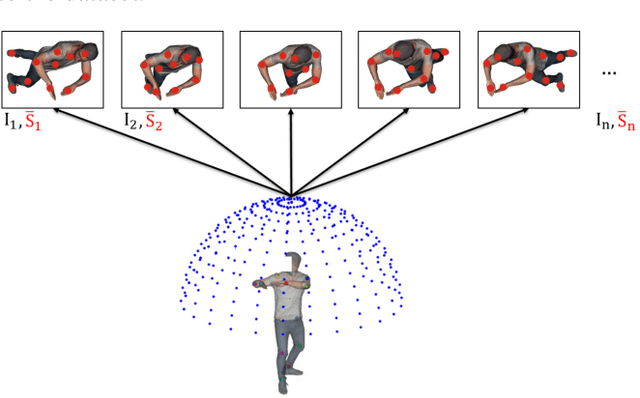

In this paper, we propose 3DBodyTex.Pose, a dataset that addresses the task of 3D human pose estimation in-the-wild. Generalization to in-the-wild images remains limited due to the lack of adequate datasets. Existent ones are usually collected in indoor controlled environments where motion capture systems are used to obtain the 3D ground-truth annotations of humans. 3DBodyTex.Pose offers high quality and rich data containing 405 different real subjects in various clothing and poses, and 81k image samples with ground-truth 2D and 3D pose annotations. These images are generated from 200 viewpoints among which 70 challenging extreme viewpoints. This data was created starting from high resolution textured 3D body scans and by incorporating various realistic backgrounds. Retraining a state-of-the-art 3D pose estimation approach using data augmented with 3DBodyTex.Pose showed promising improvement in the overall performance, and a sensible decrease in the per joint position error when testing on challenging viewpoints. The 3DBodyTex.Pose is expected to offer the research community with new possibilities for generalizing 3D pose estimation from monocular in-the-wild images.