 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARCO: Multi-Agent Real-time Chat Orchestration
Oct 29, 2024Large language model advancements have enabled the development of multi-agent frameworks to tackle complex, real-world problems such as to automate tasks that require interactions with diverse tools, reasoning, and human collaboration. We present MARCO, a Multi-Agent Real-time Chat Orchestration framework for automating tasks using LLMs. MARCO addresses key challenges in utilizing LLMs for complex, multi-step task execution. It incorporates robust guardrails to steer LLM behavior, validate outputs, and recover from errors that stem from inconsistent output formatting, function and parameter hallucination, and lack of domain knowledge. Through extensive experiments we demonstrate MARCO's superior performance with 94.48% and 92.74% accuracy on task execution for Digital Restaurant Service Platform conversations and Retail conversations datasets respectively along with 44.91% improved latency and 33.71% cost reduction. We also report effects of guardrails in performance gain along with comparisons of various LLM models, both open-source and proprietary. The modular and generic design of MARCO allows it to be adapted for automating tasks across domains and to execute complex usecases through multi-turn interactions.
MARS: Multilingual Aspect-centric Review Summarisation
Oct 13, 2024Summarizing customer feedback to provide actionable insights for products/services at scale is an important problem for businesses across industries. Lately, the review volumes are increasing across regions and languages, therefore the challenge of aggregating and understanding customer sentiment across multiple languages becomes increasingly vital. In this paper, we propose a novel framework involving a two-step paradigm \textit{Extract-then-Summarise}, namely MARS to revolutionise traditions and address the domain agnostic aspect-level multilingual review summarisation. Extensive automatic and human evaluation shows that our approach brings substantial improvements over abstractive baselines and efficiency to real-time systems.
InsightNet: Structured Insight Mining from Customer Feedback
May 12, 2024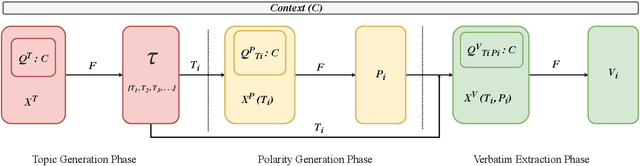
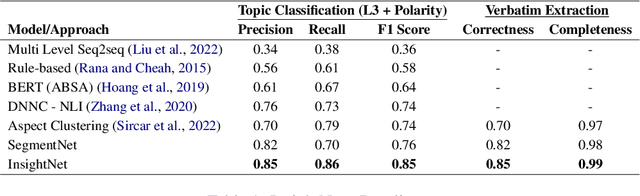
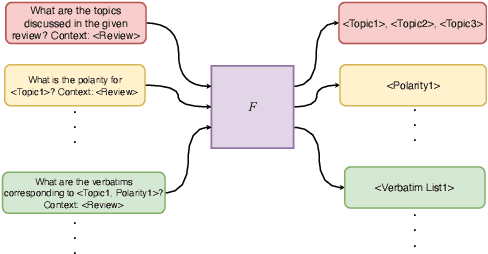
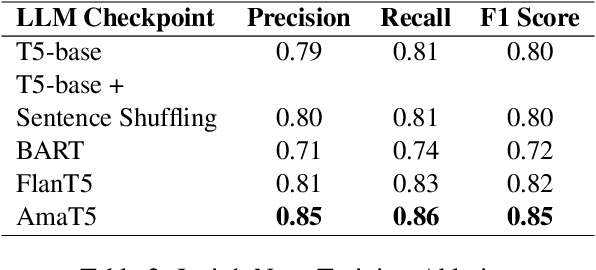
We propose InsightNet, a novel approach for the automated extraction of structured insights from customer reviews. Our end-to-end machine learning framework is designed to overcome the limitations of current solutions, including the absence of structure for identified topics, non-standard aspect names, and lack of abundant training data. The proposed solution builds a semi-supervised multi-level taxonomy from raw reviews, a semantic similarity heuristic approach to generate labelled data and employs a multi-task insight extraction architecture by fine-tuning an LLM. InsightNet identifies granular actionable topics with customer sentiments and verbatim for each topic. Evaluations on real-world customer review data show that InsightNet performs better than existing solutions in terms of structure, hierarchy and completeness. We empirically demonstrate that InsightNet outperforms the current state-of-the-art methods in multi-label topic classification, achieving an F1 score of 0.85, which is an improvement of 11% F1-score over the previous best results. Additionally, InsightNet generalises well for unseen aspects and suggests new topics to be added to the taxonomy.
NER-MQMRC: Formulating Named Entity Recognition as Multi Question Machine Reading Comprehension
May 12, 2022
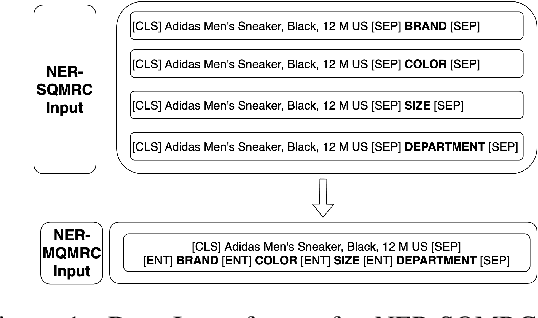
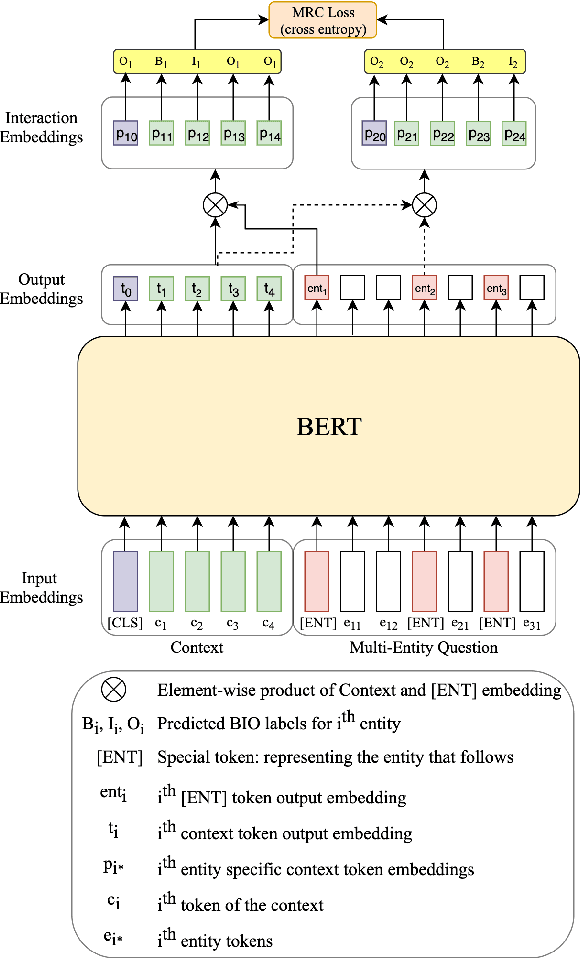
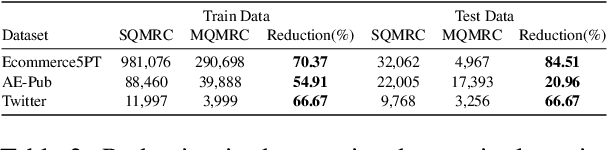
NER has been traditionally formulated as a sequence labeling task. However, there has been recent trend in posing NER as a machine reading comprehension task (Wang et al., 2020; Mengge et al., 2020), where entity name (or other information) is considered as a question, text as the context and entity value in text as answer snippet. These works consider MRC based on a single question (entity) at a time. We propose posing NER as a multi-question MRC task, where multiple questions (one question per entity) are considered at the same time for a single text. We propose a novel BERT-based multi-question MRC (NER-MQMRC) architecture for this formulation. NER-MQMRC architecture considers all entities as input to BERT for learning token embeddings with self-attention and leverages BERT-based entity representation for further improving these token embeddings for NER task. Evaluation on three NER datasets show that our proposed architecture leads to average 2.5 times faster training and 2.3 times faster inference as compared to NER-SQMRC framework based models by considering all entities together in a single pass. Further, we show that our model performance does not degrade compared to single-question based MRC (NER-SQMRC) (Devlin et al., 2019) leading to F1 gain of +0.41%, +0.32% and +0.27% for AE-Pub, Ecommerce5PT and Twitter datasets respectively. We propose this architecture primarily to solve large scale e-commerce attribute (or entity) extraction from unstructured text of a magnitude of 50k+ attributes to be extracted on a scalable production environment with high performance and optimised training and inference runtimes.
AMUSED: A Multi-Stream Vector Representation Method for Use in Natural Dialogue
Dec 04, 2019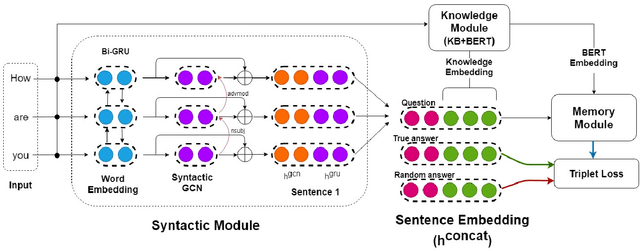

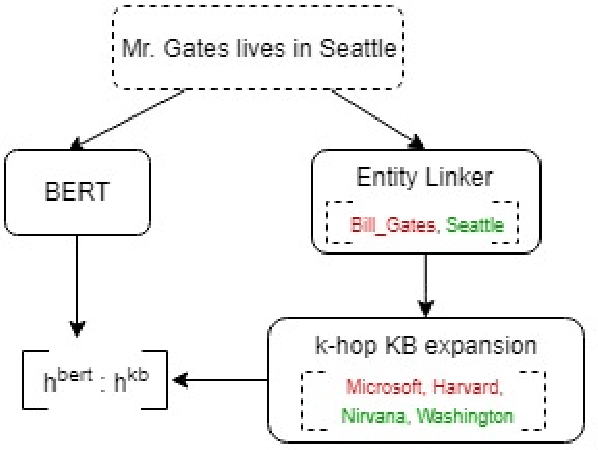
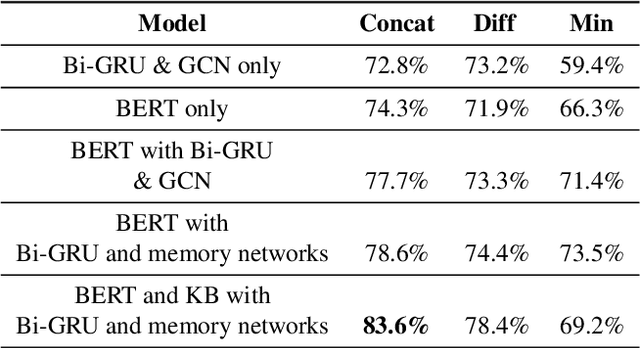
The problem of building a coherent and non-monotonous conversational agent with proper discourse and coverage is still an area of open research. Current architectures only take care of semantic and contextual information for a given query and fail to completely account for syntactic and external knowledge which are crucial for generating responses in a chit-chat system. To overcome this problem, we propose an end to end multi-stream deep learning architecture which learns unified embeddings for query-response pairs by leveraging contextual information from memory networks and syntactic information by incorporating Graph Convolution Networks (GCN) over their dependency parse. A stream of this network also utilizes transfer learning by pre-training a bidirectional transformer to extract semantic representation for each input sentence and incorporates external knowledge through the the neighborhood of the entities from a Knowledge Base (KB). We benchmark these embeddings on next sentence prediction task and significantly improve upon the existing techniques. Furthermore, we use AMUSED to represent query and responses along with its context to develop a retrieval based conversational agent which has been validated by expert linguists to have comprehensive engagement with humans.
Learning Discriminative features using Center Loss and Reconstruction as Regularizer for Speech Emotion Recognition
Jun 19, 2019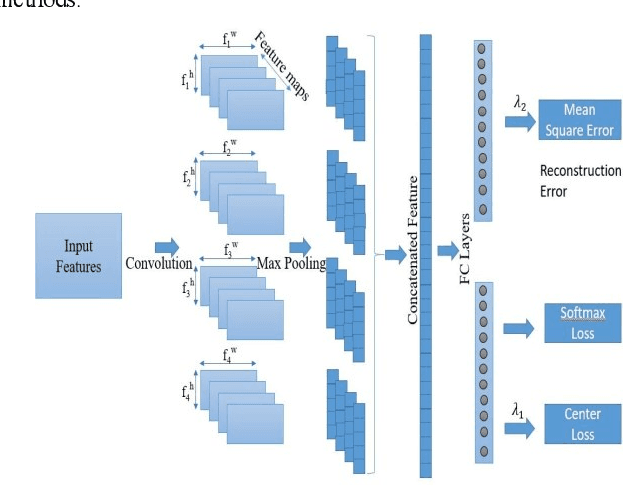
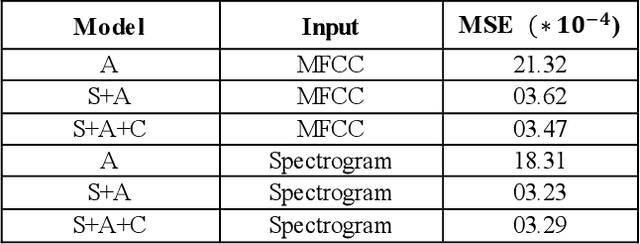
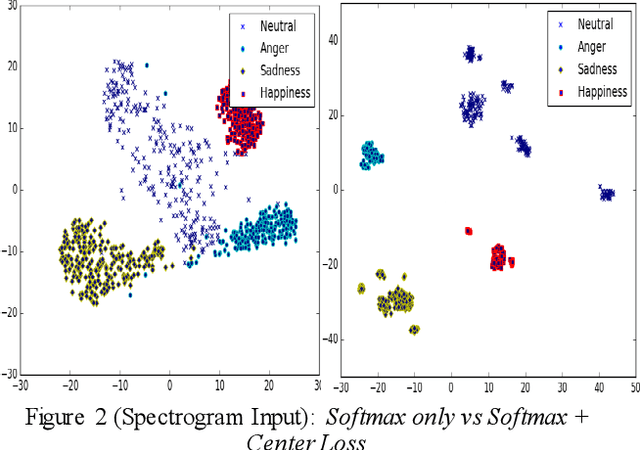
This paper proposes a Convolutional Neural Network (CNN) inspired by Multitask Learning (MTL) and based on speech features trained under the joint supervision of softmax loss and center loss, a powerful metric learning strategy, for the recognition of emotion in speech. Speech features such as Spectrograms and Mel-frequency Cepstral Coefficient s (MFCCs) help retain emotion-related low-level characteristics in speech. We experimented with several Deep Neural Network (DNN) architectures that take in speech features as input and trained them under both softmax and center loss, which resulted in highly discriminative features ideal for Speech Emotion Recognition (SER). Our networks also employ a regularizing effect by simultaneously performing the auxiliary task of reconstructing the input speech features. This sharing of representations among related tasks enables our network to better generalize the original task of SER. Some of our proposed networks contain far fewer parameters when compared to state-of-the-art architectures.
Deep Learning based Emotion Recognition System Using Speech Features and Transcriptions
Jun 11, 2019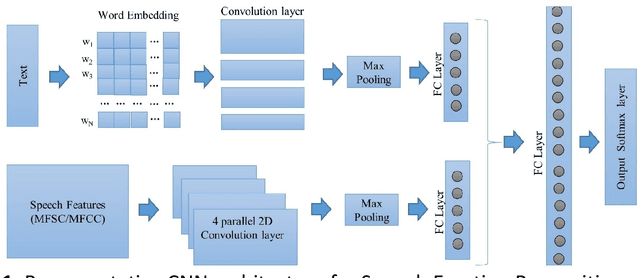
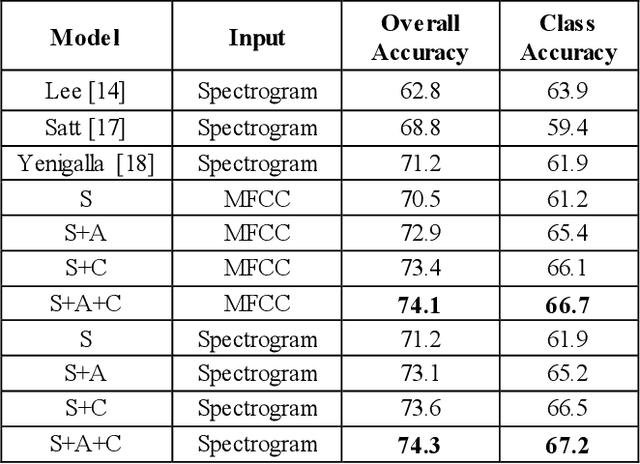
This paper proposes a speech emotion recognition method based on speech features and speech transcriptions (text). Speech features such as Spectrogram and Mel-frequency Cepstral Coefficients (MFCC) help retain emotion-related low-level characteristics in speech whereas text helps capture semantic meaning, both of which help in different aspects of emotion detection. We experimented with several Deep Neural Network (DNN) architectures, which take in different combinations of speech features and text as inputs. The proposed network architectures achieve higher accuracies when compared to state-of-the-art methods on a benchmark dataset. The combined MFCC-Text Convolutional Neural Network (CNN) model proved to be the most accurate in recognizing emotions in IEMOCAP data.
Focal Loss based Residual Convolutional Neural Network for Speech Emotion Recognition
Jun 11, 2019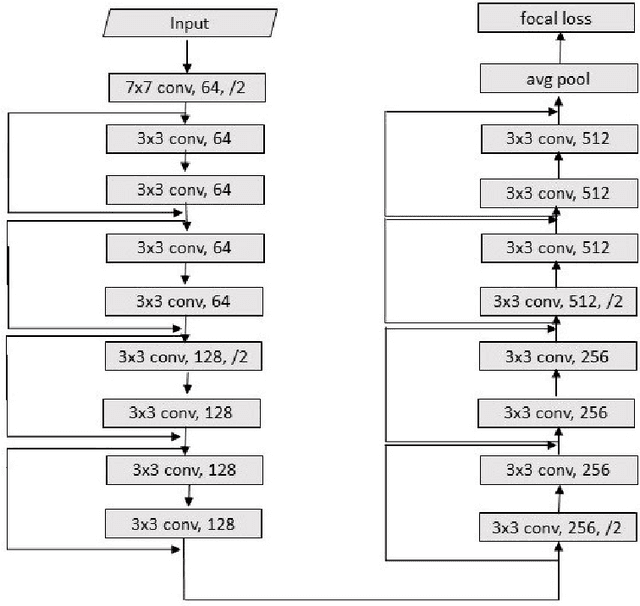
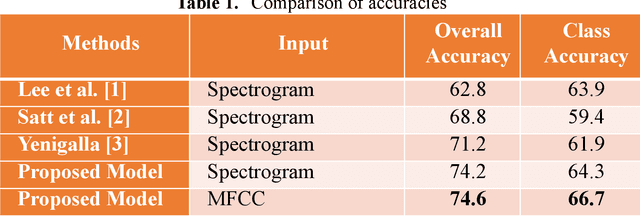
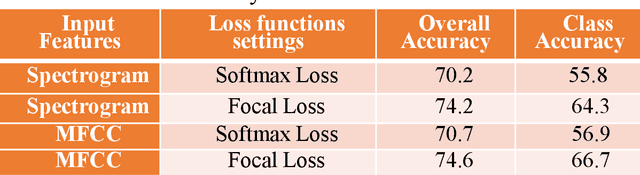
This paper proposes a Residual Convolutional Neural Network (ResNet) based on speech features and trained under Focal Loss to recognize emotion in speech. Speech features such as Spectrogram and Mel-frequency Cepstral Coefficients (MFCCs) have shown the ability to characterize emotion better than just plain text. Further Focal Loss, first used in One-Stage Object Detectors, has shown the ability to focus the training process more towards hard-examples and down-weight the loss assigned to well-classified examples, thus preventing the model from being overwhelmed by easily classifiable examples.
A Practitioners' Guide to Transfer Learning for Text Classification using Convolutional Neural Networks
Jan 19, 2018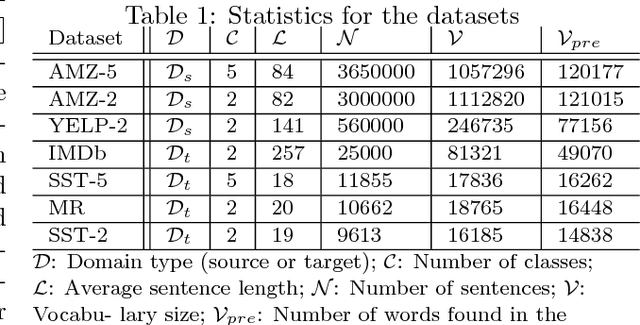
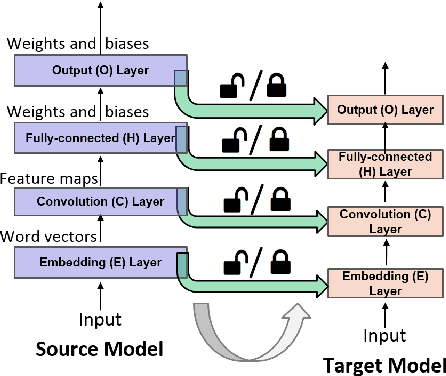
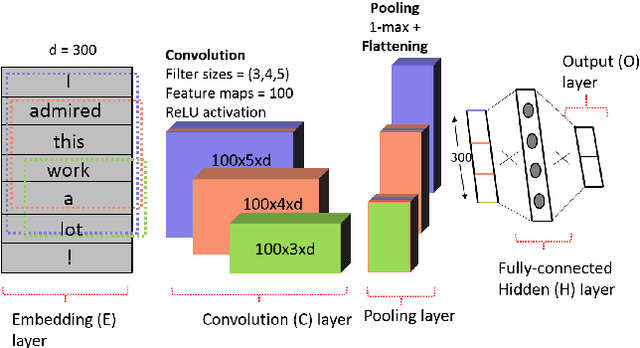
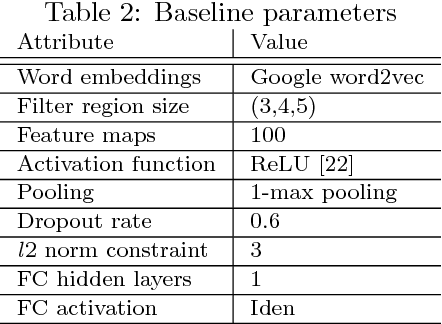
Transfer Learning (TL) plays a crucial role when a given dataset has insufficient labeled examples to train an accurate model. In such scenarios, the knowledge accumulated within a model pre-trained on a source dataset can be transferred to a target dataset, resulting in the improvement of the target model. Though TL is found to be successful in the realm of image-based applications, its impact and practical use in Natural Language Processing (NLP) applications is still a subject of research. Due to their hierarchical architecture, Deep Neural Networks (DNN) provide flexibility and customization in adjusting their parameters and depth of layers, thereby forming an apt area for exploiting the use of TL. In this paper, we report the results and conclusions obtained from extensive empirical experiments using a Convolutional Neural Network (CNN) and try to uncover thumb rules to ensure a successful positive transfer. In addition, we also highlight the flawed means that could lead to a negative transfer. We explore the transferability of various layers and describe the effect of varying hyper-parameters on the transfer performance. Also, we present a comparison of accuracy value and model size against state-of-the-art methods. Finally, we derive inferences from the empirical results and provide best practices to achieve a successful positive transfer.