 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Intent and Slot Prediction using MLB Fusion
Mar 20, 2020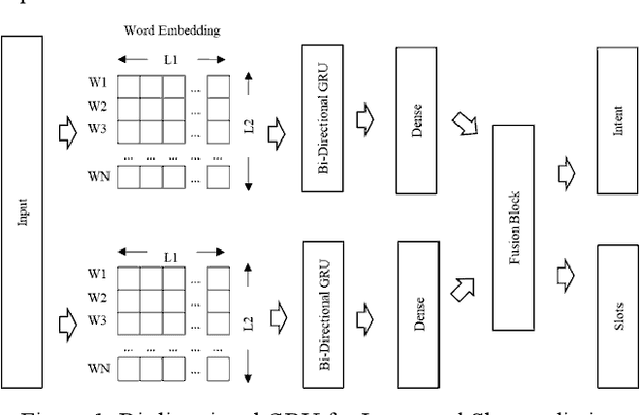
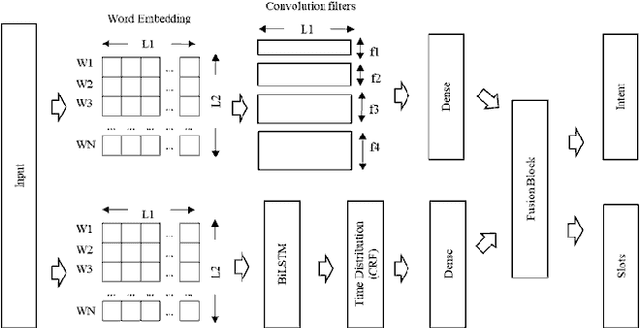
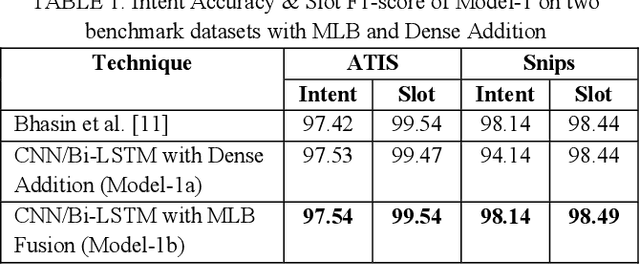
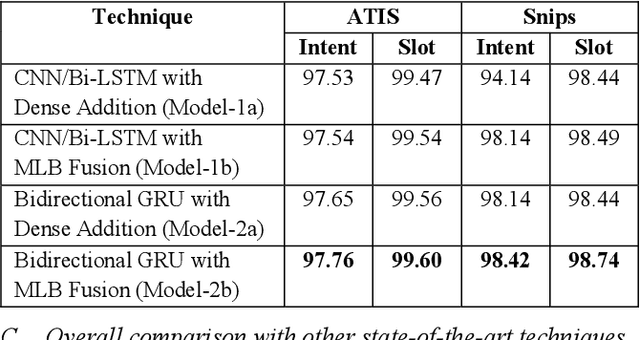
Intent and Slot Identification are two important tasks in Spoken Language Understanding (SLU). For a natural language utterance, there is a high correlation between these two tasks. A lot of work has been done on each of these using Recurrent-Neural-Networks (RNN), Convolution Neural Networks (CNN) and Attention based models. Most of the past work used two separate models for intent and slot prediction. Some of them also used sequence-to-sequence type models where slots are predicted after evaluating the utterance-level intent. In this work, we propose a parallel Intent and Slot Prediction technique where separate Bidirectional Gated Recurrent Units (GRU) are used for each task. We posit the usage of MLB (Multimodal Low-rank Bilinear Attention Network) fusion for improvement in performance of intent and slot learning. To the best of our knowledge, this is the first attempt of using such a technique on text based problems. Also, our proposed methods outperform the existing state-of-the-art results for both intent and slot prediction on two benchmark datasets
A Practitioners' Guide to Transfer Learning for Text Classification using Convolutional Neural Networks
Jan 19, 2018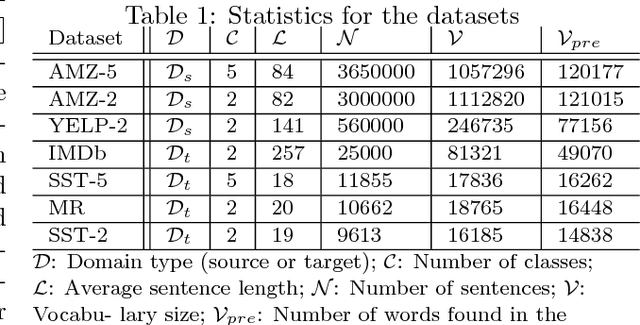
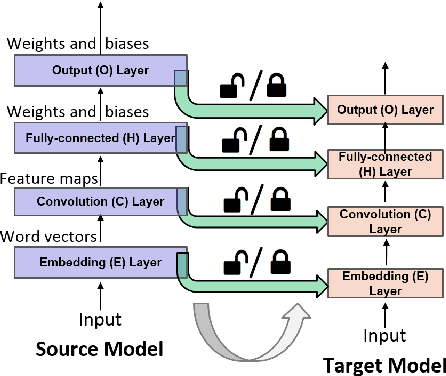
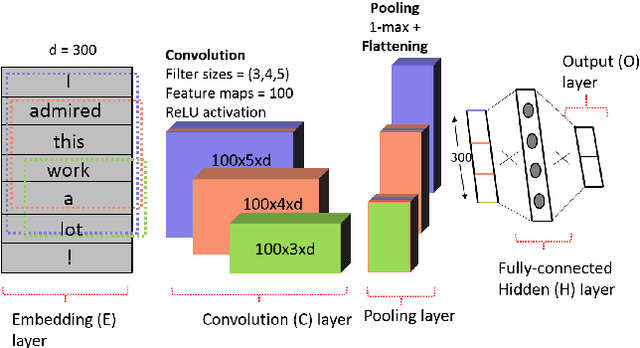
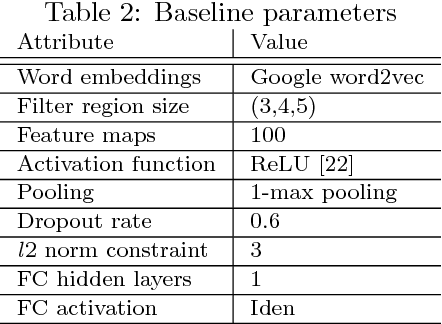
Transfer Learning (TL) plays a crucial role when a given dataset has insufficient labeled examples to train an accurate model. In such scenarios, the knowledge accumulated within a model pre-trained on a source dataset can be transferred to a target dataset, resulting in the improvement of the target model. Though TL is found to be successful in the realm of image-based applications, its impact and practical use in Natural Language Processing (NLP) applications is still a subject of research. Due to their hierarchical architecture, Deep Neural Networks (DNN) provide flexibility and customization in adjusting their parameters and depth of layers, thereby forming an apt area for exploiting the use of TL. In this paper, we report the results and conclusions obtained from extensive empirical experiments using a Convolutional Neural Network (CNN) and try to uncover thumb rules to ensure a successful positive transfer. In addition, we also highlight the flawed means that could lead to a negative transfer. We explore the transferability of various layers and describe the effect of varying hyper-parameters on the transfer performance. Also, we present a comparison of accuracy value and model size against state-of-the-art methods. Finally, we derive inferences from the empirical results and provide best practices to achieve a successful positive transfer.